Advancing Large Language Models for Structured Knowledge Grounding with StructLM: Model Based on CodeLlama Architecture
We cannot deny the significant strides made in natural language processing (NLP) through large language models (LLMs). Still, these models often need to catch up when dealing with the complexities of structured information, highlighting a notable gap in their capabilities. The crux of the issue lies in the inherent limitations of LLMs, such as ChatGPT, which need to catch up to state-of-the-art models by a significant margin when tasked with grounding knowledge from structured sources. This deficiency underscores the need for newer, more innovative approaches to enhance LLMs’ structured knowledge grounding (SKG) capabilities, enabling them to comprehend and utilize structured data more effectively.
Various methods have been developed to solve SKG tasks, including learning contextual representations of tabular data, integrating relation-aware self-attention, and conducting pretraining over tabular/database data. Recent advancements have focused on unifying SKG tasks into a sequence-to-sequence format and using prompting frameworks on powerful LLMs for more robust and accurate task-solving. Instruction-tuning (IT) has been used to enhance the controllability and predictability of LLMs, aligning them with user expectations and improving downstream task performance.
A team of researchers from the University of Waterloo and Ohio State University have introduced StructLM, a novel model designed to bridge the gap in SKG capabilities. Leveraging a comprehensive instruction tuning dataset comprising over 1.1 million examples, StructLM is trained with the CodeLlama architecture, varying from 7B to 34B parameters, to surpass task-specific models across a spectrum of datasets.
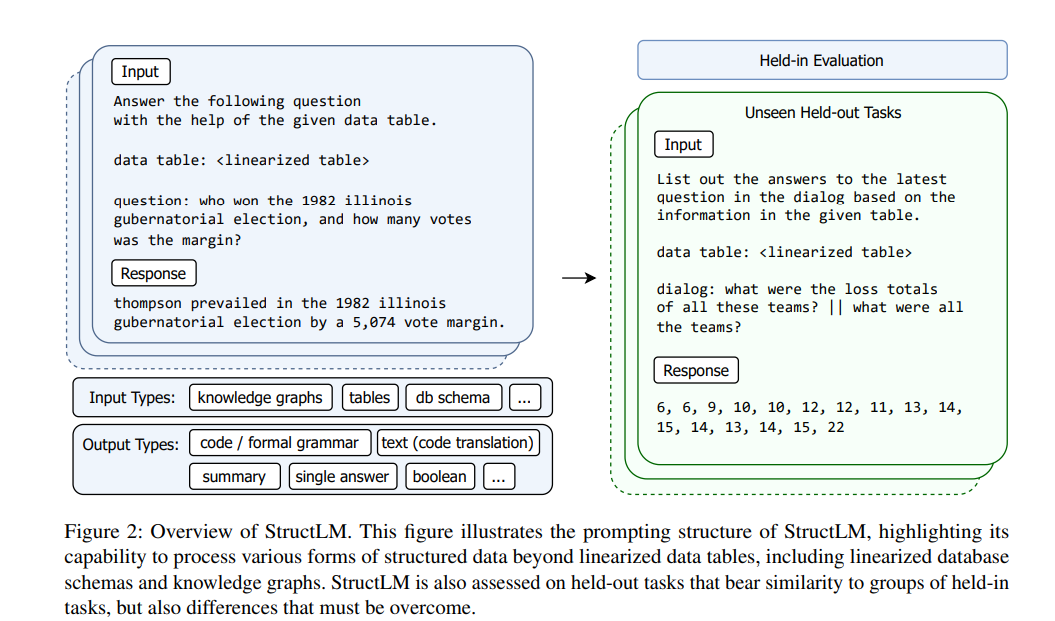
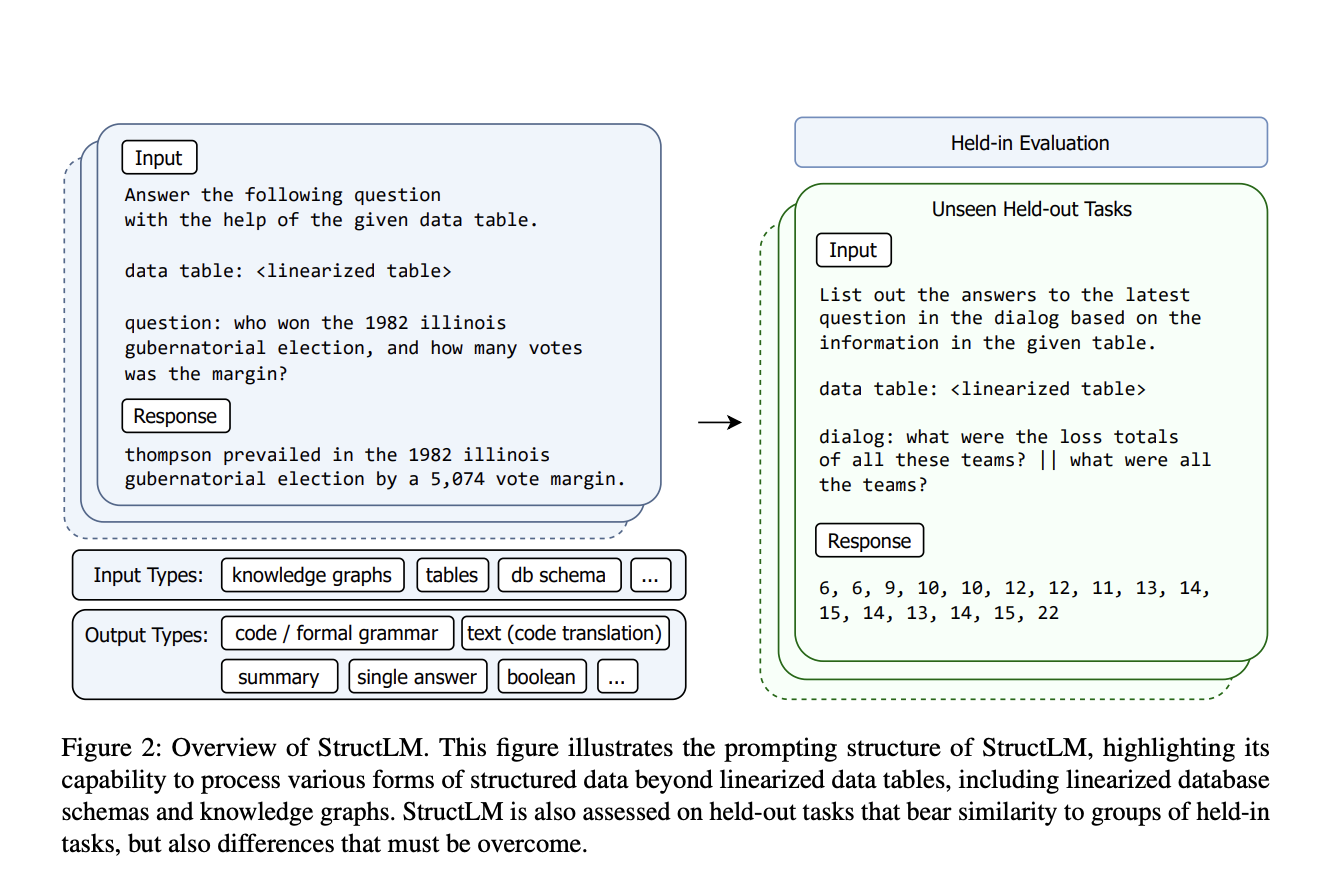
The research team curated a diverse dataset for StructLM, focusing on SKG across 25 tasks, such as data-to-text generation and table-based QA. This dataset, containing about 700,000 SKG examples, allowed them to evaluate the models on 18 held-in tasks and develop for six held-out tasks. They applied a uniform system prompt across all examples and a set of randomized instruction variations for each dataset. For finetuning, they employed A800 GPUs over three epochs, focusing on maintaining a consistent maximum sequence length for training and inference phases, ensuring comprehensive coverage and efficient processing of structured data tasks.
