From Black Box to Open Book: How Stanford’s CausalGym is Decoding the Mysteries of Artificial Intelligence AI Language Processing!
In the evolving landscape of psycholinguistics, language models (LMs) have carved out a pivotal role, serving as both the subject and tool of study. These models, leveraging vast datasets, attempt to mimic human language processing capabilities, offering invaluable insights into the cognitive mechanisms that underpin language understanding and production. Despite their potential, a persistent challenge has been the opaque nature of these models, which, while adept at generating human-like text, often function as “black boxes,” obscuring the causal dynamics of their operations.
Researchers from Stanford University have embarked on an ambitious project to demystify these mechanisms. They argue that while LMs have significantly advanced psycholinguistic research, there’s a critical gap in our understanding of the “why” and “how” behind their responses to various linguistic stimuli. Traditional methods, which have primarily scrutinized the output of these models, need to reveal the intricate causal pathways that guide their language processing abilities.
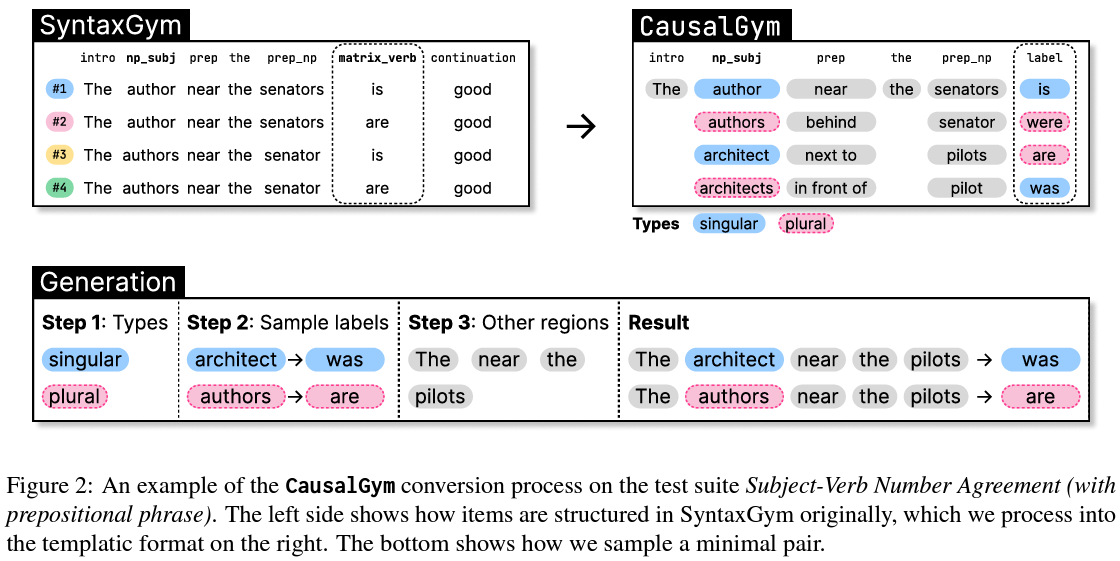
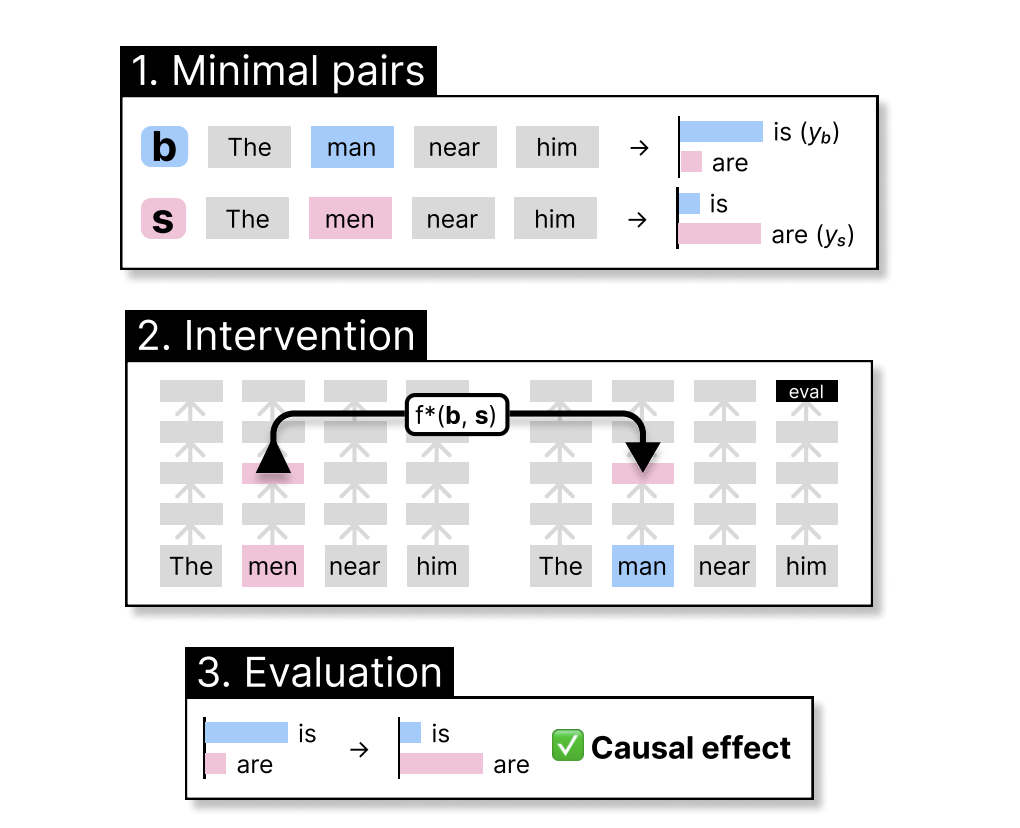
Addressing this gap, the team introduced CausalGym, a novel benchmark designed to peel back the layers of LMs, offering a glimpse into the causal mechanisms at play. CausalGym extends the capabilities of the existing SyntaxGym suite, which focuses on syntactic evaluation, by emphasizing the causal effects of interventions on model behavior. This innovative approach allows researchers to systematically assess the interpretability methods, comparing their efficacy in unveiling the models’ internal workings.
CausalGym distinguishes itself through its methodological rigor and focus on causality. By adapting linguistic tasks from SyntaxGym and applying them within a causal framework, the Stanford team has crafted a robust platform for evaluating interpretability methods. Their work with the Pythia models—ranging from 14 million to 6.9 billion parameters—demonstrates the power of this approach. The benchmark specifically highlights Distributed Alignment Search (DAS) as a superior method for discerning the causal connections within LMs, showcasing its potential to advance our understanding of these complex systems significantly.
