Unlocking Speed and Efficiency in Large Language Models with Ouroboros: A Novel Artificial Intelligence Approach to Overcome the Challenges of Speculative Decoding
The prowess of Large Language Models (LLMs) such as GPT and BERT has been a game-changer, propelling advancements in machine understanding and generation of human-like text. These models have mastered the intricacies of language, enabling them to tackle tasks with remarkable accuracy. Their application in real-time scenarios is hampered by a critical limitation: the inference speed. The conventional autoregressive decoding process, which sequentially generates one token at a time, poses a significant bottleneck, making the quest for high-speed inference a critical challenge in the field.
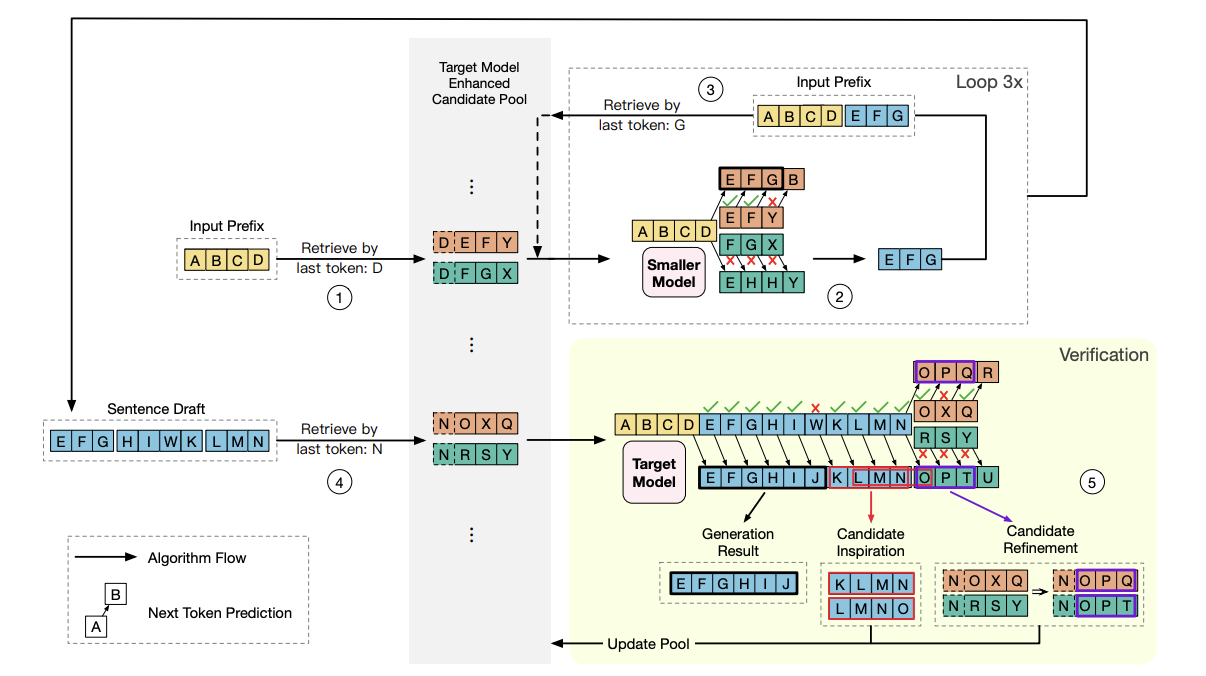
Researchers from the NLP Group, Department of Computer Science and Technology, Institute for Artificial Intelligence, Beijing Information Science and Technology National Research Center, Tsinghua University introduced a novel framework named Ouroboros, which emerges as a beacon of innovation. Ouroboros departs from the traditional autoregressive approach, adopting a speculative decoding method that promises to revolutionize the efficiency of LLMs during inference. This framework generates initial drafts using a smaller, more efficient model. These drafts are then refined and extended in a non-autoregressive manner through a verification process by the larger target model, significantly accelerating the inference process without compromising the quality of the output.
