Meet Hawkeye: A Unified Deep Learning-based Fine-Grained Image Recognition Toolbox Built on PyTorch
In recent years, notable advancements in the design and training of deep learning models have led to significant improvements in image recognition performance, particularly on large-scale datasets. Fine-Grained Image Recognition (FGIR) represents a specialized domain focusing on the detailed recognition of subcategories within broader semantic categories. Despite the progress facilitated by deep learning, FGIR remains a formidable challenge, with wide-ranging applications in smart cities, public safety, ecological protection, and agricultural production.
The primary hurdle in FGIR revolves around discerning subtle visual disparities crucial for distinguishing objects with highly similar overall appearances but varying fine-grained features. Existing FGIR methods can generally be categorized into three paradigms: recognition by localization-classification subnetworks, recognition by end-to-end feature encoding, and recognition with external information.
While some methods from these paradigms have been made available as open-source, a unified open-needs-to-be library currently lacks. This absence poses a significant obstacle for new researchers entering the field, as different methods often rely on disparate deep-learning frameworks and architectural designs, necessitating a steep learning curve for each. Moreover, the absence of a unified library often compels researchers to develop their code from scratch, leading to redundant efforts and less reproducible results due to variations in frameworks and setups.
To tackle this, researchers at the Nanjing University of Science and Technology introduce Hawkeye, a PyTorch-based library for Fine-Grained Image Recognition (FGIR) built upon a modular architecture, prioritizing high-quality code and human-readable configuration. With its deep learning capabilities, Hawkeye offers a comprehensive solution tailored specifically for FGIR tasks.
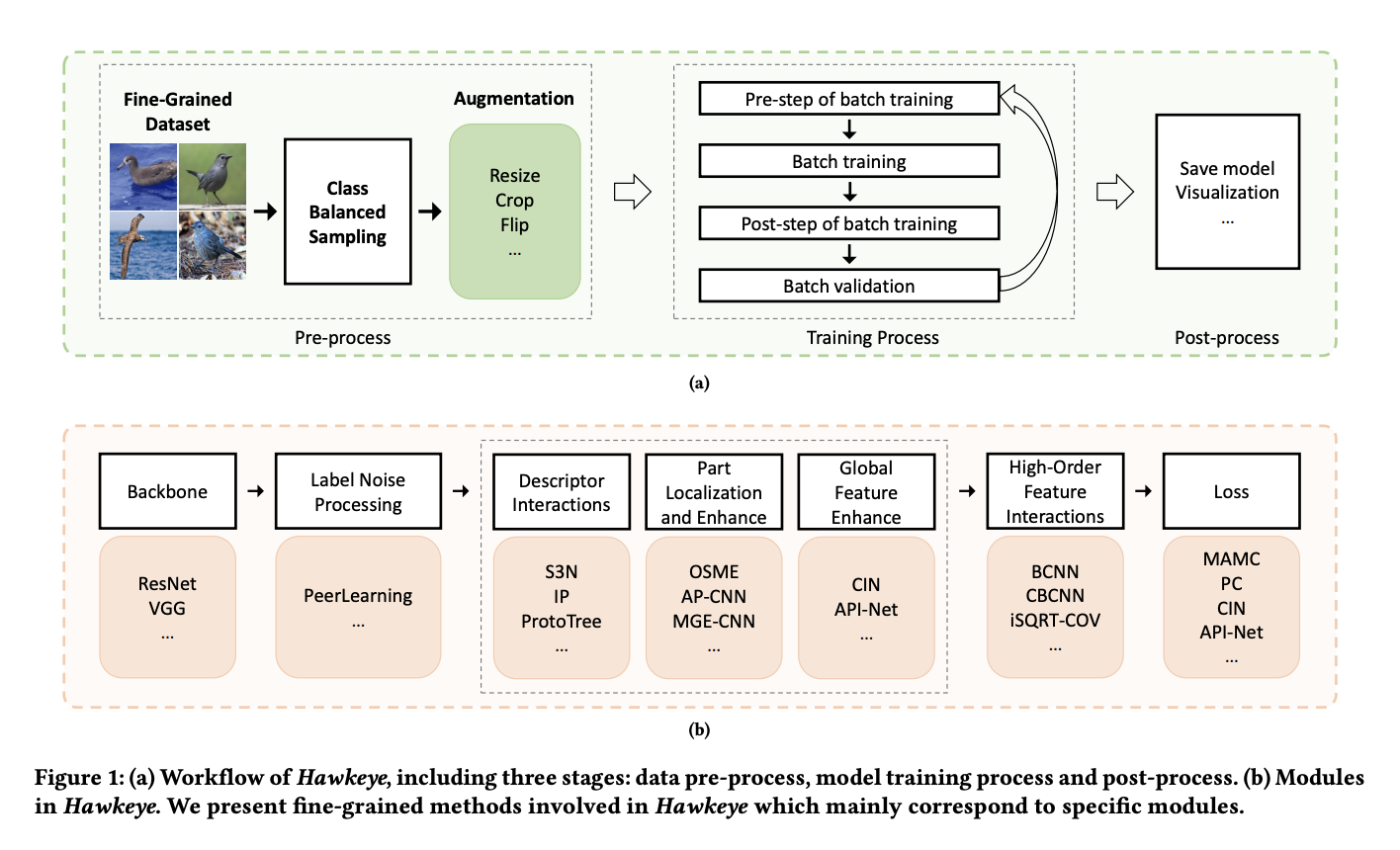
Hawkeye encompasses 16 representative methods spanning six paradigms in FGIR, providing researchers with a holistic understanding of current state-of-the-art techniques. Its modular design facilitates easy integration of custom methods or enhancements, enabling fair comparisons with existing approaches. The FGIR training pipeline in Hawkeye is structured into multiple modules integrated within a unified pipeline. Users can override specific modules, ensuring flexibility and customization while minimizing code modifications.
Emphasizing code readability, Hawkeye simplifies each module within the pipeline to enhance comprehensibility. This approach aids beginners in quickly grasping the training process and the functions of each component.
Hawkeye provides YAML configuration files for each method, allowing users to conveniently modify hyperparameters related to the dataset, model, optimizer, etc. This streamlined approach enables users to efficiently tailor experiments to their specific requirements.
Check out the Paper and Github. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 36k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
![]()
Arshad is an intern at MarktechPost. He is currently pursuing his Int. MSc Physics from the Indian Institute of Technology Kharagpur. Understanding things to the fundamental level leads to new discoveries which lead to advancement in technology. He is passionate about understanding the nature fundamentally with the help of tools like mathematical models, ML models and AI.
Credit: Source link
Comments are closed.