Breaking Barriers in Language Understanding: How Microsoft AI’s LongRoPE Extends Large Language Models to a 2048k Token Context Window
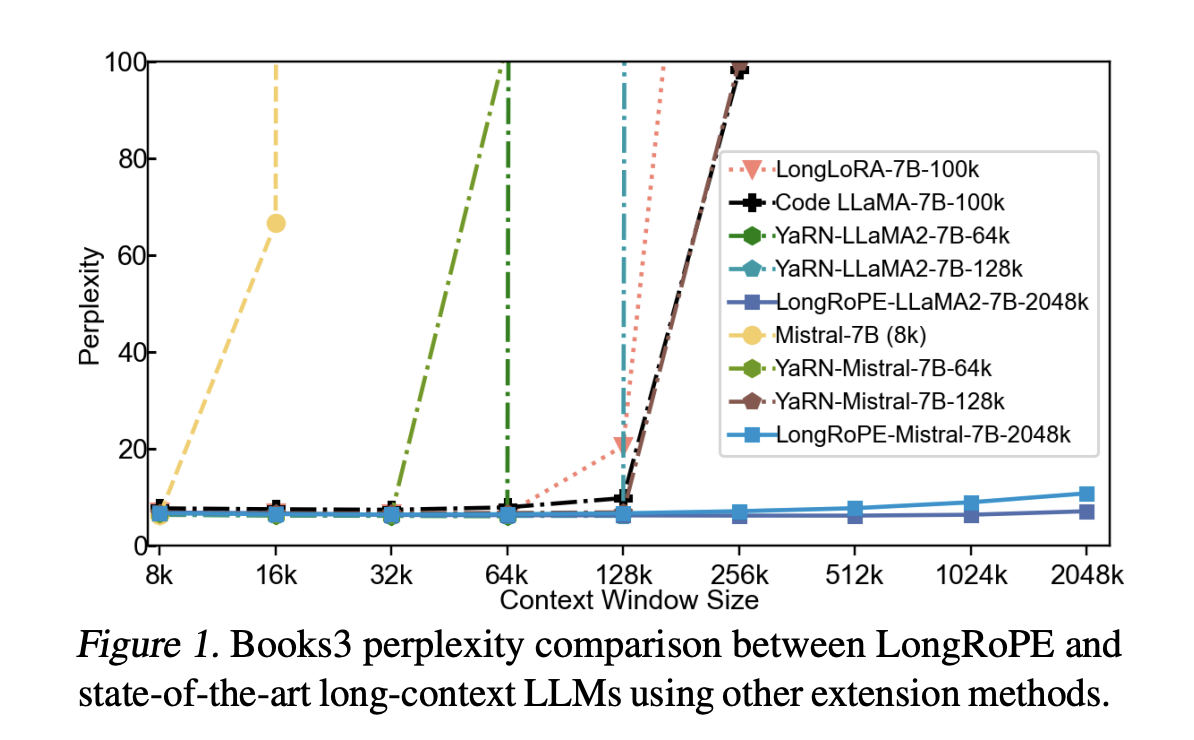
Large language models (LLMs) have witnessed significant advancements, aiming to enhance their capabilities for interpreting and processing extensive textual data. LLMs like GPT-3 have revolutionized our interactions with AI, offering insights and analyses across various domains, from writing assistance to complex data interpretation. However, a key limitation has been their context window size, the amount of text they can consider in a single instance. LLMs could process up to a few thousand tokens, constraining their ability to understand and generate responses for longer documents.
Researchers from Microsoft Research have developed LongRoPE, a novel approach that significantly extends the context window of pre-trained LLMs to an impressive 2 million tokens. This breakthrough was achieved through three innovative strategies: identifying and leveraging non-uniformities in positional interpolation, introducing a progressive extension strategy, and readjusting LongRoPE to recover performance in shorter context windows. These innovations allow LLMs to perform well even when processing longer texts than initially designed.
LongRoPE utilizes an evolutionary search algorithm to optimize positional interpolation, enabling it to extend the context window of LLMs by up to 8 times without fine-tuning for extra-long texts. This is particularly beneficial because it overcomes the challenges of training on long texts, which are scarce and computationally expensive to process. The method has been extensively tested across various LLMs and tasks, demonstrating its effectiveness in maintaining low perplexity and high accuracy even in extended contexts.

The performance of LongRoPE retains the original model’s accuracy within the conventional short context window and significantly reduces perplexity in extended contexts up to 2 million tokens. This capability opens new avenues for LLM applications, enabling them to process and analyze long documents or books in their entirety without losing coherence or accuracy. For instance, LongRoPE’s application in LLaMA2 and Mistral models has shown superior performance in standard benchmarks and specific tasks like passkey retrieval from extensive texts, highlighting its potential to revolutionize leveraging LLMs for complex text analysis and generation tasks.
In conclusion, LongRoPE represents a significant leap forward in the field of LLMs, addressing a critical limitation in context window size. Enabling LLMs to process and understand texts of up to 2 million tokens paves the way for more sophisticated and nuanced AI applications. This innovation not only enhances the capabilities of existing models but also sets a new benchmark for future developments in large language models.
Key highlights of the conducted research in the following points:
- LongRoPE’s innovative approach extends LLM context windows to 2 million tokens, a significant advancement in AI.
- The evolutionary search algorithm optimizes positional interpolation, overcoming the traditional limitations of LLMs.
- Extensive testing demonstrates LongRoPE’s ability to maintain accuracy and reduce perplexity in extended contexts.
- This breakthrough opens new possibilities for complex text analysis and generation, enhancing LLM applications.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 37k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
![]()
Hello, My name is Adnan Hassan. I am a consulting intern at Marktechpost and soon to be a management trainee at American Express. I am currently pursuing a dual degree at the Indian Institute of Technology, Kharagpur. I am passionate about technology and want to create new products that make a difference.
Credit: Source link
Comments are closed.