This Machine Learning Study Tests the Transformer’s Ability of Length Generalization Using the Task of Addition of Two Integers
Transformer-based models have transformed the fields of Natural Language Processing (NLP) and Natural Language Generation (NLG), demonstrating exceptional performance in a wide range of applications. The best examples of these are the recently introduced models Gemini by Google and GPT models by OpenAI. Several studies have shown that these models perform well in mathematical reasoning, code synthesis, and theorem-proving tasks, but they struggle with length generalization, which is the capacity to apply their knowledge to sequences longer than those encountered during training.
This constraint raises important questions about whether Transformers actually understand the fundamental algorithms of a task or if they rely on quick fixes and surface-level memory that don’t work for larger, more complicated tasks. Researchers have been trying to find whether Transformers have a built-in design flaw that prevents successful length generalization.
To overcome this, a team of researchers from Google DeepMind has focused on a methodical analysis of the length generalization ability of the Transformer, with particular attention to the N-digit decimal addition problem. Despite the addition problem’s relative simplicity compared to natural language, this study treats it as synthetic language learning to obtain insights into the Transformer’s capacity to internalize basic processes.
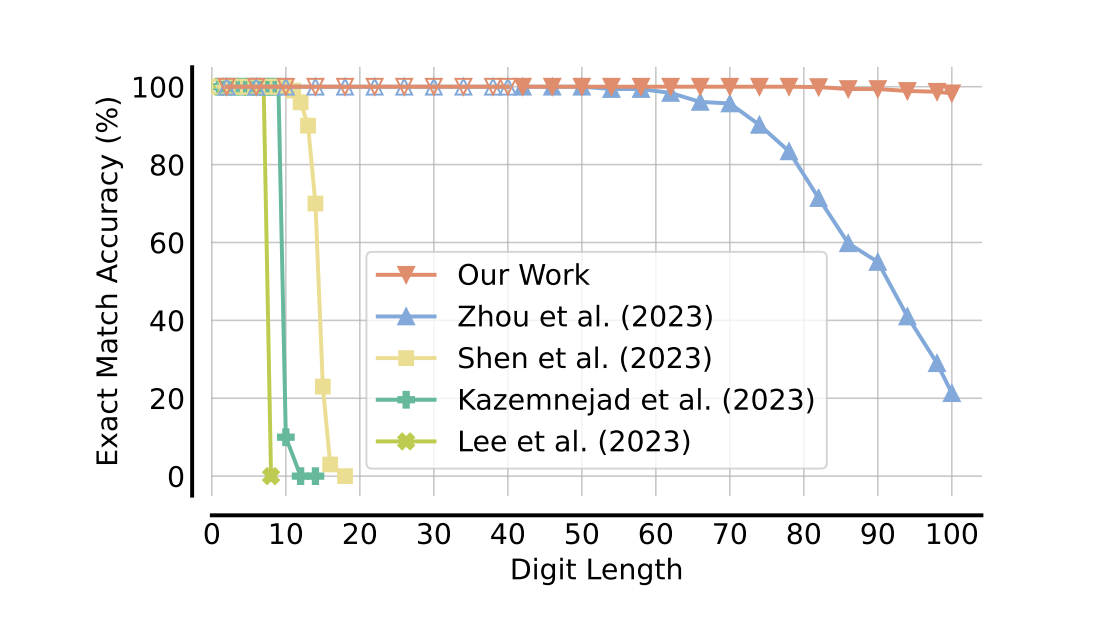
The team has explored the length generalization ability of the Transformer model, namely by using the addition of integers as a lens. The results have revealed an important interdependency: a Transformer’s ability to process longer sequences depends not only on its architecture and size but also heavily on the type of data it uses and the position encoding used. The team has shared that the position encoding technique, which gives the model a sense of sequence order, and the data format, which describes how information is provided to the model, are crucial components in determining whether or not the model can generalize.
Through experiments involving different combinations of position encodings and data formats, the team has found configurations that enable typical Transformers to extrapolate to sequences 2.5 times longer than those encountered during training, thereby considerably exceeding their training limits. This has shown that Transformers are capable of handling lengthier sequences successfully when given the correct training and circumstances.
In contrast to the expectation of models to perform consistently on data similar to their training set in in-distribution generalization, length generalization is a more delicate accomplishment, emphasizing the complex interplay between training dynamics, data presentation, and model design in order to achieve dependable extrapolation capabilities.
The team has summarized their primary contributions as follows.
- It has been discovered that the strategic selection of position encoding and data format is critical to achieving successful length generalization in language models, especially in tasks such as integer addition. The capabilities of these models have been extended by optimizing these aspects, allowing them to handle sequences up to 2.5 times longer than the ones they were trained on.
- Several data formatting and augmentation approaches have been studied, and it has been found that the effectiveness of these approaches in improving length generalization is highly dependent on the kind of position encoding that is applied. This emphasizes the importance of using a coordinated strategy when choosing the position encoding and data format to get the best results.
- It has been found that models achieved remarkable generalization, such as extrapolating to lengths well beyond their training scope; however, there was a noticeable fragility in this skill. The model’s performance varies greatly between training iterations due to factors like the randomization of weight initialization and the order in which training data is given.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 38k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
You may also like our FREE AI Courses….
![]()
Tanya Malhotra is a final year undergrad from the University of Petroleum & Energy Studies, Dehradun, pursuing BTech in Computer Science Engineering with a specialization in Artificial Intelligence and Machine Learning.
She is a Data Science enthusiast with good analytical and critical thinking, along with an ardent interest in acquiring new skills, leading groups, and managing work in an organized manner.
Credit: Source link
Comments are closed.