This AI Paper Proposes Two Types of Convolution, Pixel Difference Convolution (PDC) and Binary Pixel Difference Convolution (Bi-PDC), to Enhance the Representation Capacity of Convolutional Neural Network CNNs
Deep convolutional neural networks (DCNNs) have been a game-changer for several computer vision tasks. These include object identification, object recognition, image segmentation, and edge detection. The ever-growing size and power consumption of DNNs have been key to enabling much of this advancement. Embedded, wearable, and Internet of Things (IoT) devices, which have restricted computing resources and low power, as well as drones, pose significant challenges to sustainability, environmental friendliness, and broad economic viability because of their computationally expensive DNNs despite their high accuracy. As a result, many people are interested in finding ways to maximize the energy efficiency of DNNs through algorithm and hardware optimization.
Model quantization, efficient neural architecture search, compact network design, knowledge distillation, and tensor decomposition are among the most popular DNN compression and acceleration approaches.
Researchers from the University of Oulu, the National University of Defense Technology, the Chinese Academy of Sciences, and the Aviation University of Air Force aim to improve DCNN efficiency by delving into the inner workings of deep features. Network depth and convolution are the two primary components of a DCNN that determine its expressive power. In the first case, a deep convolutional neural network (DCNN) learns a series of hierarchical representations that map to higher abstraction levels. The second method is known as convolution, and it involves exploring image patterns with local operators that are translation invariant. This is similar to how local descriptors are extracted in conventional frameworks for shallow image representation. Although Local Binary Patterns (LBP), Histogram of Oriented Gradients (HOG), and Sorted Random Projections (SRPs) are well-known for their discriminative power and robustness in describing fine-grained image information, the conventional shallow BoW pipeline may restrict their use. But in contrast, DCNNs’ traditional convolutional layer merely records pixel intensity cues, leaving out important information about the image’s microstructure, such as higher-order local gradients.
The researchers wanted to explore how to merge conventional local descriptors with DCNNs for the greatest of all worlds. They found that such higher-order local differential information, which is overlooked by conventional convolution, can effectively capture microtexture information and was already effective before deep learning; consequently, they believe that this area deserves more attention and should be investigated in the future.
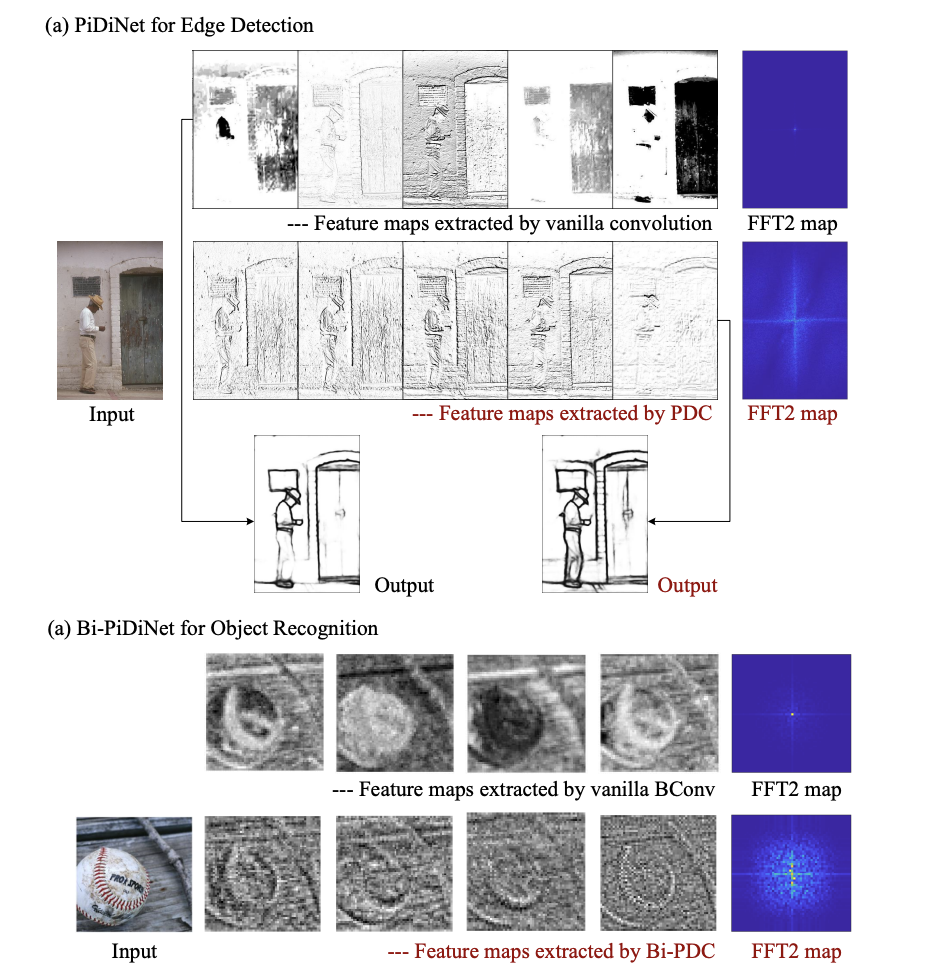
