HD-Painter: High Resolution Text-Guided Image Inpainting with Diffusion Models

Diffusion models have undoubtedly revolutionized the AI and ML industry, with their applications in real-time becoming an integral part of our everyday lives. After text-to-image models showcased their remarkable abilities, diffusion-based image manipulation techniques, such as controllable generation, specialized and personalized image synthesis, object-level image editing, prompt-conditioned variations, and editing, emerged as hot research topics due to their applications in the computer vision industry.
However, despite their impressive capabilities and exceptional results, text-to-image frameworks, particularly text-to-image inpainting frameworks, still have potential areas for development. These include the ability to understand global scenes, especially when denoising the image in high diffusion timesteps. Addressing this issue, researchers introduced HD-Painter, a completely training-free framework that accurately follows prompt instructions and scales to high-resolution image inpainting coherently. The HD-Painter framework employs a Prompt Aware Introverted Attention (PAIntA) layer, which leverages prompt information to enhance self-attention scores, resulting in better text alignment generation.
To further improve the coherence of the prompt, the HD-Painter model introduces a Reweighting Attention Score Guidance (RASG) approach. This approach integrates a post-hoc sampling strategy into the general form of the DDIM component seamlessly, preventing out-of-distribution latent shifts. Additionally, the HD-Painter framework features a specialized super-resolution technique customized for inpainting, allowing it to extend to larger scales and complete missing regions in the image with resolutions up to 2K.
HD-Painter: Text-Guided Image Inpainting
Text-to-image diffusion models have indeed been a significant topic in the AI and ML industry in recent months, with models demonstrating impressive real-time capabilities across various practical applications. Pre-trained text-to-image generation models like DALL-E, Imagen, and Stable Diffusion have shown their suitability for image completion by merging denoised (generated) unknown regions with diffused known regions during the backward diffusion process. Despite producing visually appealing and well-harmonized outputs, existing models struggle to understand the global scene, particularly under the high diffusion timestep denoising process. By modifying pre-trained text-to-image diffusion models to incorporate additional context information, they can be fine-tuned for text-guided image completion.
Furthermore, within diffusion models, text-guided inpainting and text-guided image completion are major areas of interest for researchers. This interest is driven by the fact that text-guided inpainting models can generate content in specific regions of an input image based on textual prompts, leading to potential applications such as retouching specific image regions, modifying subject attributes like colors or clothes, and adding or replacing objects. In summary, text-to-image diffusion models have recently achieved unprecedented success, due to their exceptionally realistic and visually appealing generation capabilities.

