This AI Paper Proposes LongAlign: A Recipe of the Instruction Data, Training, and Evaluation for Long Context Alignment
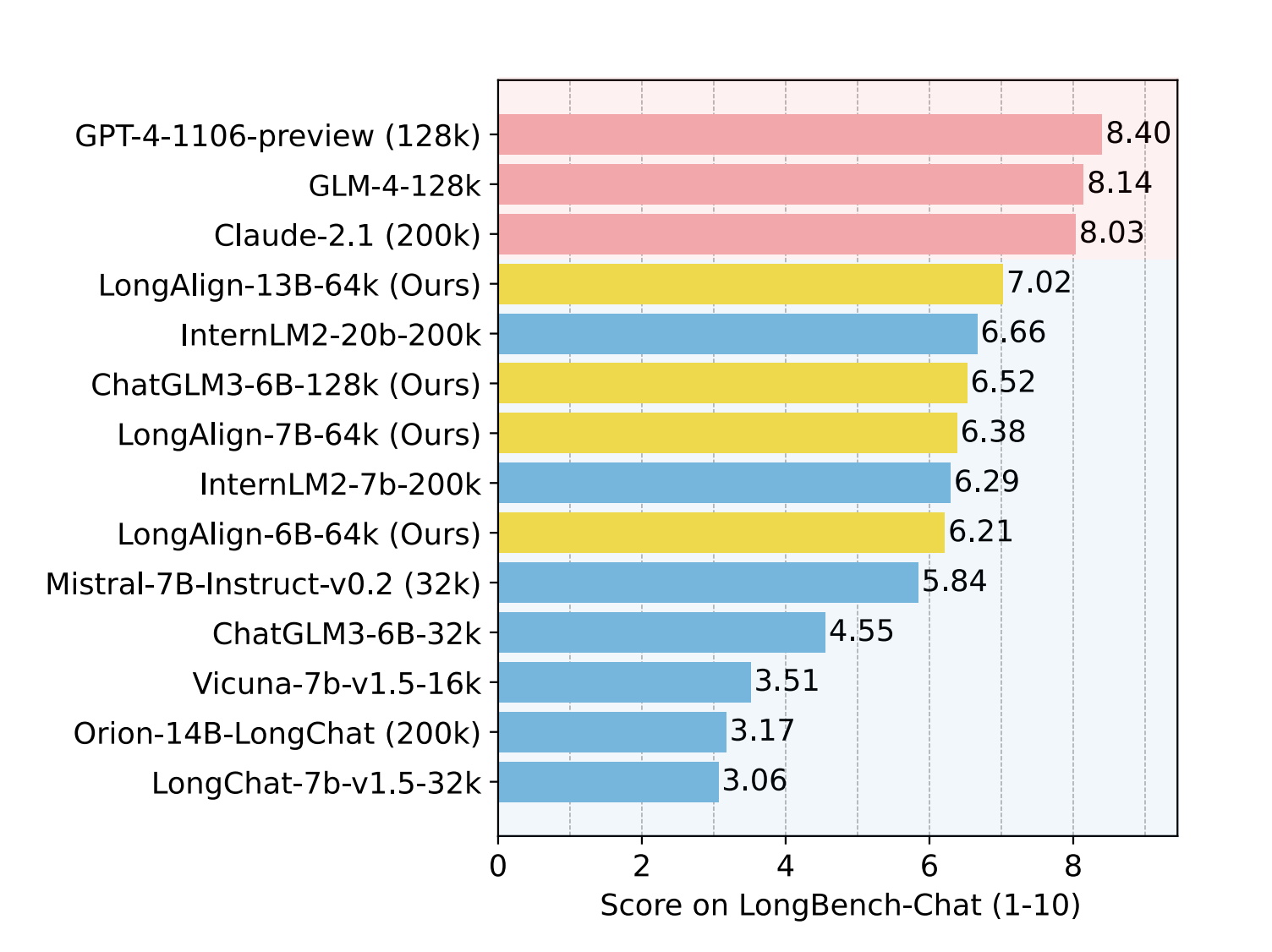
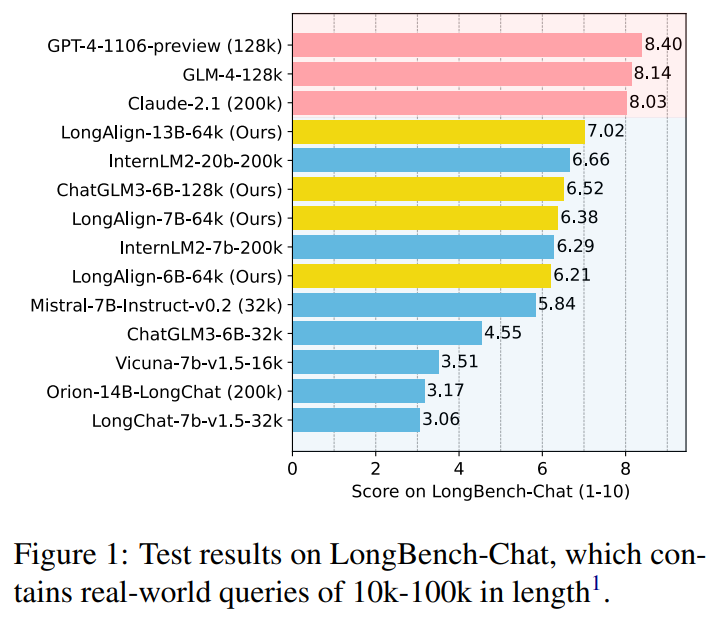
The study diverges from previous approaches by concentrating on aligning long context, specifically by fine-tuning language models to interpret lengthy user prompts. Challenges include the absence of extensive datasets for supervised fine-tuning, difficulties in handling varied length distributions efficiently across multiple GPUs, and the necessity for robust benchmarks to assess the models’ capabilities with real-world queries. The aim is to enhance LLMs’ ability to handle extended contexts by fine-tuning them based on similar input sequence lengths.
Researchers from Tsinghua University and Zhipu.AI have developed LongAlign, a comprehensive approach for aligning LLMs to handle long contexts effectively. They construct a diverse, long instruction-following dataset using Self-Instruct, covering tasks from various sources. To address training inefficiencies due to varied length distributions, they employ packing and sorted batching strategies and a loss weighting method to balance contributions. They also introduce LongBench-Chat, an evaluation benchmark comprising open-ended questions of 10k-100k length.
Long-context scaling seeks to extend the context length of existing LLMs for handling long-context tasks. Methods fall into two categories: those requiring fine-tuning on longer sequences and those that don’t. Non-fine-tuning methods use sliding window attention or token compression techniques but don’t match fine-tuned performance. Fine-tuned approaches involve extending position encoding and continual retraining. Aligning the model with instruction-following data, termed supervised fine-tuning, is crucial for effective interaction in chat interfaces. Challenges include data, training, and evaluation methods. While some work provides long instruction data, it needs more thorough analysis.
