Redefining Compact AI: MBZUAI’s MobiLlama Delivers Cutting-Edge Performance in Small Language Models Domain
In recent years, the AI community has witnessed a significant surge in developing large language models (LLMs) such as ChatGPT, Bard, and Claude. These models have demonstrated exceptional capabilities, from enhancing dialogue systems to improving logical reasoning and coding. However, their vast size and computational requirements often render them impractical for resource-constrained environments. This challenge has catalyzed a shift towards Small Language Models (SLMs), which promise to deliver decent performance while being significantly more manageable in terms of computational resources.
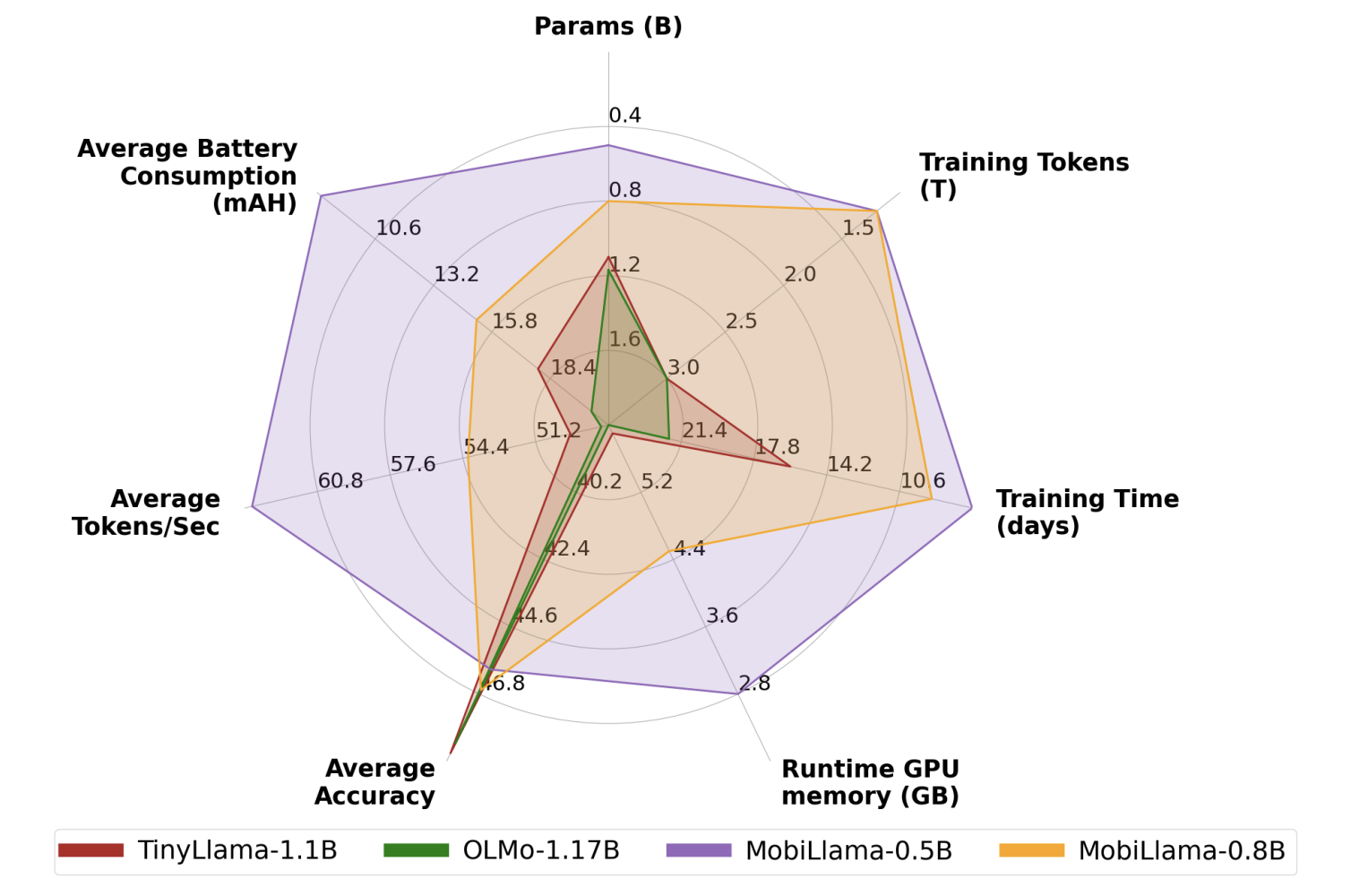
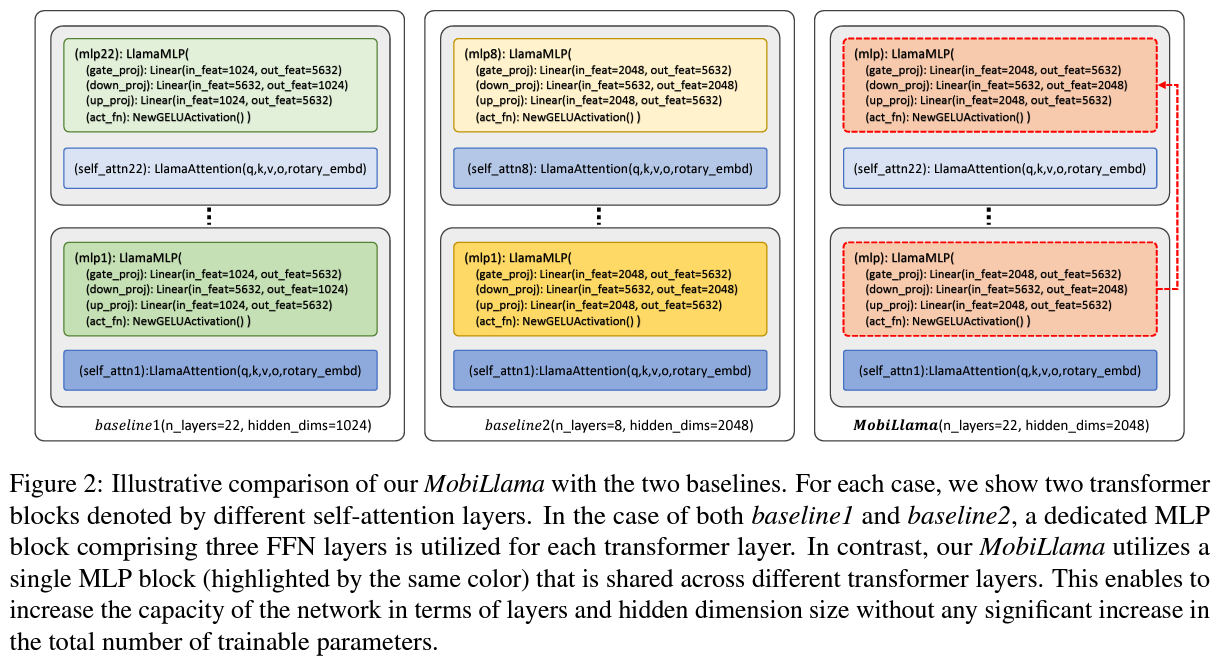
Researchers from the Mohamed bin Zayed University of AI and their colleagues from the Australian National University, Aalto University, The University of Melbourne, and Linköping University have made a groundbreaking contribution to this field by developing MobiLlama. This 0.5 billion parameter SLM stands out for its innovative approach to model architecture, specifically its utilization of a shared feedforward network (FFN) design across all transformer blocks. The smaller model size and computational footprint make it suitable for low-power devices.
MobiLlama’s methodology is a testament to the ingenuity of its creators. Rather than simply scaling down a larger LLM, which often leads to diminished performance, the team devised a way to maintain the model’s efficiency and accuracy. By sharing FFN layers across transformer blocks, they reduced redundancy within the model, significantly reducing the number of parameters without compromising the model’s ability to understand and generate language. This technique allows MobiLlama to offer computational efficiency and fast inference times, which are crucial for applications on low-powered devices and in scenarios where quick response times are essential.
The performance of MobiLlama is nothing short of impressive. In comparative benchmarks, MobiLlama’s 0.5B model outperformed existing SLMs of similar size on nine different benchmarks, achieving a notable gain of 2.4% in average performance. These results underscore the model’s ability to match and exceed its peers’ capabilities, highlighting the effectiveness of the shared FFN design in enhancing the model’s performance. Furthermore, the development of a 0.8B SLM variant of MobiLlama, leveraging a wider shared-FFN scheme, showcases the scalability of this approach, with the model achieving top performance among SLMs with fewer than 1 billion parameters.
