Microsoft Researchers Propose A Novel Text Diffusion Model (TREC) that Mitigates the Degradation with Reinforced Conditioning and the Misalignment by Time-Aware Variance Scaling
In the ever-evolving field of computational linguistics, the quest for models that can seamlessly generate human-like text has led researchers to explore innovative techniques beyond traditional frameworks. One of the most promising avenues in recent times has been the exploration of diffusion models, previously lauded for their success in visual and auditory domains and their potential in natural language generation (NLG). These models have opened up new possibilities for creating text that is not only contextually relevant and coherent but exhibits a remarkable degree of variability and adaptiveness to different styles and tones, a hurdle many earlier methods struggled to overcome efficiently.
Previous text generation methods often needed to work on producing content that could adapt to diverse requirements without extensive retraining or manual interventions. This challenge was particularly pronounced in applications requiring high versatility, such as dynamic content creation for websites or personalized dialogue systems, where the context and style could shift rapidly.
Diffusion models have emerged as a beacon of hope in this landscape, celebrated for their ability to refine outputs towards high-quality solutions iteratively. Their application in NLG, however, has yet to be straightforward, primarily due to the discrete nature of language. This discreteness complicates the diffusion process, which relies on gradual transformations, making it a less intuitive fit for text than images or audio.
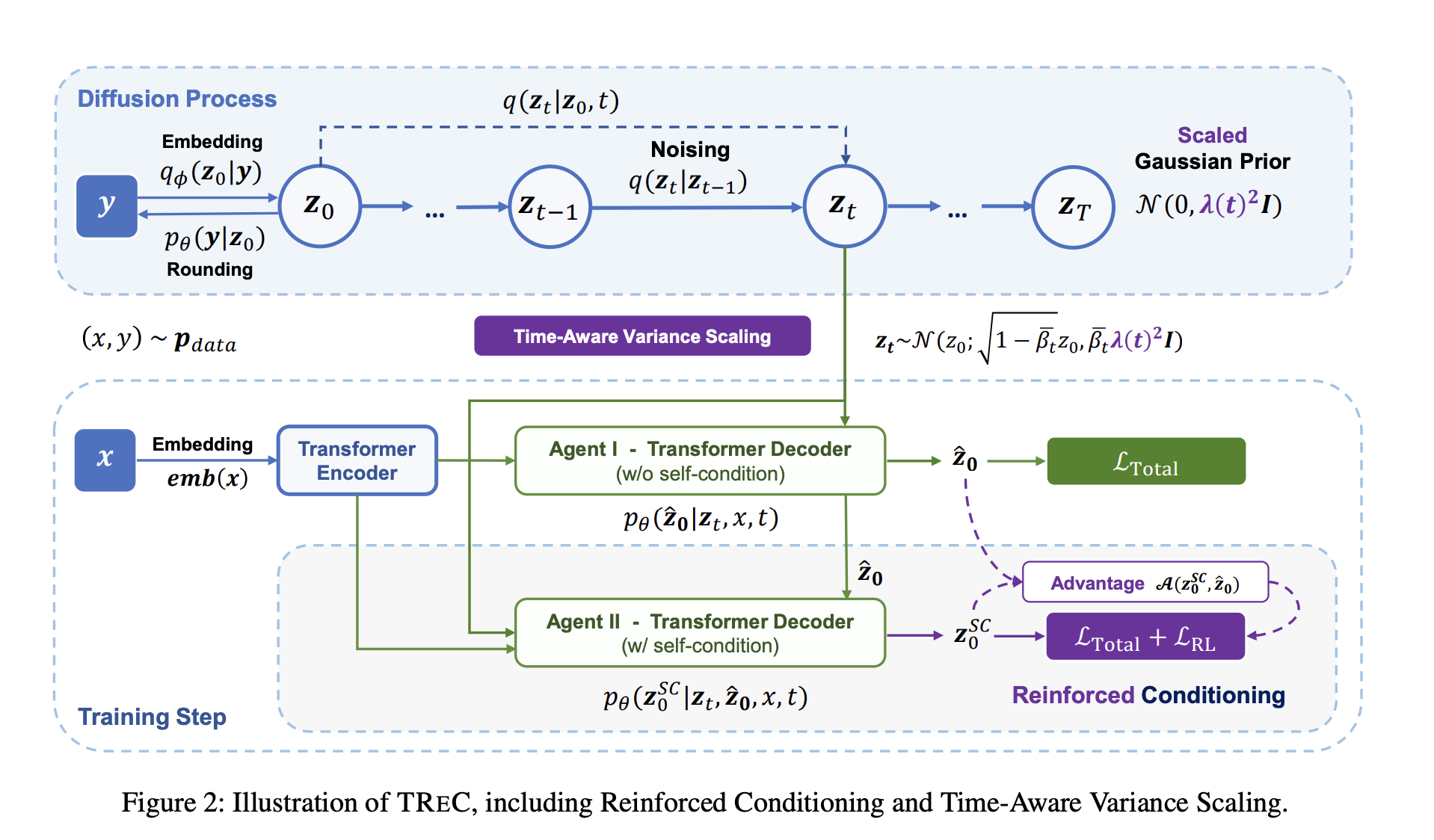
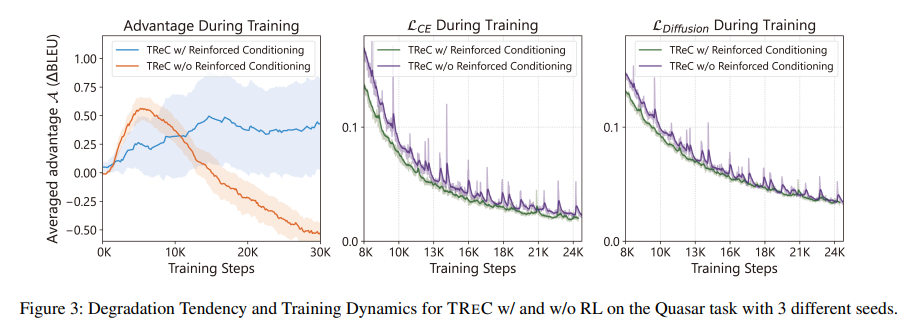
Researchers from Peking University and Microsoft Corporation introduced TREC (Text Reinforced Conditioning), a novel Text Diffusion model devised to bridge this gap. It targets the specific challenges posed by the discrete nature of text, aiming to leverage the iterative refinement prowess of diffusion models to enhance text generation. TREC introduces Reinforced Conditioning, a strategy designed to combat self-conditioning degradation noted during training. This degradation often results in models that fail to fully utilize the iterative refinement potential of diffusion, relying too heavily on the quality of initial steps and thereby limiting the model’s effectiveness.
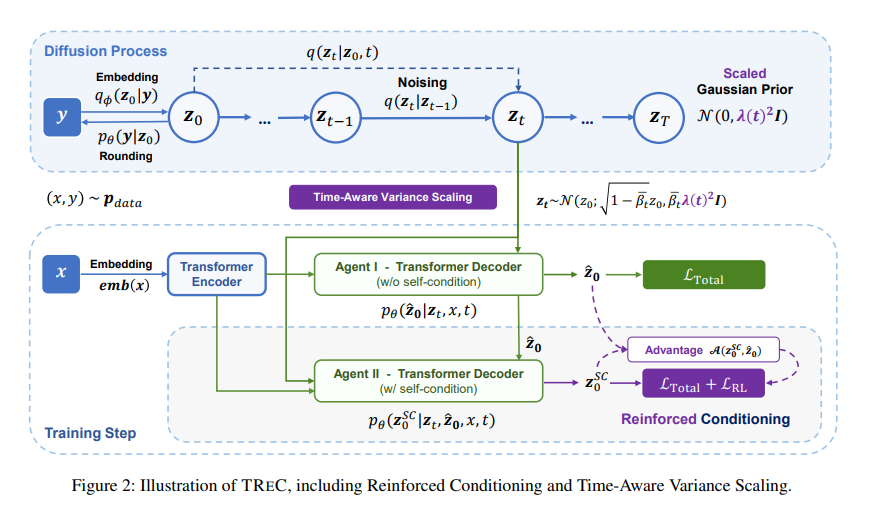
