This AI Paper from CMU and Meta AI Unveils Pre-Instruction-Tuning (PIT): A Game-Changer for Training Language Models on Factual Knowledge
In the fast-paced world of artificial intelligence, the challenge of keeping large language models (LLMs) up-to-date with the latest factual knowledge is paramount. These models, which have become the backbone of numerous AI applications, store a wealth of information during their initial training phase. However, as time passes, the static nature of this stored knowledge becomes a limitation, unable to accommodate the constant evolution of real-world information or specialize in niche domains.
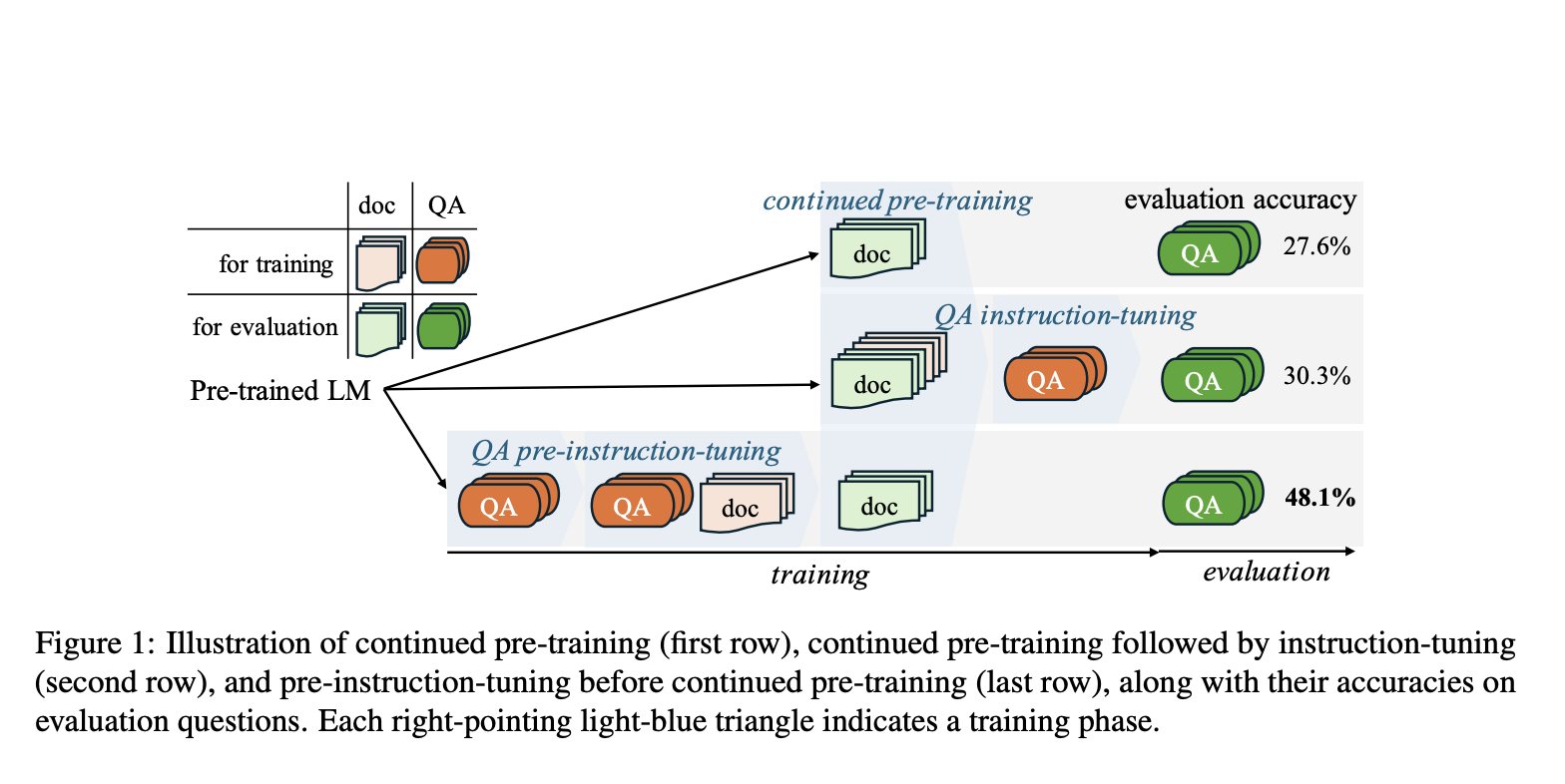
Recent studies have highlighted a promising approach to this problem: instruction-tuning. This method enhances the ability of LLMs to access and update their knowledge base more effectively. By continuing the pre-training process with new documents and applying instruction-tuning techniques, researchers have found significant improvements in the models’ performance. Specifically, experiments with models like Llama-2 have shown that this ongoing training can increase the accuracy of answers to specific questions by up to 30.3%, compared to 27.6% without instruction tuning. This process, however, uncovers the “perplexity curse,” where despite achieving low perplexity (a measure of prediction accuracy), the models still face limits in extracting knowledge effectively from new documents.


To address these challenges, researchers propose pre-instruction-tuning (PIT), which prioritizes exposing LLMs to question-answer (QA) pairs before engaging with more complex document materials as shown in Figure 1 and 4. This strategy is grounded in the hypothesis that understanding how to access knowledge through questions enhances the model’s ability to assimilate and retain new information from detailed documents. The Wiki2023 dataset, comprising up-to-date Wikipedia articles, serves as a testbed for these experiments, revealing that models trained with a combination of QA pairs and documents exhibit superior knowledge absorption capabilities.
Quantitative results underscore the superiority of PIT over traditional instruction-tuning methods: PIT has led to a significant increase in QA accuracies, with a 17.8% improvement for Llama-2 7B models (from 30.3% to 48.1%) and a 16.3% boost for Llama-2 70B models (from 46.4% to 62.7%). Moreover, this method ensures that models not only memorize information but also truly comprehend its application, improving their ability to answer questions accurately. The introduction of pre-instruction-tuning++ (PIT++), which further refines the training process by focusing on the sequence of QA and document exposure, marks a significant leap forward. This method significantly enhances the model’s performance, confirming the importance of strategic training sequences in knowledge acquisition.
Overall, the research presents a compelling case for the benefits of continued pre-training and instruction-tuning in enhancing LLMs’ ability to stay current with evolving knowledge. By adopting these advanced training methodologies, models like Llama-2 show improved performance in answering questions accurately and promise greater adaptability across various domains. As we move forward, the potential to expand these techniques to encompass a broader spectrum of documents and instructions opens new avenues for achieving more resilient and versatile AI systems. Yet, the journey doesn’t end here; the exploration of these methods’ applicability to other skills like reasoning and comprehension, as well as their effectiveness across different data types, remains a vital area for future research.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 38k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
You may also like our FREE AI Courses….
![]()
Vineet Kumar is a consulting intern at MarktechPost. He is currently pursuing his BS from the Indian Institute of Technology(IIT), Kanpur. He is a Machine Learning enthusiast. He is passionate about research and the latest advancements in Deep Learning, Computer Vision, and related fields.
Credit: Source link
Comments are closed.