Meet Google Deepmind’s ReadAgent: Bridging the Gap Between AI and Human-Like Reading of Vast Documents!
In an era where digital information proliferates, the capability of artificial intelligence (AI) to digest and understand extensive texts is more critical than ever. Despite their language prowess, traditional Large Language Models (LLMs) falter when faced with long documents, primarily due to inherent constraints on processing lengthy inputs. This limitation hampers their utility in scenarios where comprehension of vast texts is essential, underscoring a pressing need for innovative solutions that mirror human cognitive flexibility in dealing with extensive information.
The quest to transcend these boundaries led researchers from Google DeepMind and Google Research to pioneer ReadAgent. This groundbreaking system draws inspiration from human reading strategies to significantly enhance AI’s text comprehension capabilities. Unlike conventional approaches that either expand the context window LLMs can perceive or rely on external data retrieval systems to patch gaps in understanding, ReadAgent introduces a more nuanced, human-like method to navigate through lengthy documents efficiently.
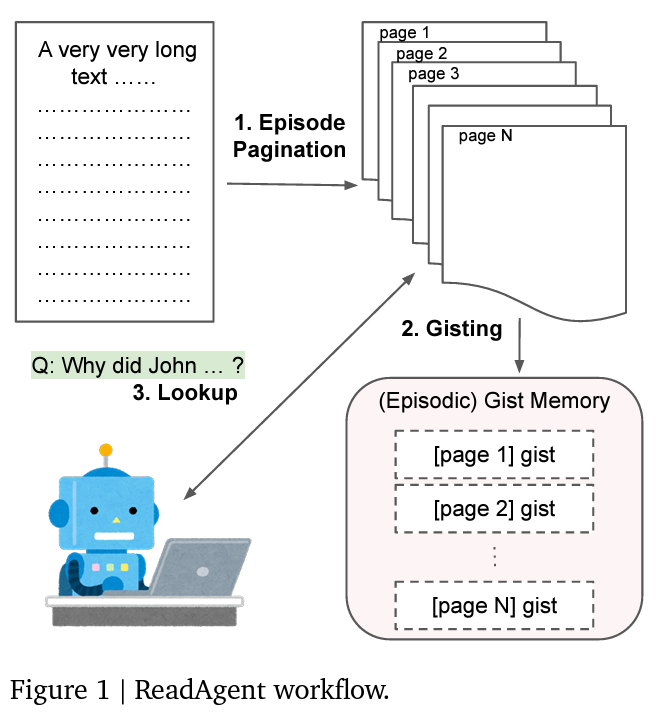
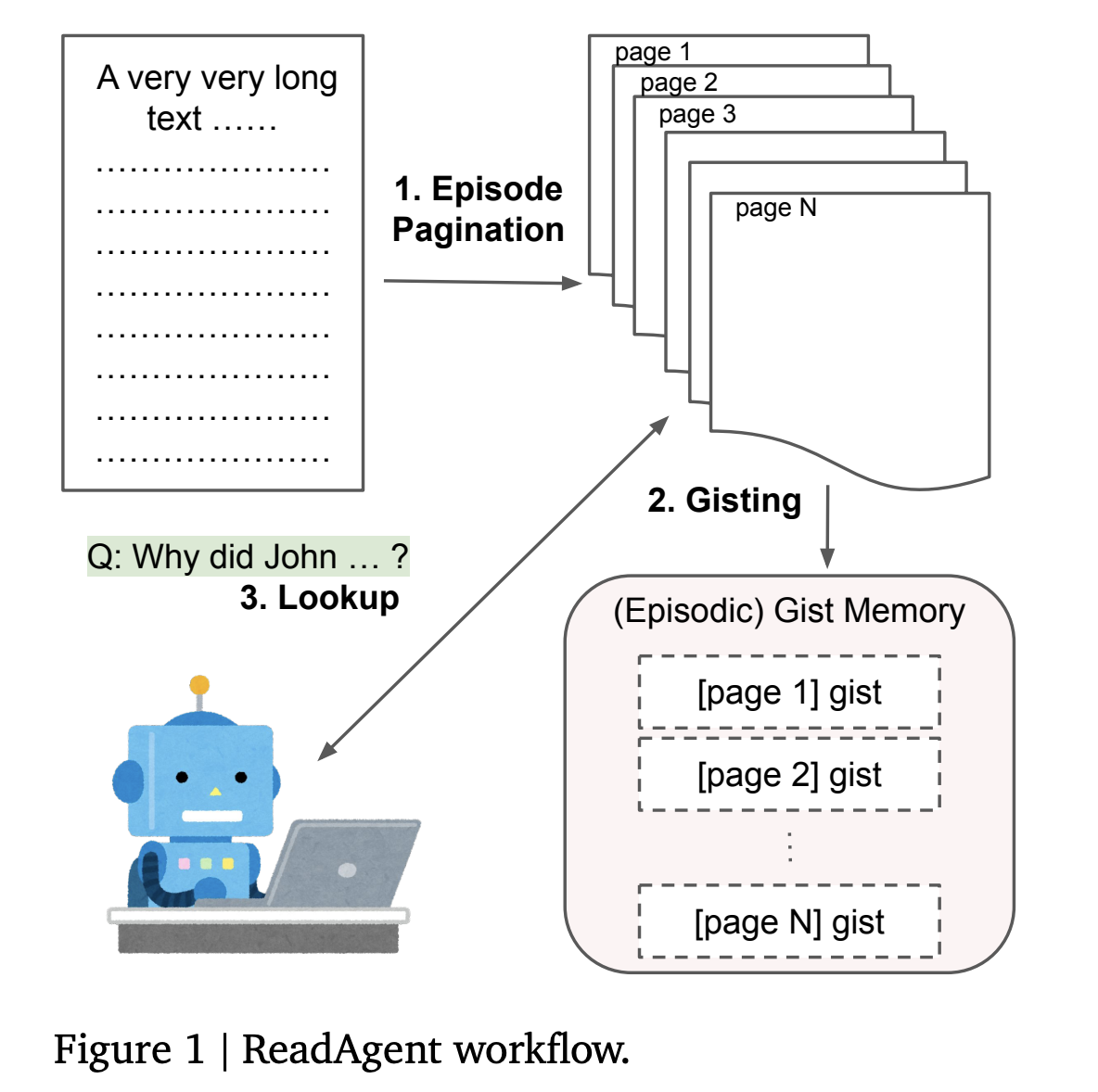
At the heart of ReadAgent’s design is a clever emulation of human reading behaviors, specifically the practice of summarizing and recalling. This method involves a three-step process:
- Segmenting the text into manageable parts
- Condensing these segments into concise, gist-like summaries
- Dynamically remembering detailed information from these summaries as necessary
This innovative approach allows the AI to grasp a document’s overarching narrative or argument, despite its length, by focusing on the core information and strategically revisiting details when needed.
The methodology behind ReadAgent is both simple and ingenious. Initially, the system segments a long text into episodes based on natural pause points, akin to chapters or sections in human reading. These segments are then compressed into ‘gist memories,’ which capture the essence of the text in a fraction of the original size. When specific information is required to address a query or task, ReadAgent revisits the relevant detailed segments, leveraging these gist memories as a roadmap to the original text. This process not only mimics human strategies for dealing with long texts but also significantly extends the effective context length that LLMs can handle, effectively overcoming one of the major limitations of current AI models.