The findings from applying CausalGym to Pythia models are both striking and illuminating. The analysis revealed that the learning mechanisms for linguistic phenomena such as negative polarity item licensing and filler-gap dependencies do not occur gradually, as previously thought, but rather in distinct stages. For instance, the accuracy of Pythia-family models on various CausalGym tasks showed a consistent improvement with model scale, with DAS outperforming other methods across the board. Notably, the study found that DAS’s causal efficacy, measured by log odds ratio, was significantly higher than other methods, demonstrating its ability to induce meaningful changes in model behavior.
This research marks a significant departure from conventional studies that have largely focused on the “what” of language model behavior, transitioning towards a deeper exploration of the “why” and “how.” The implications of these findings extend beyond the academic, offering potential insights into how machines can be made to learn and process language more akin to humans. By uncovering the discrete stages through which LMs learn complex linguistic tasks, the research sheds light on the fundamental processes that guide language comprehension and generation in artificial systems.
In sum, the introduction of CausalGym by the Stanford team represents a critical step forward in the quest for model interpretability within psycholinguistics. This research advances our understanding of the internal mechanisms of LMs and sets a new benchmark for future studies aiming to unravel the complexities of artificial language processing. As we continue to explore the vast potential of LMs, tools like CausalGym will be instrumental in bridging the gap between human cognition and artificial intelligence, moving us closer to models that can truly understand and generate human language.
Check out the Paper and Github. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 38k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
You may also like our FREE AI Courses….
![]()
Muhammad Athar Ganaie, a consulting intern at MarktechPost, is a proponet of Efficient Deep Learning, with a focus on Sparse Training. Pursuing an M.Sc. in Electrical Engineering, specializing in Software Engineering, he blends advanced technical knowledge with practical applications. His current endeavor is his thesis on “Improving Efficiency in Deep Reinforcement Learning,” showcasing his commitment to enhancing AI’s capabilities. Athar’s work stands at the intersection “Sparse Training in DNN’s” and “Deep Reinforcemnt Learning”.
Credit: Source link
Comments are closed.