Their recent work provides two convolutional layers, PDC and Bi-PDC, which can augment vanilla convolution by capturing higher-order local differential information. They work well with preexisting DCNNs and are computationally efficient. They want to improve the commonly used CNN architectures for vision applications by creating a generic convolution operation called PDC. The LBP mechanism is incorporated into the basic convolution operations in their PDC design so that filters can probe local pixel differences instead of pixel intensities. To extract rich higher-order feature statistics from distinct encoding orientations, they build three PDC instances—Central PDC, Angular PDC, and Radial PDC—using different LBP probing algorithms.
There are three notable characteristics of PDC in general.
- Feature maps are enhanced in diversity because they can generate features with high-order information that complement features produced by vanilla convolutions.
- In addition, it is completely differentiable and can be easily integrated into any network design for comprehensive optimization.
- Users can improve efficiency by using it with other network acceleration techniques, such as network binarization.
They create a new small DCNN architecture called Pixel Difference Network (PiDiNet) to do the edge detection job using the suggested PDC. As mentioned in their paper, PiDiNet is the first deep network to perform at a human level on the widely used BSDS500 dataset without requiring ImageNet pretraining.
To show that their method works for both low-level tasks (like edge detection) and high-level ones (like image classification and facial recognition), they construct two very efficient DCNN architectures using PDC and Bi-PDC, called Binary Pixel Difference Networks (Bi-PiDiNet) that can combine Bi-PDC with vanilla binary convolution in a flexible way. This architecture can efficiently recognize objects in images by capturing zeroth-order and higher-order local picture information. Miniaturized and, more precisely, Bi-PiDiNet is the result of careful design.
The proposed PiDiNet and Bi-PiDiNet outperform the state-of-the-art in terms of efficiency and accuracy in extensive experimental evaluations conducted on widely used datasets for edge detection, image classification, and facial recognition. PiDiNet and Bi-PiDiNet are new proposals that could improve the efficiency of edge vision tasks by using lightweight deep models.
The researchers keep much room for future research on PDC and Bi-PDC. Microstructurally, several pattern probing methodologies can be explored to produce (Bi-)PDC instances for specific tasks. Looking at the big picture, establishing numerous (Bi-)PDC instances optimally can improve a network. They anticipate that numerous semantically low- and high-level computer vision (CV) tasks, such as object detection, salient object detection, face behavior analysis, etc., will benefit from the suggested (Bi-)PDC due to its capacity to capture high-order information.
Check out the Paper and Github. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 36k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
![]()
Dhanshree Shenwai is a Computer Science Engineer and has a good experience in FinTech companies covering Financial, Cards & Payments and Banking domain with keen interest in applications of AI. She is enthusiastic about exploring new technologies and advancements in today’s evolving world making everyone’s life easy.
Credit: Source link
Comments are closed.