However, a majority of existing frameworks demonstrate prompt neglection in two scenarios. The first is Background Dominance when the model completes the unknown region by ignoring the prompt in the background whereas the second scenario is nearby object dominance when the model propagates the known region objects to the unknown region using visual context likelihood rather than the input prompt. It is a possibility that both these issues might be a result of vanilla inpainting diffusion’s ability to interpret the textual prompt accurately or mix it with the contextual information obtained from the known region.
To tackle these roadblocks, the HD-Painter framework introduces the Prompt Aware Introverted Attention or PAIntA layer, that uses prompt information to enhance the self-attention scores that ultimately results in better text alignment generation. PAIntA uses the given textual conditioning to enhance the self attention score with the aim to reduce the impact of non-prompt relevant information from the image region while at the same time increasing the contribution of the known pixels aligned with the prompt. To further enhance the text-alignment of the generated results, the HD-Painter framework implements a post-hoc guidance method that leverages the cross-attention scores. However, the implementation of the vanilla post-hoc guidance mechanism might cause out of distribution shifts as a result of the additional gradient term in the diffusion equation. The out of distribution shift will ultimately result in quality degradation of the generated output. To tackle this roadblock, the HD-Painter framework implements a Reweighting Attention Score Guidance or RASG, a method that integrates a post-hoc sampling strategy into the general form of the DDIM component seamlessly. It allows the framework to generate visually plausible inpainting results by guiding the sample towards the prompt-aligned latents, and contain them in their trained domain.
By deploying both the RASH and PAIntA components in its architecture, the HD-Painter framework holds a significant advantage over existing, including state of the art, inpainting, and text to image diffusion models because it manages to solve the existing issue of prompt neglection. Furthermore, both the RASH and the PAIntA components offer plug and play functionality, allowing them to be compatible with diffusion base inpainting models to tackle the challenges mentioned above. Furthermore, by implementing a time-iterative blending technology and by leveraging the capabilities of high-resolution diffusion models, the HD-Painter pipeline can operate effectively for up to 2K resolution inpainting.
To sum it up, the HD-Painter aims to make the following contributions in the field:
- It aims to resolve the prompt neglect issue of the background and nearby object dominance experienced by text-guided image inpainting frameworks by implementing the Prompt Aware Introverted Attention or PAIntA layer in its architecture.
- It aims to improve the text-alignment of the output by implementing the Reweighting Attention Score Guidance or RASG layer in its architecture that enables the HD-Painter framework to perform post-hoc guided sampling while preventing out of shift distributions.
- To design an effective training-free text-guided image completion pipeline capable of outperforming the existing state of the art frameworks, and using the simple yet effective inpainting-specialized super-resolution framework to perform text-guided image inpainting up to 2K resolution.
HD-Painter: Method and Architecture
Before we have a look at the architecture, it is vital to understand the three fundamental concepts that form the foundation of the HD-Painter framework: Image Inpainting, Post-Hoc Guidance in Diffusion Frameworks, and Inpainting Specific Architectural Blocks.
Image Inpainting is an approach that aims to fill the missing regions within an image while ensuring the visual appeal of the generated image. Traditional deep learning frameworks implemented methods that used known regions to propagate deep features. However, the introduction of diffusion models has resulted in the evolution of inpainting models, especially the text-guided image inpainting frameworks. Traditionally, a pre-trained text to image diffusion model replaces the unmasked region of the latent by using the noised version of the known region during the sampling process. Although this approach works to an extent, it degrades the quality of the generated output significantly since the denoising network only sees the noised version of the known region. To tackle this hurdle, a few approaches aimed to fine-tune the pre-trained text to image model to achieve text-guided image inpainting. By implementing this approach, the framework is able to generate a random mask via concatenation since the model is able to condition the denoising framework on the unmasked region.
Moving along, the traditional deep learning models implemented special design layers for efficient inpainting with some frameworks being able to extract information effectively and produce visually appealing images by introducing special convolution layers to deal with the known regions of the image. Some frameworks even added a contextual attention layer in their architecture to reduce the unwanted heavy computational requirements of all to all self attention for high quality inpainting.
Finally, the Post-hoc guidance methods are backward diffusion sampling methods that guide the next step latent prediction towards a particular function minimization objective. Post-hoc guidance methods are of great help when it comes to generating visual content especially in the presence of additional constraints. However, the Post-hoc guidance methods have a major drawback: they are known to result in image quality degradations since they tend to shift the latent generation process by a gradient term.
Coming to the architecture of HD-Painter, the framework first formulates the text-guided image completion problem, and then introduces two diffusion models namely the Stable Inpainting and Stable Diffusion. The HD-Painter model then introduces the PAIntA and the RASG blocks, and finally we arrive at the inpainting-specific super resolution technique.
Stable Diffusion and Stable Inpainting
Stable Diffusion is a diffusion model that operates within the latent space of an autoencoder. For text to image synthesis, the Stable Diffusion framework implements a textual prompt to guide the process. The guiding function has a structure similar to the UNet architecture, and the cross-attention layers condition it on the textual prompts. Furthermore, the Stable Diffusion model can perform image inpainting with some modifications and fine-tuning. To achieve so, the features of the masked image generated by the encoder is concatenated with the downscaled binary mask to the latents. The resulting tensor is then input into the UNet architecture to obtain the estimated noise. The framework then initializes the newly added convolutional filters with zeros while the remainder of the UNet is initialized using pre-trained checkpoints from the Stable Diffusion model.

