Scaling Up LLM Agents: Unlocking Enhanced Performance Through Simplicity
While large language models (LLMs) excel in many areas, they can struggle with complex tasks that require precise reasoning. Recent solutions often focus on sophisticated ensemble methods or frameworks where multiple LLM agents collaborate. These approaches certainly improve performance, but they add layers of complexity. However, what if a simpler strategy could lead to significant gains?
This work investigates a fascinating phenomenon: the potential to improve LLM performance simply by scaling up the number of agents used. It introduces a remarkably straightforward method – sampling and voting – that involves generating multiple outputs from LLMs and using majority voting to decide the final response. Let’s dive into the details.
The Sampling-and-Voting Method
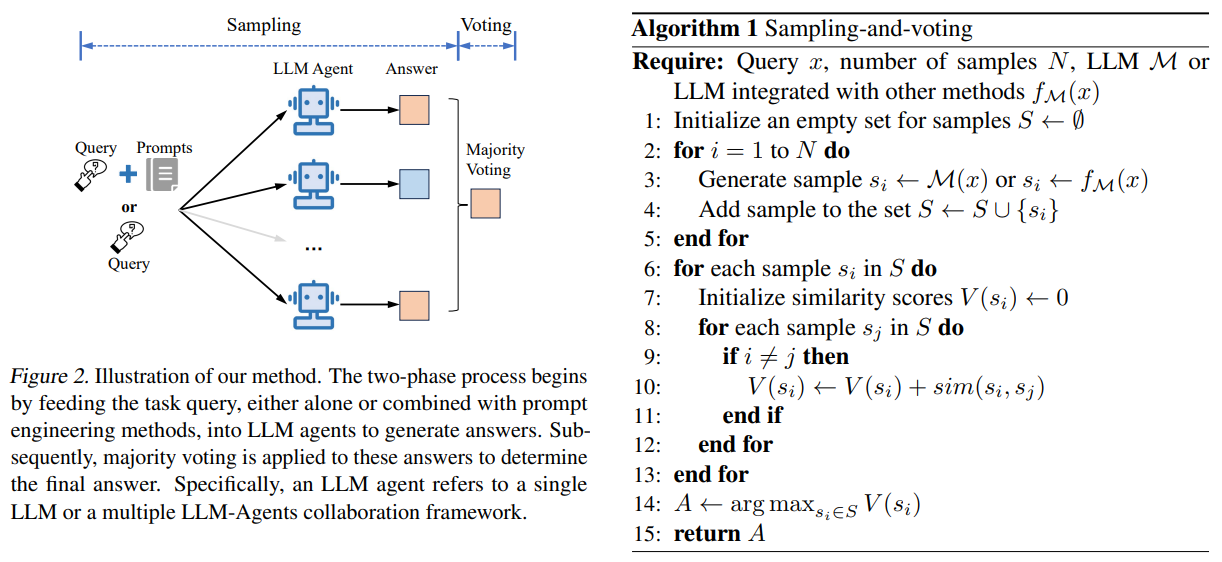
At its core, the sampling-and-voting method is refreshingly simple and comprises two phases (See Fig. 2):
- Sampling: The task query is repeatedly fed into an LLM (or a framework with multiple LLM agents), generating multiple outputs (samples).
- Voting: Majority voting determines the final answer. For closed-ended tasks (e.g., multiple choice), this involves counting the frequency of each option. For open-ended tasks (e.g., code generation), similarity measures like BLEU score are used to rank samples. The sample with the highest similarity to others wins.
This process (Algorithm 1) is elegantly agnostic, making it a potent plug-in to enhance existing LLM techniques.
The method’s efficacy is extensively evaluated across the following three tasks:
- Arithmetic Reasoning: GSM8K and the challenging MATH dataset
- General Reasoning: MMLU and a chess state tracking task
- Code Generation: HumanEval dataset
To explore the range of benefits, the authors tested language models of varying scales, including Llama2, GPT-3.5-Turbo, and GPT-4.
To test how well the method plays with other methods, it was combined with diverse techniques:
- Prompt Engineering: Integrating with Chain-of-Thought (CoT), Zero-Shot Cot, and Solo Performance Prompting.
- Multiple LLM Agents Collaboration: Used in conjunction with debate-style (LLM-Debate) and self-reflection methods.
The results offer compelling insights:
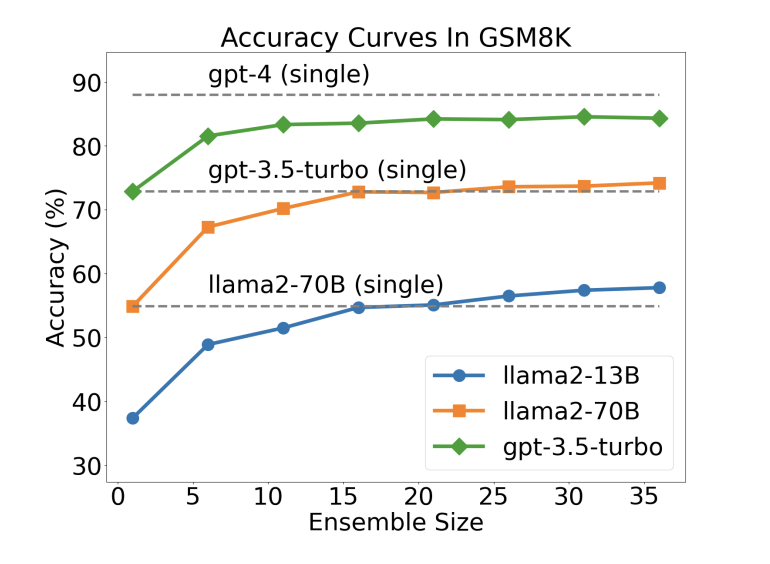
- Performance Scaling: Increasing the number of agents generally boosts LLM performance across tasks and models of varying sizes. Surprisingly, smaller LLMs, when scaled up, often rival or outperform larger counterparts (Fig. 1).
- Compatibility: The method combines seamlessly with other techniques, leading to even greater performance gains.
- Simplicity vs. Complexity: In most cases, the proposed method alone achieves results on par with more complex approaches, suggesting power in its straightforward design.
Thorough experiments demonstrate the method’s consistency across hyperparameters (Fig. 4) and reveal a key point: performance gains positively correlate with task difficulty (Table 5). To unpack this relationship, three dimensions of difficulty are isolated:
- Inherent Difficulty: Gains first increase and then decrease as problems become extremely complex.
- Number of Steps: Gains become more pronounced as the steps needed to solve the task increase.
- Prior Probability: Performance improves when the likelihood of a correct answer is higher.
These findings inspired optimizations like stepwise or hierarchical sampling-and-voting, maximizing gains through a nuanced understanding of task difficulty.
In conclusion, this work establishes a new benchmark, demonstrating that sometimes, ‘more agents’ may indeed be all you need. In many cases, scaling up LLM agents with a simple sampling-and-voting strategy significantly improves performance without intricate methods. This discovery simplifies complex LLM applications and paves the way for cost-optimization of future systems, a focus of ongoing research.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 38k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
You may also like our FREE AI Courses….
![]()
Vineet Kumar is a consulting intern at MarktechPost. He is currently pursuing his BS from the Indian Institute of Technology(IIT), Kanpur. He is a Machine Learning enthusiast. He is passionate about research and the latest advancements in Deep Learning, Computer Vision, and related fields.
Credit: Source link
Comments are closed.