Google DeepMind Introduces Round-Trip Correctness for Assessing Large Language Models
The advent of code-generating Large Language Models (LLMs) has marked a significant leap forward. These models, capable of understanding and generating code, are revolutionizing how developers approach coding tasks. From automating mundane tasks to fixing complex bugs, LLMs promise to reduce development time and improve code quality significantly. Accurately assessing these models’ capabilities remains a challenge. Evaluation benchmarks, while foundational, offer a narrow window into the vast landscape of software development, focusing primarily on basic programming tasks or limited data science applications. This narrow focus falls short of capturing developers’ diverse challenges, highlighting the need for a more comprehensive evaluation method.
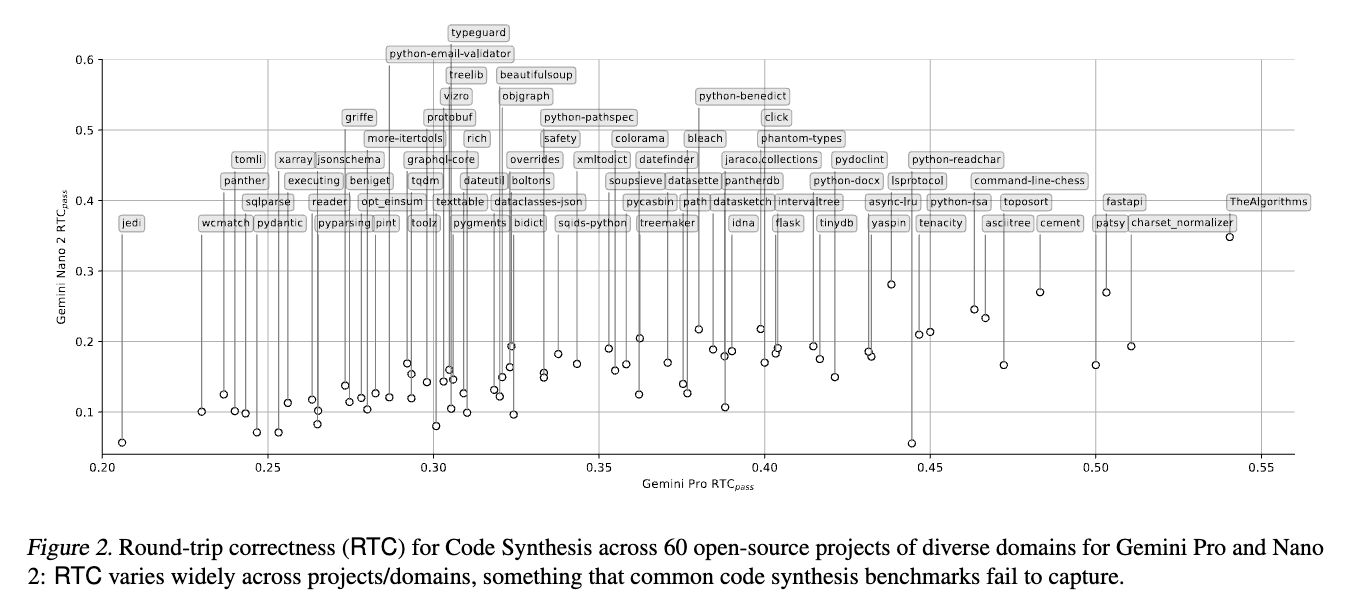
Google DeepMind introduces Round-Trip Correctness (RTC), an innovative evaluation method that broadens the assessment horizon of code LLMs. Unlike conventional benchmarks that rely on manual curation of tasks, RTC adopts an unsupervised approach, enabling evaluations across a wider array of real-world software domains without requiring exhaustive manual effort. The essence of RTC lies in its unique evaluation framework, where a model predicts a coding task and its inverse, such as generating code from a description and vice versa. This method evaluates the model’s ability to maintain the semantic integrity of the original input throughout the round-trip, offering a nuanced measure of its understanding and generation capabilities.

By leveraging the model’s performance on both forward and reverse tasks, RTC assesses its code synthesis and editing proficiency, among other applications. This approach evaluates the model’s accuracy in generating semantically correct code and its effectiveness in understanding and interpreting code descriptions. The adaptability of RTC extends to various coding tasks and domains, showcasing its potential as a universal framework for model evaluation.
Demonstrating a strong correlation with model performance on established narrow-domain benchmarks, RTC also reveals its capability to facilitate evaluations in a broader range of software domains. This comprehensive assessment is pivotal for developing LLMs that are more attuned to the multifaceted needs of software development. The insights gained from RTC evaluations are invaluable for guiding the evolution of code-generating models, ensuring they are robust, versatile, and aligned with real-world development challenges.

In conclusion, the introduction of Round-Trip Correctness as a method for evaluating code LLMs represents a significant advancement in the field. This method offers:
- A comprehensive and unsupervised approach to model evaluation extends beyond the limitations of traditional benchmarks.
- The capability to assess models across a diverse spectrum of software domains, reflecting the real-world challenges of software development.
- Insights into LLMs’ code generation and understanding capabilities, fostering the development of more effective and adaptable models.
By bridging the gap between narrow-domain benchmarks and the expansive needs of software development, RTC paves the way for the next generation of code-generating LLMs. These models promise to be more in tune with developers’ diverse needs, ultimately enhancing the efficiency and quality of software development processes.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 38k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
You may also like our FREE AI Courses….
![]()
Hello, My name is Adnan Hassan. I am a consulting intern at Marktechpost and soon to be a management trainee at American Express. I am currently pursuing a dual degree at the Indian Institute of Technology, Kharagpur. I am passionate about technology and want to create new products that make a difference.
Credit: Source link
Comments are closed.