Google AI Introduces LLM Comparator: A Step Towards Understanding the Evaluation of Large Language Models
Improving LLMs involves continuously refining algorithms and training procedures to enhance their accuracy and versatility. However, the primary challenge in developing LLMs is accurately evaluating their performance. LLMs generate complex, freeform text, making it difficult to benchmark their outputs against a fixed standard. This complexity necessitates innovative approaches to assessment, moving beyond simple accuracy metrics to more nuanced evaluations of text quality and relevance.

Current challenges in analyzing evaluation results include needing more specialized tools, difficulty reading and comparing long texts, and the need to compute metrics by slices. Various methodologies and tools have been developed in the visualization community for analysis, including visualizing individual data points, supporting slice-level analysis, explaining individual predictions, and model comparison. Automatic side-by-side evaluation (AutoSxS) is prevalent in evaluating LLMs. The process involves using baseline models, selecting prompt sets, obtaining individual ratings, and calculating aggregated metrics.
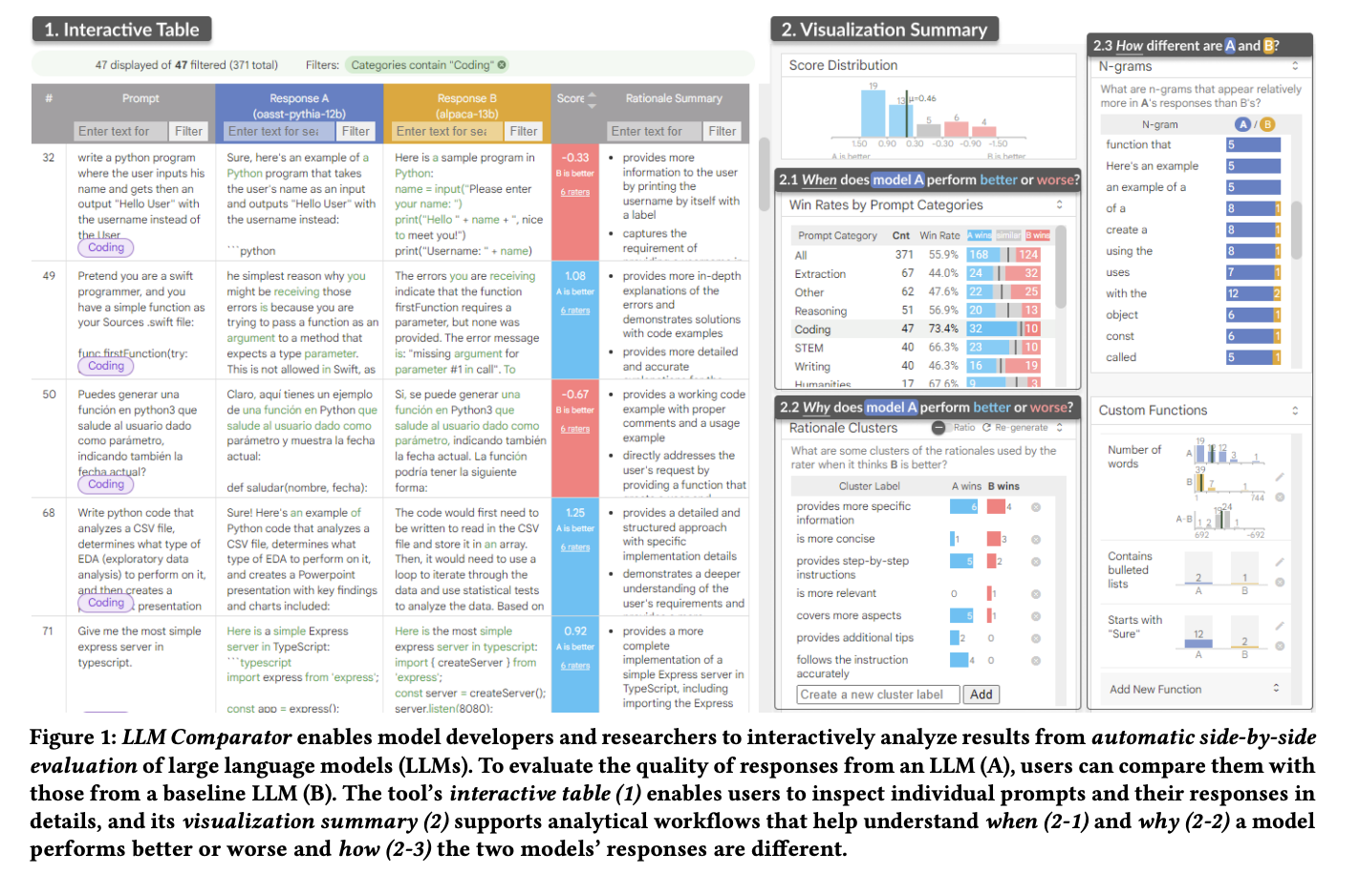
A team of researchers at Google Research has introduced the LLM Comparator tool, which facilitates the side-by-side comparison of LLM outputs, enabling an in-depth analysis of their performance. The LLM Comparator allows users to interactively explore the differences between model responses, clearly representing where and why one model may outperform another.

The LLM Comparator integrates visual analytics, allowing users to delve into the specifics of model performance across different scenarios. It features a score distribution histogram, offering a detailed view of rating variances and a performance visualization across different prompt categories. It is instrumental in pinpointing specific areas of model strength or weakness. Moreover, the tool’s rationale clusters ingeniously condense raters’ reasoning into thematic groups, providing deep insights into their decision-making processes. Adding n-gram analysis and custom functions further enhances this functionality, enabling users to delve into the intricacies of model responses.

The effectiveness of the LLM Comparator is underscored by its impact on Google. Since its introduction, the tool has attracted significant attention, with over 400 users engaging in more than 1,000 evaluation experiments. This widespread adoption speaks to its utility in streamlining the evaluation process for LLM developers, offering valuable insights that guide the refinement of these complex AI systems.

In conclusion, the LLM Comparator represents a significant step forward in evaluating large language models. Providing a scalable, interactive analysis platform addresses the critical challenge of assessing LLM performance. This tool facilitates a deeper understanding of model capabilities and accelerates the development of more advanced and effective AI systems.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 38k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
You may also like our FREE AI Courses….
![]()
Nikhil is an intern consultant at Marktechpost. He is pursuing an integrated dual degree in Materials at the Indian Institute of Technology, Kharagpur. Nikhil is an AI/ML enthusiast who is always researching applications in fields like biomaterials and biomedical science. With a strong background in Material Science, he is exploring new advancements and creating opportunities to contribute.
Credit: Source link
Comments are closed.