Unlocking the Full Potential of Vision-Language Models: Introducing VISION-FLAN for Superior Visual Instruction Tuning and Diverse Task Mastery
Recent advances in vision-language models (VLMs) have led to impressive AI assistants capable of understanding and responding to both text and images. However, these models still have limitations that researchers are working to address. Two of the key challenges are:
- Limited Task Diversity: Many existing VLMs are trained on a narrow range of tasks and are fine-tuned on instruction datasets synthesized by large language models. This can lead to poor generalization and unexpected or incorrect outputs.
- Synthetic Data Bias: Datasets created by large language models can introduce errors and biases, causing the VLM’s responses to stray from human preferences.

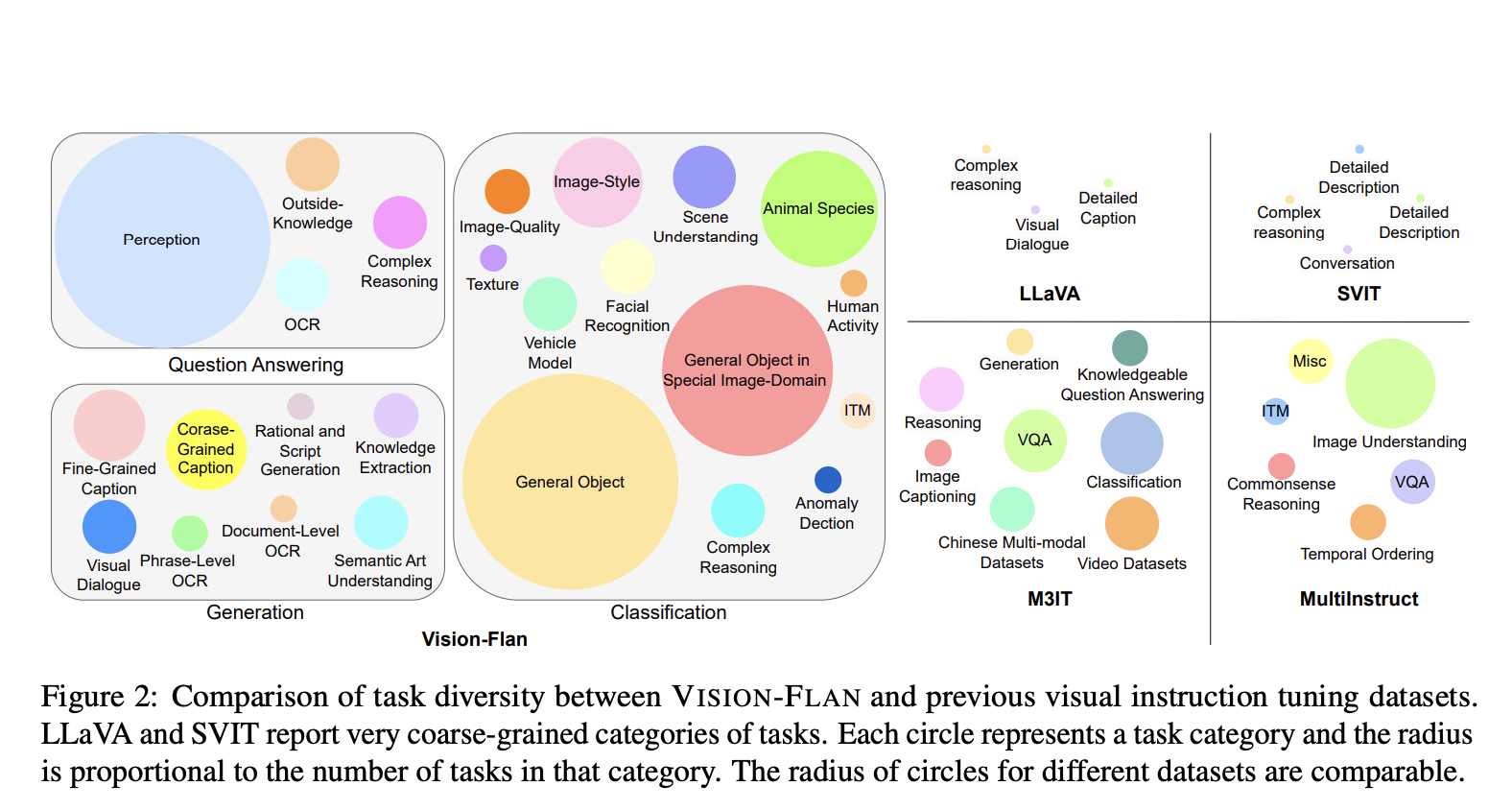
To tackle these challenges, in this paper, researchers have developed VISION-FLAN, a groundbreaking new dataset designed for fine-tuning VLMs on a wide variety of tasks. What makes VISION-FLAN unique is its sheer diversity. It contains a meticulously curated selection of 187 tasks drawn from academic datasets, encompassing everything from object detection and image classification to complex graph analysis and geometric reasoning (Figure 1).
