Deciphering the Language of Mathematics: The DeepSeekMath Breakthrough in AI-driven Mathematical Reasoning
Mathematical reasoning in artificial intelligence represents a frontier that has long challenged researchers and developers. While effective for specific tasks, traditional computational methods often need to catch up when faced with the intricacies and nuances of complex mathematical problems. This limitation has spurred a quest for more sophisticated solutions, leading to exploring large language models (LLMs) as potential vehicles for advanced mathematical reasoning. The development of these models marks a pivotal shift towards leveraging the vast capabilities of AI to decipher, interpret, and solve mathematical challenges.
At the forefront of this innovation is DeepSeek-AI, Tsinghua University, and Peking University’s DeepSeekMath, a groundbreaking language model specifically engineered to navigate the complexities of mathematical reasoning. Unlike conventional models that rely on a narrow scope of pre-defined algorithms and datasets, DeepSeekMath benefits from a rich and diverse training background. This model’s genesis lies in the strategic compilation of a vast dataset comprising over 120 billion tokens of math-related content from the expansive realms of the internet. This approach broadens the model’s exposure to a wide array of mathematical concepts and enriches its understanding, enabling it to tackle various mathematical problems with unprecedented accuracy.

What sets DeepSeekMath apart is its innovative training methodology, particularly using Group Relative Policy Optimization (GRPO). This variant of reinforcement learning represents a significant leap forward, optimizing the model’s problem-solving capabilities while efficiently managing memory usage. GRPO’s effectiveness is evident in DeepSeekMath’s ability to formulate step-by-step solutions to complex mathematical problems. This feat mirrors human problem-solving processes and surpasses the capabilities of previous models.

The performance and results of the DeepSeekMath model demonstrate superior mathematical reasoning across a range of benchmarks and showcase significant improvements over existing open-source models. Key highlights include:
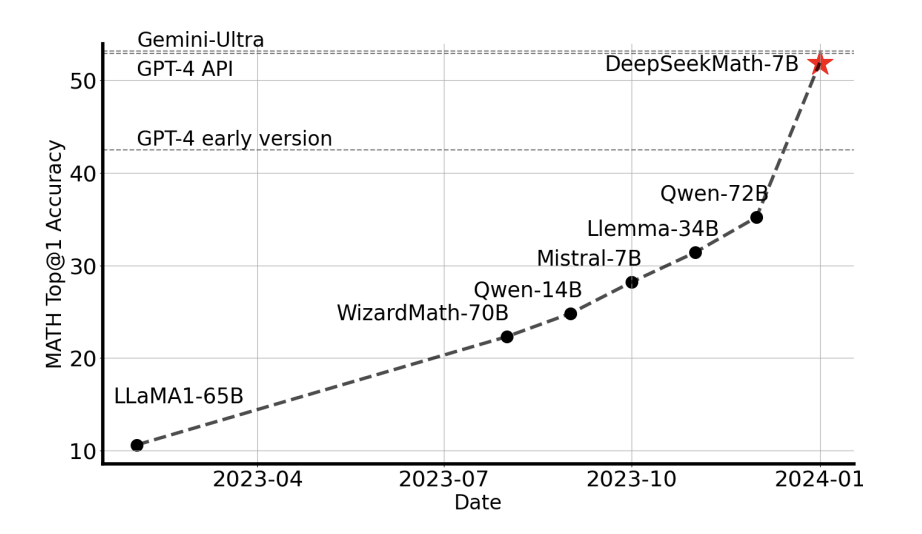
- Achieving a top-1 accuracy of 51.7% on the competitive MATH benchmark is a testament to its advanced reasoning capabilities.
- It exceeded the performance of models many times its size, illustrating that the quality of data and efficiency of learning algorithms can outweigh sheer computational power.
- The successful application of GRPO has proven to enhance performance notably, setting a new standard for the integration of reinforcement learning in the training of language models for mathematical reasoning.

This research not only underscores AI’s potential to revolutionize mathematical reasoning but also opens up new avenues for exploration. The success of DeepSeekMath paves the way for further advancements in AI-driven mathematics, offering promising prospects for educational tools, research assistance, and beyond. The convergence of AI and mathematics through initiatives like DeepSeekMath heralds a future where the boundaries of what machines can understand and solve continue to expand, bridging gaps between computational intelligence and the complex beauty of mathematics.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 36k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
![]()
Hello, My name is Adnan Hassan. I am a consulting intern at Marktechpost and soon to be a management trainee at American Express. I am currently pursuing a dual degree at the Indian Institute of Technology, Kharagpur. I am passionate about technology and want to create new products that make a difference.
Credit: Source link
Comments are closed.