This AI Paper from UC Berkeley Advances Machine Learning by Integrating Language and Video for Unprecedented World Understanding with Innovative Neural Networks

Current approaches to world modeling largely focus on short sequences of language, images, or video clips. This means models miss out on information present in longer sequences. Videos encode sequential context that can’t be easily gleaned from text or static images. Long-form text holds information unobtainable in short pieces and is key to applications like document retrieval or coding. Processing long video and text sequences together could enable a model to develop a broader multimodal understanding, making it a potentially powerful tool for many tasks.
Directly modeling millions of tokens is extremely difficult due to the high computational cost, memory constraints, and lack of suitable datasets. Fortunately, RingAttention allows us to scale to longer context sizes without overheads, enabling efficient training on long sequences.
Researchers need a large dataset of long videos and language sequences to harness this capability. They have curated this dataset from publicly available books and video sources containing videos of diverse activities and books on various topics. To reduce training costs, they have gradually increased context size from 4K to 1M tokens to reduce this cost, and this approach performs well in extending context effectively.
Researchers face several challenges when training on video and language simultaneously. They discovered that combining video, images, and text is key to balancing visual quality, sequential information, and linguistic understanding. They achieve this by implementing an efficient form of masked sequence packing for training with different sequence lengths. Additionally, determining the right balance between image, video, and text training is crucial for cross-modal understanding, and the researchers suggest an effective ratio. Furthermore, to deal with the lack of long-form chat datasets, they developed a method where a short-context model is used to generate a question-answering (QA) dataset from books, which proves crucial for long-sequence chat ability.
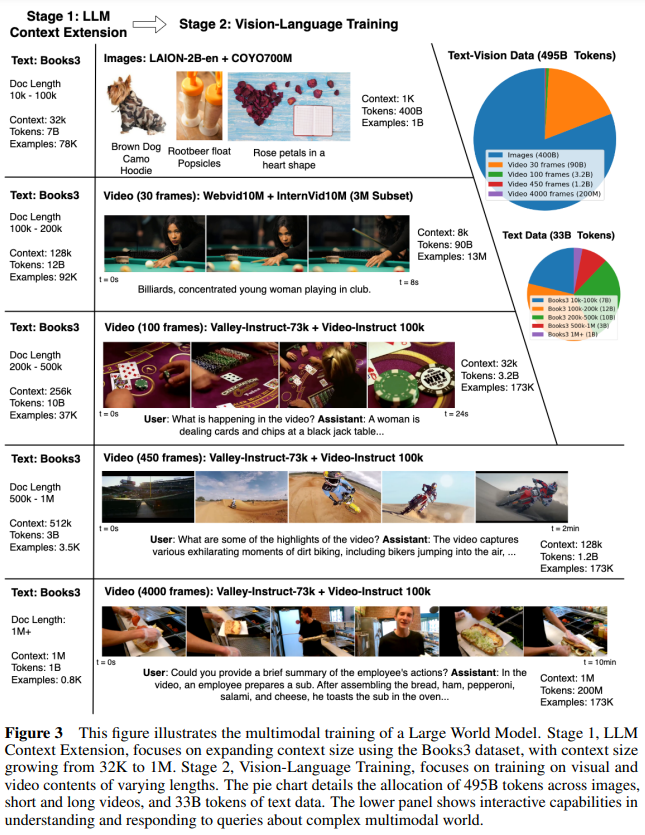
Let’s discuss the overall method in detail; the researchers train a large autoregressive transformer model on a massive dataset, incrementally increasing its context window to a million tokens. They build on Llama2 7B and combine long multimodal sequences with text-image, text-video data, and books. The training stages and datasets are shown in Figure 3, and the model architecture is shown in Figure 4.
Training Stages and Datasets
- Stage I: Long-Context Language Model
- Extending Context: The researchers use RingAttention for scalable long-document training and adjust positional encoding parameters.
- Progressive Training: They save compute by training on increasingly longer sequences (32K to 1M tokens).
- Chat Fine-tuning: They generate a QA dataset for long-context chat abilities from books.
- Stage II: Long-Context Vision-Language Models
- Architectural Changes: The researchers use VQGAN tokens for images and videos and add markers to switch between vision and text generation.
- Progressive Training: The model undergoes several stages of training, each increasing in sequence length. This step-by-step approach helps learn more effectively by starting with simpler tasks before moving on to more complex sequences.
- Chat Datasets: They include various forms of chat data for their target downstream tasks. By generating a question-answering dataset from long texts, the model improves its ability to engage in meaningful conversations over extended sequences.

On evaluation, the model achieves near-perfect retrieval accuracy over its entire 1M context window and scales better than current LLMs. It also performs competitively in multi-needle retrieval and exhibits strong short-context language performance (shown in Figure 2), indicating successful context expansion. While it has some limitations, such as difficulty with complex long-range tasks, it provides a foundation for future work, including developing more challenging benchmarks.
In conclusion, this pioneering work has set a new benchmark in AI’s capability to comprehend the world by integrating language and video. Leveraging the innovative RingAttention mechanism, the study demonstrates scalable training on an extensive dataset of long videos and books, progressively expanding the context size from 32K to an unprecedented 1M tokens. This approach, combined with the development of masked sequence packing and loss weighting techniques, enables the efficient handling of a diverse array of content. The result is a model with a 1M token context size, the largest to date, adept at navigating the complexities of lengthy video and language sequences. With the open sourcing of this optimized implementation and a 7B parameter model, the research invites further innovation in the field, aiming to enhance AI’s reasoning abilities and understanding of the world.
However, the journey does not end here. Despite its significant achievements, the work acknowledges limitations and areas ripe for future exploration. Enhancing video tokenization for more compact processing, incorporating additional modalities like audio, and improving video data quality and quantity are critical next steps. These advancements promise to further refine AI’s multimodal understanding, opening new pathways for research and application in the quest to develop more sophisticated and capable AI systems.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 38k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
You may also like our FREE AI Courses….
![]()
Vineet Kumar is a consulting intern at MarktechPost. He is currently pursuing his BS from the Indian Institute of Technology(IIT), Kanpur. He is a Machine Learning enthusiast. He is passionate about research and the latest advancements in Deep Learning, Computer Vision, and related fields.
Credit: Source link
Comments are closed.