The implications of MobiLlama’s development extend far beyond the technical achievements. The research team has provided a valuable resource to the wider AI community by offering a fully transparent, open-source SLM. This transparency ensures that MobiLlama can serve as a foundation for further research and development, fostering innovation and collaboration among researchers and developers. The open-source nature of MobiLlama, complete with detailed documentation of the training data pipeline, code, and model weights, sets a new standard for accessibility and reproducibility in AI research.
In conclusion, MobiLlama represents a significant advancement in the quest for efficient, scalable AI models. Its unique architecture, impressive performance, and commitment to transparency make it a pioneering solution for deploying advanced language models on resource-constrained devices. As the AI community continues to grapple with model size and computational demand challenges, MobiLlama serves as a beacon of innovation, demonstrating that achieving more with less is possible. The researchers’ dedication to open-source principles further amplifies the impact of their work, paving the way for a future where advanced AI technologies are within reach of a broader range of applications and devices, democratizing access to cutting-edge AI tools.
Check out the Paper and Github. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 38k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
You may also like our FREE AI Courses….
![]()
Muhammad Athar Ganaie, a consulting intern at MarktechPost, is a proponet of Efficient Deep Learning, with a focus on Sparse Training. Pursuing an M.Sc. in Electrical Engineering, specializing in Software Engineering, he blends advanced technical knowledge with practical applications. His current endeavor is his thesis on “Improving Efficiency in Deep Reinforcement Learning,” showcasing his commitment to enhancing AI’s capabilities. Athar’s work stands at the intersection “Sparse Training in DNN’s” and “Deep Reinforcemnt Learning”.
Credit: Source link
Comments are closed.