The LongAlign recipe offers a comprehensive approach for effectively handling long contexts in LLMs. It involves constructing a diverse long instruction-following dataset using Self-Instruct, adopting efficient training strategies like packing and sorted batching, and introducing the LongBench-Chat benchmark for evaluation. LongAlign addresses challenges by introducing a loss weighting method during packing training, which balances loss contributions across different sequences. Findings show that packing and sorted batching enhance training efficiency twofold while maintaining good performance, and loss weighting significantly improves performance on long instruction tasks during packing training.
Experiments demonstrate that LongAlign improves LLM performance on long-context tasks by up to 30% without compromising proficiency on shorter tasks. Additionally, they find that data quantity and diversity significantly impact performance, while long instruction data enhances long-context task performance without affecting short-context handling. The training strategies accelerate training without compromising performance, with the loss weighting technique further improving long-context performance by 10%. LongAlign achieves improved performance on long instruction tasks through the packing and sorted batching strategies, which double the training efficiency while maintaining good performance.
In conclusion, the study aims to optimize long context alignment, focusing on data, training methods, and evaluation. LongAlign uses Self-Instruct to create diverse long instruction data and fine-tune models efficiently through packing, loss weighting, or sorted batching. The LongBench-Chat benchmark assesses instruction-following ability in practical long-context scenarios. Controlled experiments highlight the significance of data quantity, diversity, and appropriate training methods for achieving optimal performance. LongAlign outperforms existing methods by up to 30% in long context tasks while maintaining proficiency in short tasks. The open sourcing of LongAlign models, code, and data promotes further research and exploration in this field.
Check out the Paper and Github. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 36k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
![]()
Sana Hassan, a consulting intern at Marktechpost and dual-degree student at IIT Madras, is passionate about applying technology and AI to address real-world challenges. With a keen interest in solving practical problems, he brings a fresh perspective to the intersection of AI and real-life solutions.
Credit: Source link
Comments are closed.