L3GO: Unveiling Language Agents with Chain-of-3D-Thoughts for Precision in Object Generation

AI applications that translate textual instructions into 2D images or 3D models have expanded creative possibilities, yet the challenge persists in obtaining precise outputs. Existing tools often yield unexpected or “hallucinatory” results, lacking fidelity to input prompts. Stable Diffusion models faced issues with combining multiple concepts or distinguishing different attributes. While efforts have enhanced object-attribute attachment, missing objects, etc., the generation of objects requiring precise 3D spatial understanding remains a challenge. Even state-of-the-art diffusion models like DALLE 3 struggle with tasks like creating a chair with five legs as shown in Figure 1.
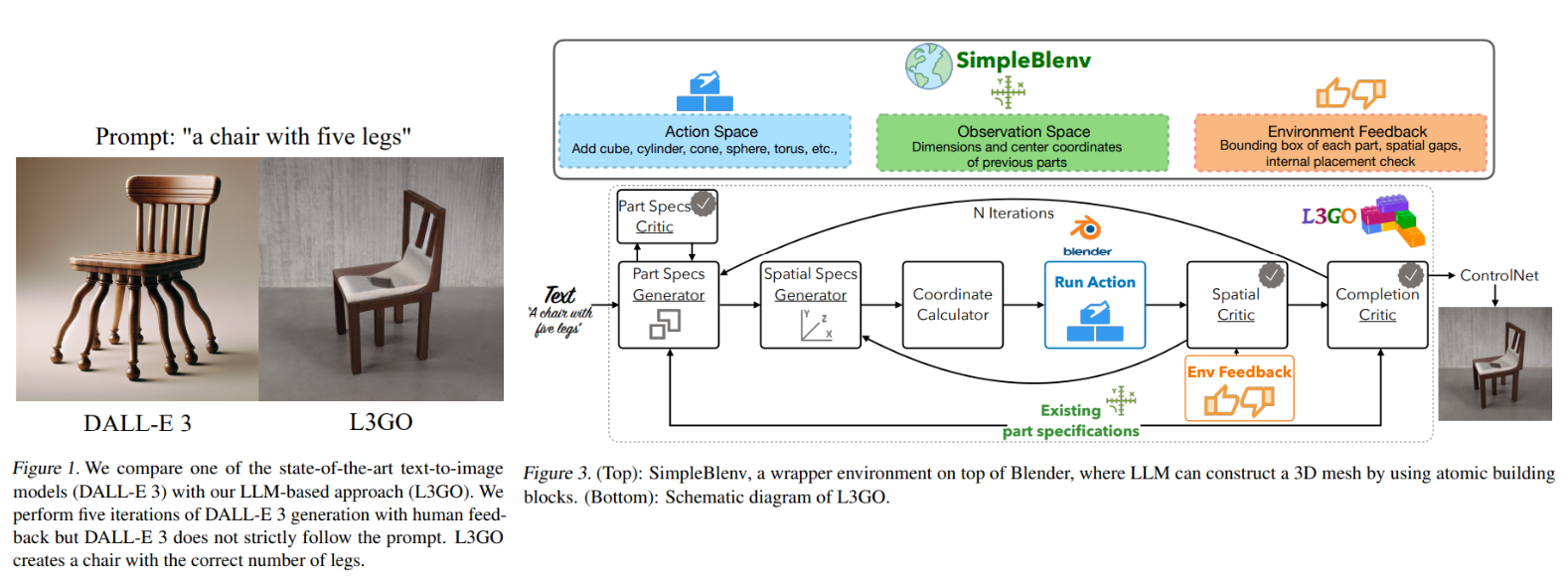
Addressing these challenges, the proposed L3GO leverages the sophisticated text-based reasoning abilities of Language Model Agents (LLMs) to enhance 3D spatial comprehension in object generation. L3GO introduces an inference agent that iteratively seeks feedback from LLMs, integrating corrections to improve the precision for rendering a 3D mesh, subsequently generating a 2D image.
Experiments conducted within Blender, a widely acclaimed 3D modeling software, involve the creation of a dedicated environment named SimpleBlenv. This environment systematically evaluates the text-to-3D mesh generation performance of LLM agents. Notably, even text-trained LLMs like GPT-4 exhibit commendable spatial reasoning abilities, as illustrated in Figure 2, depicting their proficiency in creating simple 3D objects.
L3GO bridges gaps in object generation by adopting a structured, part-by-part approach. The process involves:
- Identifying relevant part specifications.
- Critiquing them.
- Determining spatial specifications and placement.
- Running the action.
- Critiquing spatial placement and completion.
This iterative feedback loop incorporates corrections from SimpleBlenv and utilizes LLM-generated specifications and critiques.
Compounding spatial inaccuracies is the main challenge in generating entire 3D objects in one go. L3GO addresses this by decomposing the creation process into distinct parts, enabling iterative feedback collection and correction processes. SimpleBlenv, built on Blender, facilitates action commands and provides environmental feedback, focusing on five basic shape primitive APIs for simplicity.
The action space in Blender offers a plethora of possibilities, but L3GO focuses on five basic shape primitive APIs to maintain simplicity. These APIs, wrapped for LLMs, allow actions such as adding cubes, cylinders, cones, spheres, and toruses with various parameters. SimpleBlenv maintains a state space representation, tracking created object parts’ size and location and providing crucial feedback to the L3GO agent.
L3GO’s six components, each powered by a language model, include Part Specifications Generator, Part Specifications Critic, Spatial Specifications Generator, Coordinate Calculator, Run Action, and Spatial Critic. These components work cohesively to ensure the precise creation of 3D meshes from text instructions.
- Part Specifications Generator: Initiates object creation by identifying the most crucial part and its dimensions. This sets a clear foundation for assembling subsequent components.
- Part Specifications Critic: Reviews and refines the proposed part specifications to eliminate ambiguity and ensure clarity in the part’s role and placement.
- Spatial Specifications Generator: Determines the optimal spatial arrangement for new parts based on the assembly so far, focusing on precise positioning and attachment points.
- Coordinate Calculator: Calculates exact coordinates for new parts using generated Python code, ensuring precise placement in the 3D model.
- Run Action: Generates and executes a Python script in Blender to create the part’s mesh, specifying its size, position, and shape based on previous calculations.
- Spatial Critic: Conducts spatial accuracy checks on the newly created part, ensuring it integrates seamlessly with the existing structure without errors or overlaps.
After 3D mesh creation, ControlNet with Canny edge detection enhances the generated object’s realism in a 2D image. L3GO, being text-based, relies on predetermined spatial assumptions, guiding the construction process within Blender.

Human evaluations (shown in Figure 5,6 and 7) comparing LLM-based mesh creation using 13 popular object categories from ShapeNet demonstrate L3GO’s superiority over basic GPT-4, ReAct-B, and Reflexion-B. The introduction of Unconventionally Feasible Objects (UFO) further showcases L3GO’s prowess in creating objects with unconventional yet feasible characteristics.
In conclusion, L3GO significantly advances language models’ application range, particularly in generating 3D objects with specific attributes. The integration of language agents in diffusion model pipelines, as demonstrated by L3GO, holds promise for future applications in generative AI.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 38k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
You may also like our FREE AI Courses….
![]()
Vineet Kumar is a consulting intern at MarktechPost. He is currently pursuing his BS from the Indian Institute of Technology(IIT), Kanpur. He is a Machine Learning enthusiast. He is passionate about research and the latest advancements in Deep Learning, Computer Vision, and related fields.
Credit: Source link
Comments are closed.