Enhancing Autoregressive Decoding Efficiency: A Machine Learning Approach by Qualcomm AI Research Using Hybrid Large and Small Language Models
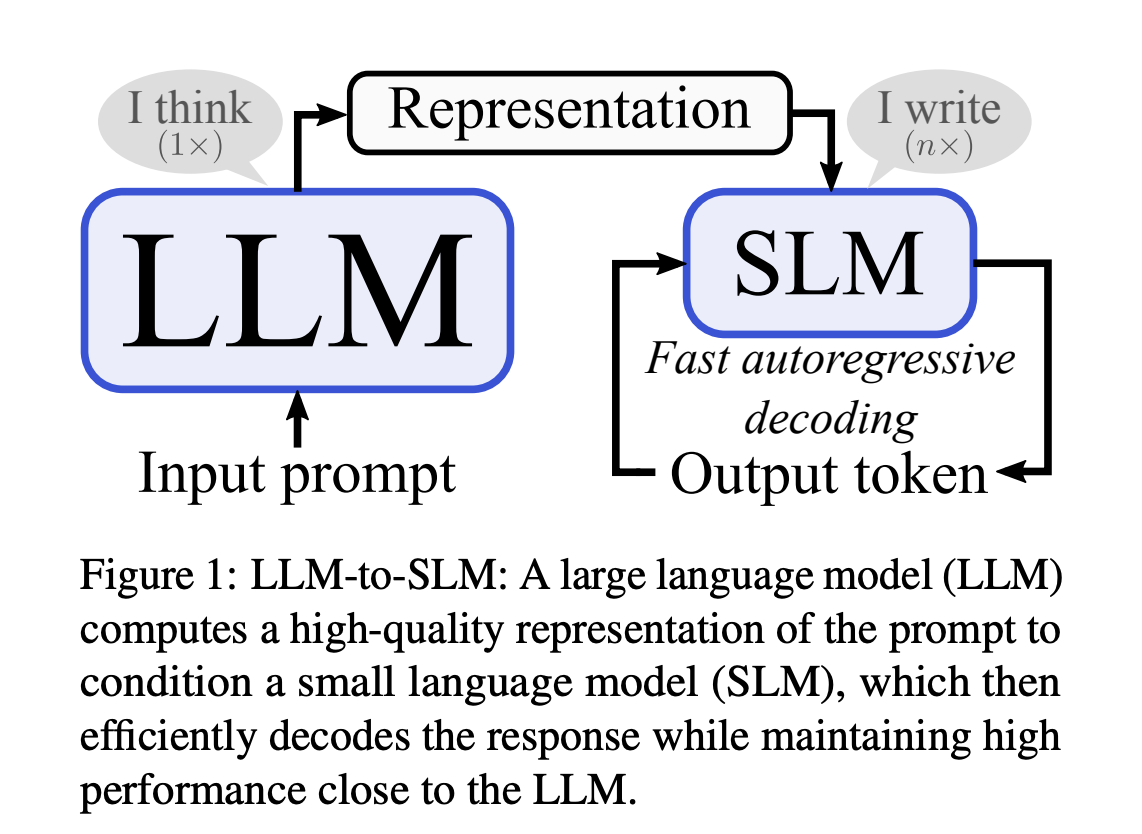
Central to Natural Language Processing (NLP) advancements are large language models (LLMs), which have set new benchmarks for what machines can achieve in understanding and generating human language. One of the primary challenges in NLP is the computational demand for autoregressive decoding in LLMs. This process, essential for tasks like machine translation and content summarization, requires substantial computational resources, making it less feasible for real-time applications or on devices with limited processing capabilities.
Current methodologies to address the computational intensity of LLMs involve various model compression techniques like pruning quantization and parallel decoding strategies. Knowledge distillation is another approach where a smaller model learns from the outputs of larger models. Parallel decoding aims to generate multiple tokens simultaneously, but it raises challenges like output inconsistencies and estimating response length. Conditional approaches are used in multimodal learning, where language models are conditioned on vision features or larger encoders. However, these approaches often compromise the model’s performance or fail to reduce the computational costs associated with autoregressive decoding significantly.
