Researchers from NVIDIA and the University of Maryland Propose ODIN: A Reward Disentangling Technique that Mitigates Hacking in Reinforcement Learning from Human Feedback (RLHF)
The well-known Artificial Intelligence (AI)-based chatbot, i.e., ChatGPT, which has been built on top of GPT’s transformer architecture, uses the technique of Reinforcement Learning from Human Feedback (RLHF). RLHF is an increasingly important method for utilizing the potential of pre-trained Large Language Models (LLMs) to generate more helpful, truthful responses that are in line with human preferences.
In RLHF, a language model is trained to produce responses that maximize the learned reward through reinforcement learning, after which a reward model is trained based on human preferences for particular prompts. Since gathering human ratings is typically less complicated than gathering demos for supervised fine-tuning, this approach streamlines the process of collecting data.
However, reward hacking is a subtle problem with RLHF, where the policy gets a large reward without meeting the real objectives. This happens as a result of the reward model’s limited Out-Of-Distribution (OOD) generalization and potential imperfections in representing human preferences. Being a strong LLM, the language model can provide OOD examples to take advantage of flaws in the reward model.
The scenario is further complicated by human preference data, which is frequently skewed and inconsistent due to task complexity and subjectivity, defects in rating standards, and the low caliber of raters. Verbosity is a popular example of reward hacking, in which models produce more tokens to appear more thorough or better formatted in responses, but there is no real improvement in quality.
In order to address these issues, recent research from NVIDIA and the University of Maryland has aimed to mitigate reward hacking by examining how RL algorithms and incentive models affect verbosity and performance. The team has presented an evaluation technique to compare various training setups and account for biases in model-based evaluations. The technique has provided a comprehensive knowledge of various response durations by evaluating performance on the Pareto front of evaluation score vs. length.
This process is intended to analyze the trade-off between the LLM’s assessment score and response duration, allowing for a systematic comparison of different training settings. By varying the training hyperparameters, it can be evaluated how these modifications affect the ratio of verbosity to answer quality.
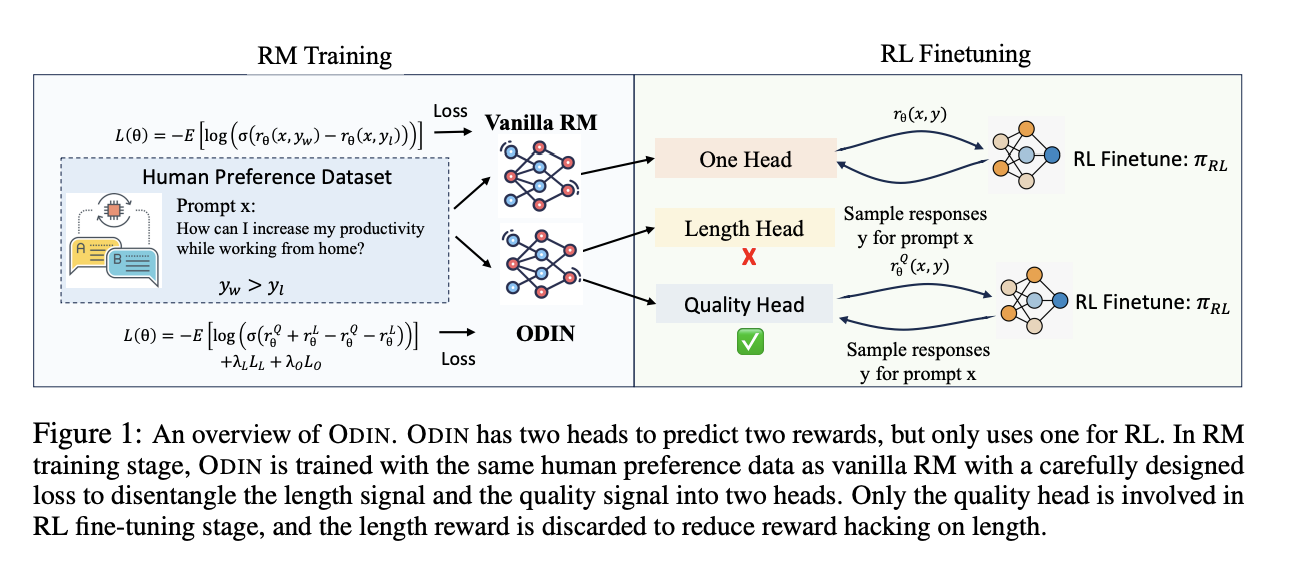
The study looks at RL hyperparameters and techniques, such as reward clipping and length penalty, to lessen reward hacking on length. The primary goal is to remove the spurious length signal from the reward, even though various tuning procedures can yield better outcomes. To accomplish this, the team has suggested a two-head reward model that separates representations for length from true preferences. The length head is deleted during RL.
The suggested reward disentangling technique, ODIN, has been used with the help of which, even with a more costly tuning budget, the policy was able to attain a larger Pareto front than prior results. Proximal Policy Optimisation (PPO) and ReMax both benefit from ODIN’s effectiveness, indicating that it can be used to enhance other RL-tuning methods and lessen length hacking.
In conclusion, this method’s experimental results have shown a noteworthy decrease in the reward model’s association with response duration. The derived strategy performs significantly better when the quality of the information is prioritized over verbosity. This method successfully reduces the problem of response length-related reward hacking, improving the dependability and utility of LLMs trained using the RLHF paradigm.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 37k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
![]()
Tanya Malhotra is a final year undergrad from the University of Petroleum & Energy Studies, Dehradun, pursuing BTech in Computer Science Engineering with a specialization in Artificial Intelligence and Machine Learning.
She is a Data Science enthusiast with good analytical and critical thinking, along with an ardent interest in acquiring new skills, leading groups, and managing work in an organized manner.
Credit: Source link
Comments are closed.