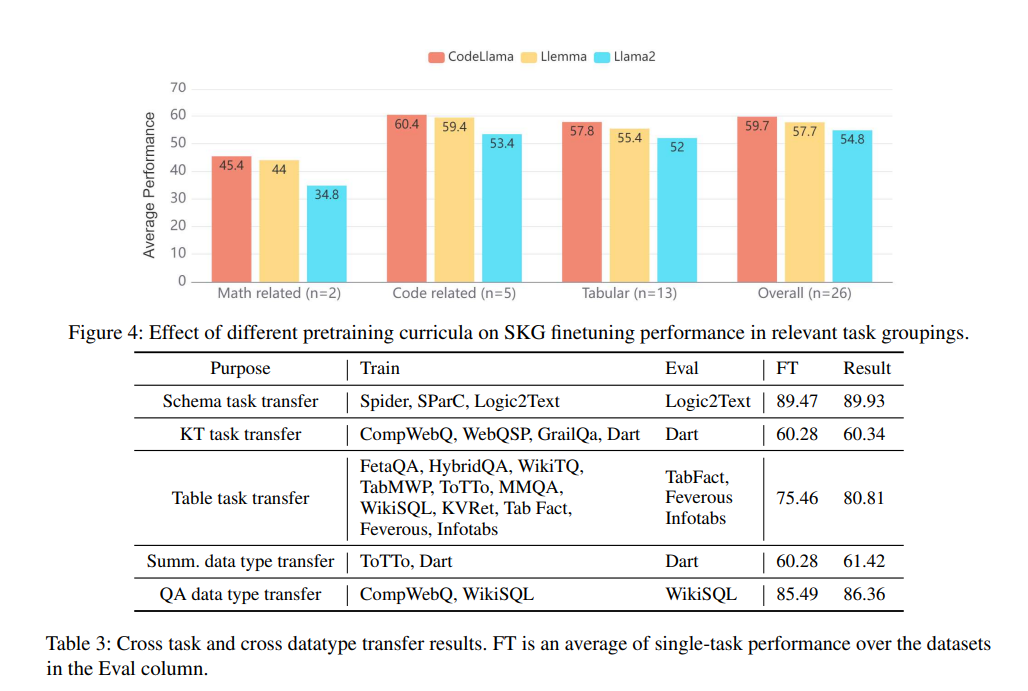
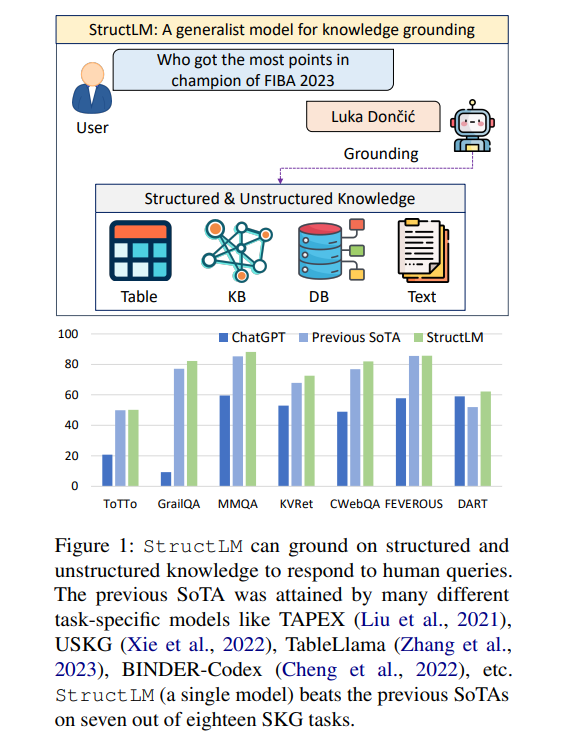
The results reveal that StructLM outperforms existing models in grounding structured and unstructured knowledge, establishing new benchmarks across 14 of 18 evaluated datasets. Finetuning on different data types with the same task yields improved results compared to single-task models, even across different knowledge types. StructLM shows strong generalization performance, outperforming ChatGPT on 5 out of 6 held-out tasks. These achievements highlight the model’s superior performance and its potential to redefine LLMs’ structured data interpretation landscape.
In conclusion, the development of StructLM is a major advancement in the efforts to improve the SKG capabilities of LLMs. It is a series of models developed based on the CodeLlama architecture. It surpasses task-specific models on 14 of 18 evaluated datasets and establishes new state-of-the-art achievements on 7 SKG tasks. Despite these advancements, the researchers acknowledge limitations in dataset diversity and evaluation metrics, underscoring the ongoing need for broader and more heterogeneous structured data types to further robust SKG model development.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 38k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
You may also like our FREE AI Courses….
![]()
Nikhil is an intern consultant at Marktechpost. He is pursuing an integrated dual degree in Materials at the Indian Institute of Technology, Kharagpur. Nikhil is an AI/ML enthusiast who is always researching applications in fields like biomaterials and biomedical science. With a strong background in Material Science, he is exploring new advancements and creating opportunities to contribute.
Credit: Source link
Comments are closed.