Researchers at Cornell University Introduced HiQA: An Advanced Artificial Intelligence Framework for Multi-Document Question-Answering (MDQA)
A significant challenge with question-answering (QA) systems in Natural Language Processing (NLP) is their performance in scenarios involving extensive collections of documents that are structurally similar or ‘indistinguishable.’ Traditional models often need help to retrieve accurate information from such massive, homogeneous datasets, leading to issues in the precision and relevance of the responses. This limitation becomes particularly pronounced in multi-document QA (MDQA) tasks, where the system must discern and integrate details across numerous documents to formulate coherent answers.
Current methods in MDQA rely on Retrieval-Augmented Generation (RAG) for extracting critical data from unstructured texts, showing effectiveness across diverse NLP tasks. RAG can also be applied to multimodal tasks, such as image generation, using a pre-trained CLIP model for retrieval. Some work has integrated the reasoning capabilities of Language Models (LLMs) into RAG, actively determining the need for retrieval and evaluating the relevance of context. Document QA systems like PDFTriage and PaperQA address structured document QA tasks by extracting structural elements and gathering evidence from relevant papers. Multi-document QA is more challenging and requires considering relationships between documents. Knowledge graphs and LLMs are used to model these relationships.
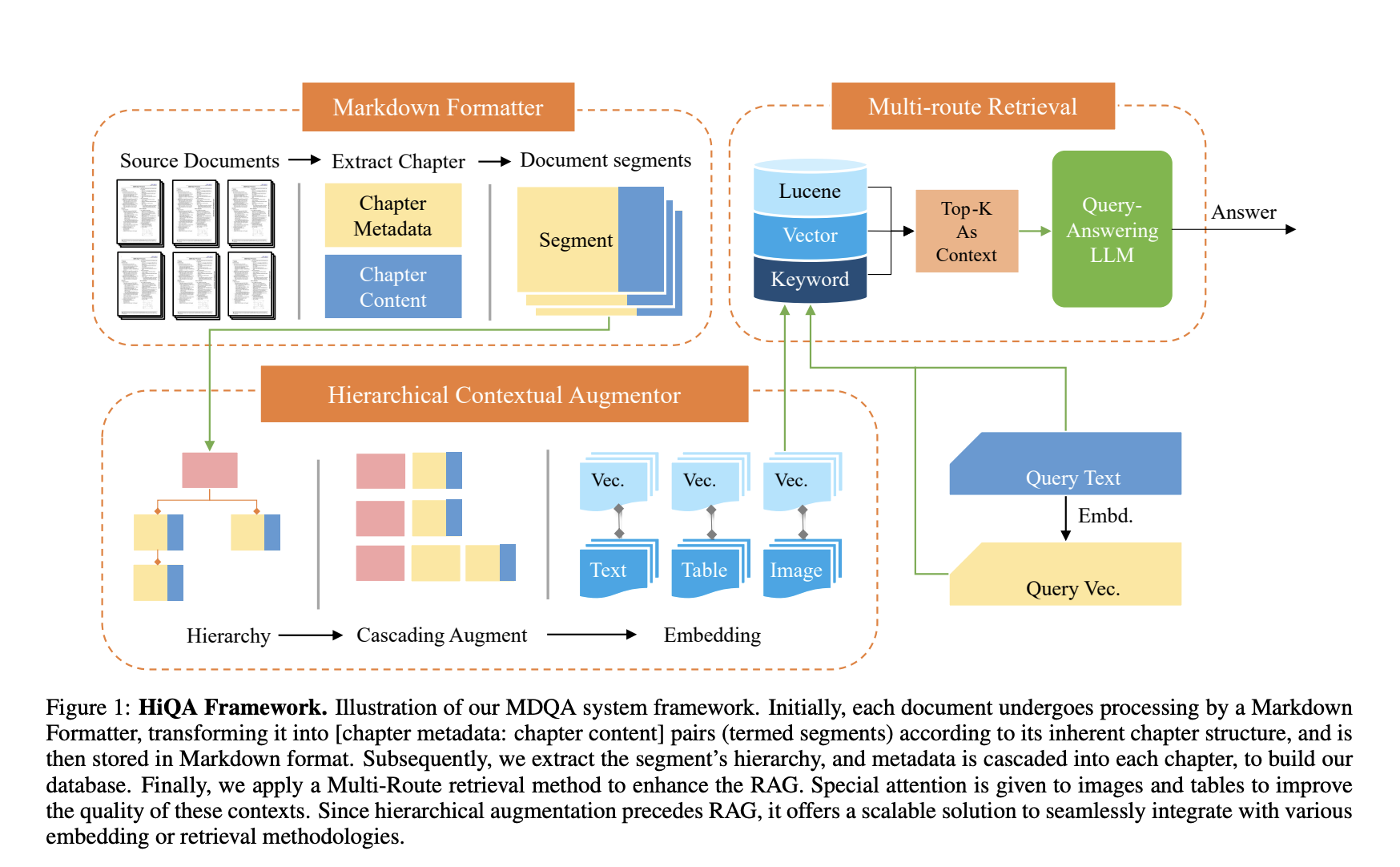
Researchers from Cornell University have introduced HiQA, a novel framework developed by integrating cascading metadata and a multi-route retrieval mechanism. This method represents a significant departure from conventional ‘hard partitioning’ techniques, employing a ‘soft partitioning’ approach to augment document segments with metadata. This strategy ensures enhanced cohesion within the embedding space, facilitating more precise and relevant knowledge retrieval across multi-document environments.
HiQA’s methodology revolves around three core components: a Markdown Formatter (MF) for document parsing, a Hierarchical Contextual Augmentor (HCA) for metadata extraction and augmentation, and a Multi-Route Retriever (MRR) to enhance retrieval accuracy. The MF transforms source documents into markdown files, delineating each section into distinct chapters. The Hierarchical Contextual Augmentor (HCA) enriches these segments with hierarchical metadata, optimizing the information structure for retrieval. Lastly, the MRR employs a sophisticated approach, leveraging vector similarity, Elastic search, and keyword matching to meticulously select the most relevant segments.