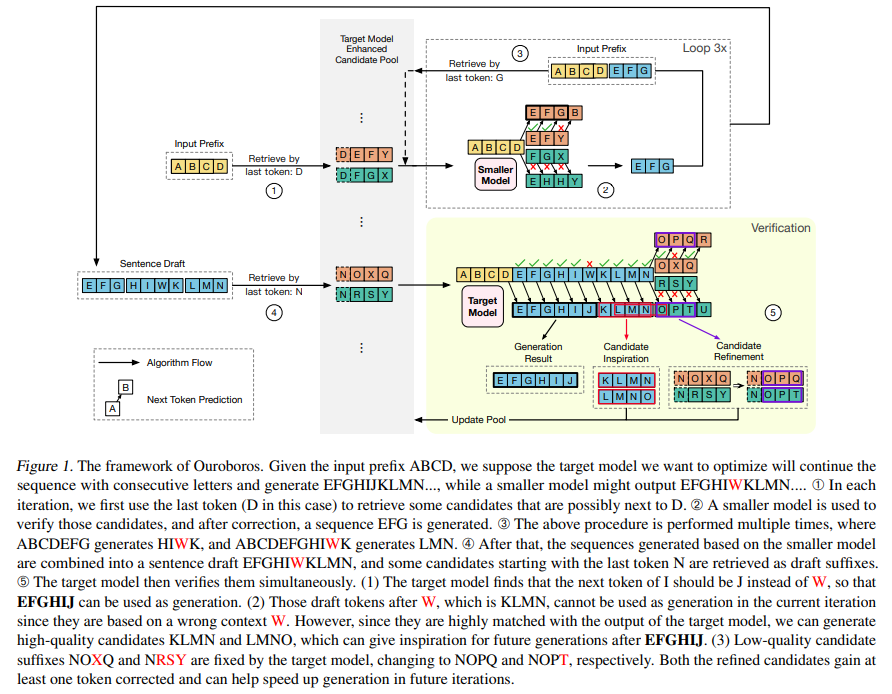
Central to its approach is constructing a phrase candidate pool, a strategic move that enhances the drafting phase. This pool, populated with potential phrase candidates, generates coherent initial drafts more aligned with the target output. The smaller model drafts sentences at the phrase level, leveraging the candidate pool for inspiration. This allows for longer, more accurate drafts, verified and corrected by the larger model. Unlike traditional methods, the verification process utilizes the entire draft, including confirmed and discarded tokens, to refine and extend the output, ensuring high accuracy and coherence.
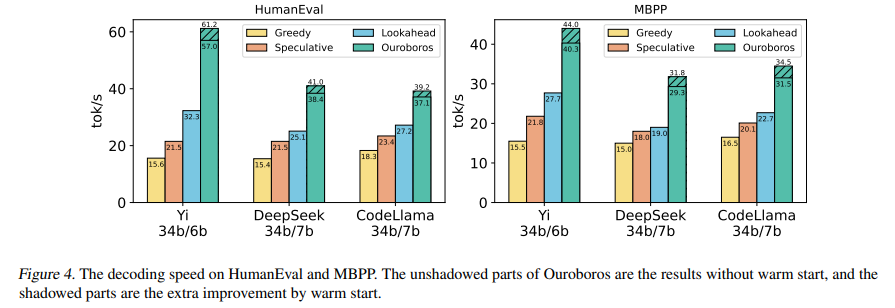
Ouroboros outpaces existing methods such as lookahead decoding and speculative decoding, achieving speedups of up to 2.8x. This acceleration is achieved without detriment to the task performance, maintaining the high quality of text generation synonymous with LLMs. Such advancements herald a new era for real-time applications of LLMs, where speed and accuracy are of the essence. From conversational AI to instant language translation, the potential applications of Ouroboros are vast and varied, offering promising prospects for the future of natural language processing.
Ouroboros represents a significant leap forward in addressing the longstanding challenge of LLM inference efficiency. By ingeniously combining speculative decoding with a phrase candidate pool, it achieves a fine balance between speed and accuracy, paving the way for real-time applications previously beyond reach. This framework exemplifies the potential of innovative approaches to overcome the limitations and sets a new benchmark for future developments in natural language processing.
In conclusion, introducing the Ouroboros framework is pivotal in evolving Large Language Models. Its ability to significantly accelerate the inference process without sacrificing output quality addresses a critical need in the field, opening up new possibilities for applying LLMs in real-time scenarios. As the field advances, the principles underlying Ouroboros will inspire further innovations, continuing the quest for ever more efficient and effective natural language processing technologies.
Check out the Paper and Project. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 38k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
You may also like our FREE AI Courses….
![]()
Sana Hassan, a consulting intern at Marktechpost and dual-degree student at IIT Madras, is passionate about applying technology and AI to address real-world challenges. With a keen interest in solving practical problems, he brings a fresh perspective to the intersection of AI and real-life solutions.
Credit: Source link
Comments are closed.