The above figure demonstrates the overview of the HD-Painter framework consisting of two stages. In the first stage, the HD-Painter framework implements text-guided image painting whereas in the second stage, the model inpaints specific super-resolution of the output. To fill in the mission regions and to remain consistent with the input prompt, the model takes a pre-trained inpainting diffusion model, replaces the self-attention layers with PAIntA layers, and implements the RASG mechanism to perform a backward diffusion process. The model then decodes the final estimated latent resulting in an inpainted image. HD-Painter then implements the super stable diffusion model to inpaint the original size image, and implements the diffusion backward process of the Stable Diffusion framework conditioned on the low resolution input image. The model blends the denoised predictions with the original image’s encoding after each step in the known region and derives the next latent. Finally, the model decodes the latent and implements Poisson blending to avoid edge artifacts.
Prompt Aware Introverted Attention or PAIntA
Existing inpainting models like Stable Inpainting tend to rely more on the visual context around the inpainting area and ignore the input user prompts. On the basis of the user experience, this issue can be categorized into two classes: nearby object dominance and background dominance. The issue of visual context dominance over the input prompts might be a result of the only-spatial and prompt-free nature of the self-attention layers. To tackle this issue, the HD-Painter framework introduces the Prompt Aware Introverted Attention or PAIntA that uses cross-attention matrices and an inpainting mask to control the output of the self-attention layers in the unknown region.
The Prompt Aware Introverted Attention component first applies projection layers to get the key, values, and queries along with the similarity matrix. The model then adjusts the attention score of the known pixels to mitigate the strong influence of the known region over the unknown region, and defines a new similarity matrix by leveraging the textual prompt.

Reweighting Attention Score Guidance or RASG
The HD-Painter framework adopts a post-hoc sampling guidance method to enhance the generation alignment with the textual prompts even further. Along with an objective function, the post-hoc sampling guidance approach aims to leverage the open-vocabulary segmentation properties of the cross-attention layers. However, this approach of vanilla post-hoc guidance has the potential to shift the domain of diffusion latent that might degrade the quality of the generated image. To tackle this issue, the HD-Painter model implements the Reweighting Attention Score Guidance or RASG mechanism that introduces a gradient reweighting mechanism resulting in latent domain preservation.
HD-Painter : Experiments and Results
To analyze its performance, the HD-Painter framework is compared against current state of the art models including Stable Inpainting, GLIDE, and BLD or Blended Latent Diffusion over 10000 random samples where the prompt is selected as the label of the selected instance mask.
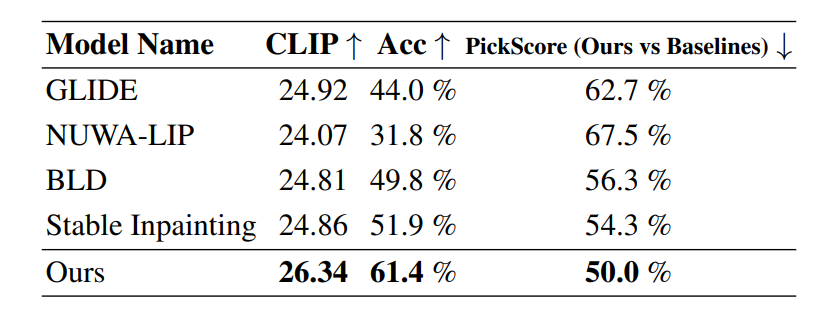
As it can be observed, the HD-Painter framework outperforms existing frameworks on three different metrics by a significant margin, especially the improvement of 1.5 points on the CLIP metric and difference in generated accuracy score of about 10% from other state of the art methods.

Moving along, the following figure demonstrates the qualitative comparison of the HD-Painter framework with other inpainting frameworks. As it can be observed, other baseline models either reconstruct the missing regions in the image as a continuation of the known region objects disregarding the prompts or they generate a background. On the other hand, the HD-Painter framework is able to generate the target objects successfully owing to the implementation of the PAIntA and the RASG components in its architecture.

Final Thoughts
In this article, we have talked about HD-Painter, a training free text guided high-resolution inpainting approach that addresses the challenges experienced by existing inpainting frameworks including prompt neglection, and nearby and background object dominance. The HD-Painter framework implements a Prompt Aware Introverted Attention or PAIntA layer, that uses prompt information to enhance the self-attention scores that ultimately results in better text alignment generation.
To improve the coherence of the prompt even further, the HD-Painter model introduces a Reweighting Attention Score Guidance or RASG approach that integrates a post-hoc sampling strategy into the general form of the DDIM component seamlessly to prevent out of distribution latent shifts. Furthermore, the HD-Painter framework introduces a specialized super-resolution technique customized for inpainting that results in extension to larger scales, and allows the HD-Painter framework to complete the missing regions in the image with resolution up to 2K.


Credit: Source link
Comments are closed.