HiQA excels in complex cross-document tasks, showcasing a remarkable ability to succinctly organize and present relevant information. This performance is attributed to its integration of cascading metadata and the strategic use of a multi-route retrieval mechanism. The MasQA dataset is introduced to evaluate the proposed framework, consisting of technical manuals, a college textbook, and public financial reports, which contain various types of questions, such as single and multiple-choice, descriptive, comparative, table, and calculation questions. The Log-Rank Index is proposed as a novel evaluation metric to measure the RAG algorithm’s effectiveness in document ranking. PCA and tSNE visualizations demonstrate that HCA leads to a more compact distribution and enhances the focus of the RAG algorithm on the target domain.
In conclusion, the introduction of HiQA signifies a groundbreaking advancement in MDQA, addressing the critical challenge of efficiently processing and retrieving information from large-scale indistinguishable documents. By employing a soft partitioning approach and enhancing retrieval mechanisms, HiQA offers a robust solution that outperforms traditional methods. This research contributes to the theoretical understanding of document segment distribution in the embedding space and presents practical implications for various applications. The development and validation of HiQA pave the way for future innovations in the field, promising enhanced accessibility and precision in information retrieval across diverse domains.
Check out the Paper and Github. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 37k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
![]()
Nikhil is an intern consultant at Marktechpost. He is pursuing an integrated dual degree in Materials at the Indian Institute of Technology, Kharagpur. Nikhil is an AI/ML enthusiast who is always researching applications in fields like biomaterials and biomedical science. With a strong background in Material Science, he is exploring new advancements and creating opportunities to contribute.
Credit: Source link
Comments are closed.