Meta AI Releases V-JEPA: An Artificial Intelligence Method for Teaching Machines to Understand and Model the Physical World by Watching Videos
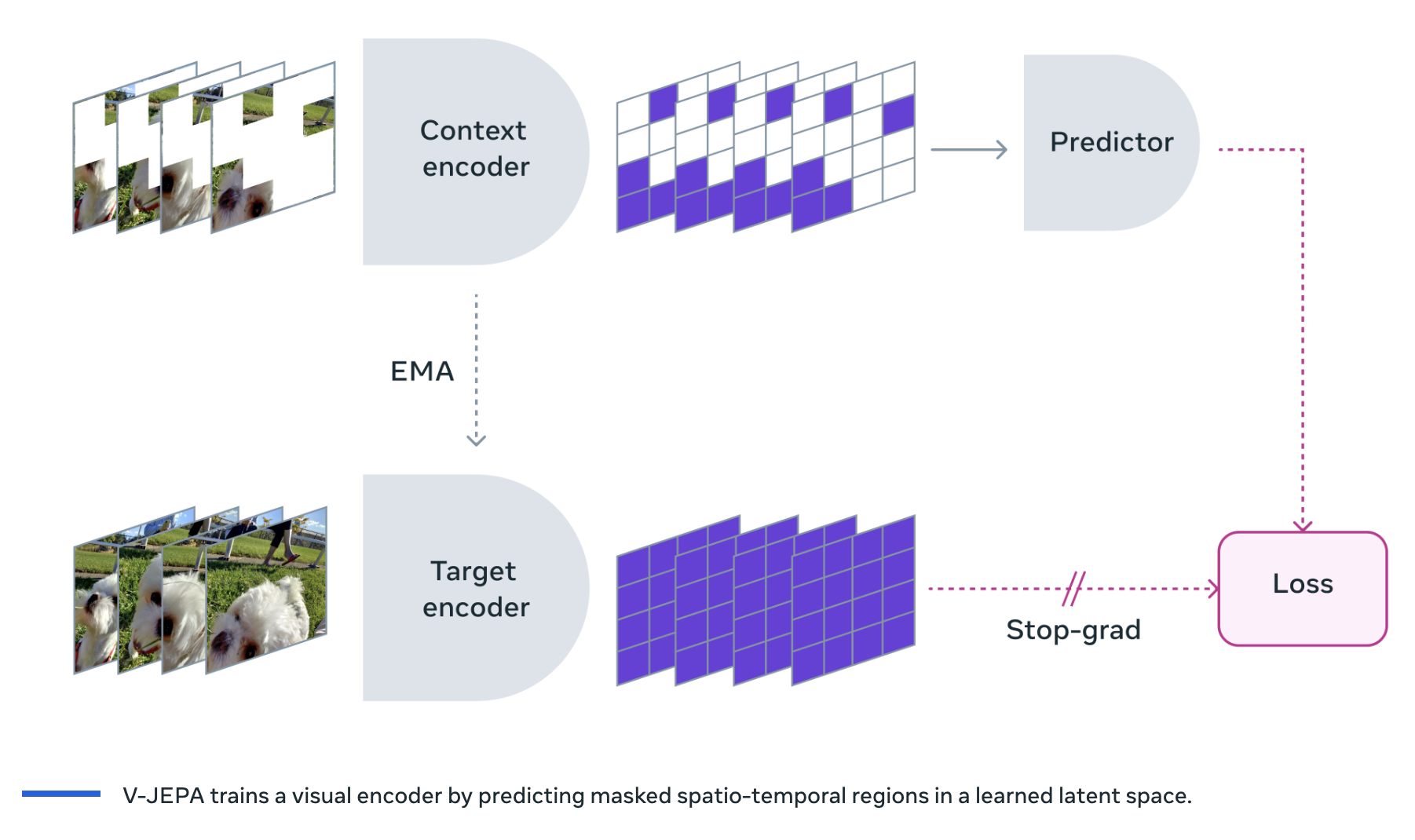
Meta researchers address the challenge of advancing machine intelligence(AMI) in understanding the real world by introducing V-JEPA, a model with joint embedding predictive architecture. It is a non-generative AI model designed to predict masked parts of videos. The model aims to improve the generalized reasoning and planning abilities of AMIs by building machine knowledge from observations that is similar to human learning.
Current video analysis methods often struggle with learning representations from unlabeled data efficiently and adapting to various tasks without extensive retraining. The proposed solution, V-JEPA, is a self-supervising learning model that learns by predicting missing parts of videos in an abstract representation space. Unlike existing models that require full fine-tuning for specific tasks, V-JEPA uses a frozen evaluation approach to enable efficient adaptation to new tasks by training lightweight specialized layers on top of pre-trained encoders and predictors.
V-JEPA uses self-supervised learning to pre-train the unlabeled data, Which enables the model to perform better with labeled examples and increases overall learning of the model to unseen data. V-JEPA develops an understanding of both time and object interactions by using by masking portions of videos in both space and time to predict missing information in an abstract representation space. This methodology enables V-JEPA to excel in fine-grained action recognition tasks and outperform previous video representation learning approaches in frozen evaluation on various downstream tasks, including image classification, action classification, and spatio-temporal action detection. Notably, V-JEPA’s flexibility in discarding unpredictable information leads to improved training and sample efficiency, with efficiency boosts observed on both labeled and unlabeled data.
The proposed model is a state-of-the-art model for video analysis that learns representations from unlabeled data efficiently. It adapts to various downstream tasks without extensive retraining by leveraging self-supervised learning and a frozen evaluation approach. V-JEPA has achieved superior performance in fine-grained action recognition and other video analysis tasks compared to previous methods.
![]()
Pragati Jhunjhunwala is a consulting intern at MarktechPost. She is currently pursuing her B.Tech from the Indian Institute of Technology(IIT), Kharagpur. She is a tech enthusiast and has a keen interest in the scope of software and data science applications. She is always reading about the developments in different field of AI and ML.
Credit: Source link
Comments are closed.