The researchers employed a rigorous annotation process to ensure the quality and consistency of VISION-FLAN. Expert annotators were chosen based on their qualifications, and each task was carefully designed with clear instructions and validated for correctness.
Researchers have used VISION-FLAN in a novel two-stage fine-tuning framework:
- Stage 1: Building Task Proficiency A VLM is first trained on the entire VISION-FLAN dataset, learning to handle diverse visual and language-based problems. This results in the VISION-FLAN BASE model.
- Stage 2: Aligning with Human Preferences The VISION-FLAN BASE model is further fine-tuned on a small dataset of GPT-4 synthesized instructions to teach it how to produce more detailed and helpful responses that match what humans actually expect. This yields the final VISION-FLAN CHAT model.
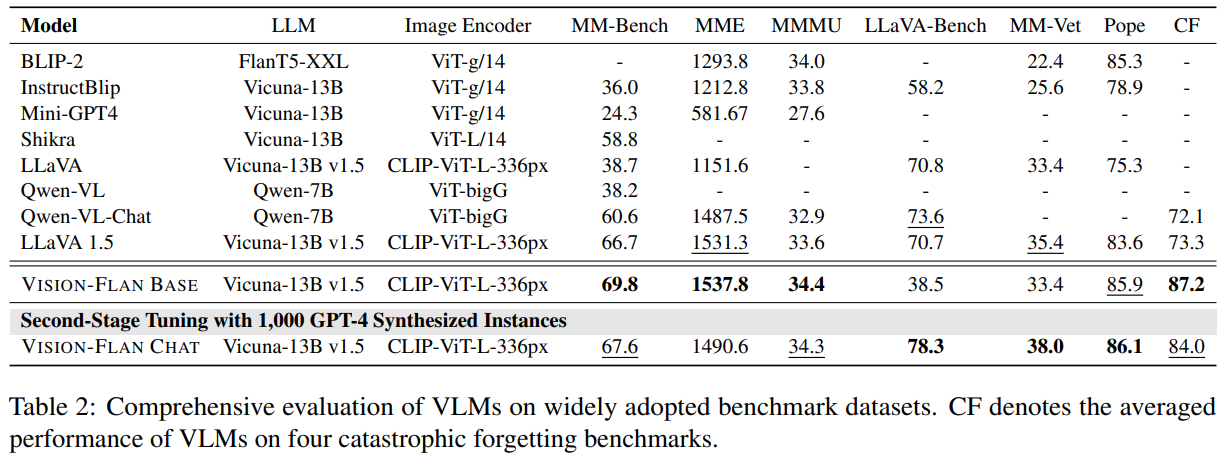
The results are compelling (Table 2). When evaluated on a range of real-world benchmarks, VISION-FLAN BASE outperforms other state-of-the-art VLMs on various tasks while reducing incorrect or misleading responses. VISION-FLAN CHAT builds on this strong foundation and, with just a small amount of synthetic data, further improves the quality of responses, aligning them more closely with human expectations. Key Insights VISION-FLAN highlights the importance of both task diversity and human-centeredness in VLM development:
- Diversity Matters: Exposing VLMs to a wide range of challenges during training increases their overall capabilities and makes them more robust.
- Humans Still Matter: While large language models like GPT-4 can synthesize instructions, it’s crucial to use human-labeled data to ensure responses are helpful and accurate.
In conclusion, VISION-FLAN is a major step forward for vision-language modeling, demonstrating that training on a well-curated diverse task set can lead to more generalizable and reliable AI assistants. This work also has some limitations, such as being focused on English and single-image tasks, but provides valuable insights and a foundation for future research. Exciting potential directions include multilingual models, multi-image or video tasks, and exploring diverse VLM architectures.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 38k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
You may also like our FREE AI Courses….
![]()
Vineet Kumar is a consulting intern at MarktechPost. He is currently pursuing his BS from the Indian Institute of Technology(IIT), Kanpur. He is a Machine Learning enthusiast. He is passionate about research and the latest advancements in Deep Learning, Computer Vision, and related fields.
Credit: Source link
Comments are closed.