The efficacy of ReadAgent is underscored by its performance across several long-document comprehension tasks. In experiments, ReadAgent demonstrated a substantial improvement over existing methods, extending the effective context length by up to 20 times. Specifically, on the NarrativeQA Gutenberg test set, ReadAgent improved the LLM rating by 12.97% and ROUGE-L by 31.98% over the best retrieval baseline, showcasing its superior ability to understand and process lengthy documents. This remarkable performance highlights not only the potential of AI to assimilate human-like reading and comprehension strategies and the practical applicability of such approaches in enhancing AI’s understanding of complex texts.
Developed by the innovative minds at Google DeepMind and Google Research, ReadAgent represents a significant leap forward in AI’s text comprehension capabilities. Embodying human reading strategies broadens AI’s applicability across domains requiring deep text understanding and paves the way for more sophisticated, cognitive-like AI systems. This advancement showcases the potential of human-inspired AI development and sets a new benchmark for AI’s role in navigating the ever-expanding digital information landscape.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 37k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
![]()
Muhammad Athar Ganaie, a consulting intern at MarktechPost, is a proponet of Efficient Deep Learning, with a focus on Sparse Training. Pursuing an M.Sc. in Electrical Engineering, specializing in Software Engineering, he blends advanced technical knowledge with practical applications. His current endeavor is his thesis on “Improving Efficiency in Deep Reinforcement Learning,” showcasing his commitment to enhancing AI’s capabilities. Athar’s work stands at the intersection “Sparse Training in DNN’s” and “Deep Reinforcemnt Learning”.
Credit: Source link
Comments are closed.