Researchers from the University of Potsdam, Qualcomm AI Research, and Amsterdam introduced a novel hybrid approach, combining LLMs with SLMs to optimize the efficiency of autoregressive decoding. This method employs a pretrained LLM to encode input prompts in parallel, then conditions an SLM to generate the subsequent response. A substantial reduction in decoding time without significantly sacrificing performance is one of the important perks of this technique.
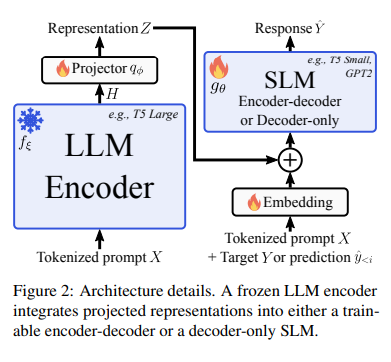
The innovative LLM-to-SLM method enhances the efficiency of SLMs by leveraging the detailed prompt representations encoded by LLMs. This process begins with the LLM encoding the prompt into a comprehensive representation. A projector then adapts this representation to the SLM’s embedding space, allowing the SLM to generate responses autoregressively. To ensure seamless integration, the method replaces or adds LLM representations into SLM embeddings, prioritizing early-stage conditioning to maintain simplicity. It aligns sequence lengths using the LLM’s tokenizer, ensuring the SLM can interpret the prompt accurately, thus marrying the depth of LLMs with the agility of SLMs for efficient decoding.
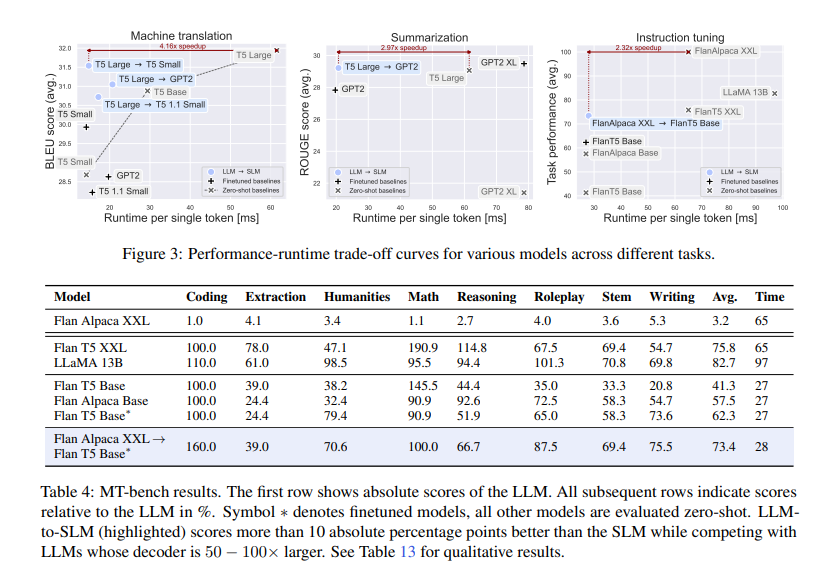
The proposed hybrid approach achieved substantial speedups of up to 4×, with minor performance penalties of 1 − 2% for translation and summarization tasks compared to the LLM. The LLM-to-SLM approach matched the performance of the LLM while being 1.5x faster, compared to a 2.3x speedup of LLM-to-SLM alone. The research also reported additional results for the translation task, showing that the LLM-to-SLM approach can be useful for short generation lengths and that its FLOPs count is similar to that of the SLM.
In conclusion, the research presents a compelling solution to the computational challenges of autoregressive decoding in large language models. By ingeniously combining the comprehensive encoding capabilities of LLMs with the agility of SLMs, the team has opened new avenues for real-time language processing applications. This hybrid approach maintains high-performance levels and significantly reduces computational demands, showcasing a promising direction for future advancements in the field.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 38k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
You may also like our FREE AI Courses….
![]()
Nikhil is an intern consultant at Marktechpost. He is pursuing an integrated dual degree in Materials at the Indian Institute of Technology, Kharagpur. Nikhil is an AI/ML enthusiast who is always researching applications in fields like biomaterials and biomedical science. With a strong background in Material Science, he is exploring new advancements and creating opportunities to contribute.
Credit: Source link
Comments are closed.