TREC employs Time-Aware Variance Scaling, an innovative approach to align the training and sampling processes more closely. This alignment is crucial for maintaining consistency in the model’s output quality, ensuring that the refinement process during sampling reflects the conditions under which the model was trained. TREC significantly enhances the model’s ability to produce high-quality, contextually relevant text sequences by addressing these two critical issues.
The efficacy of TREC has been rigorously tested across a spectrum of NLG tasks, including machine translation, paraphrasing, and question generation. The results are nothing short of impressive, with TREC not only holding its ground against both autoregressive and non-autoregressive baselines but also outperforming them in several instances. This performance underscores TREC‘s ability to harness the full potential of diffusion processes for text generation, offering significant improvements in the quality and contextual relevance of the generated text.
What sets TREC apart is its novel methodology and the tangible outcomes it achieves. In machine translation, TREC has demonstrated its superiority by delivering more accurate and nuanced translations than those produced by established models. In paraphrasing and question generation tasks, TREC‘s outputs are varied and contextually apt, showcasing a level of adaptability and coherence that marks a significant advancement in NLG.
In conclusion, TRECs development is a landmark achievement in pursuing models capable of generating human-like text. By addressing the intrinsic challenges of text diffusion models, namely, the degradation during training and misalignment during sampling, TREC sets a new standard for text generation and opens up new avenues for research and application in computational linguistics. Its success across various NLG tasks illustrates the model’s robustness and versatility, heralding a future where machines can generate text that is indistinguishable from that written by humans, tailored to an array of styles, tones, and contexts. This breakthrough is a testament to the ingenuity and forward-thinking of the researchers behind TREC, offering a glimpse into the future of artificial intelligence in language generation.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 38k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
You may also like our FREE AI Courses….
![]()
Nikhil is an intern consultant at Marktechpost. He is pursuing an integrated dual degree in Materials at the Indian Institute of Technology, Kharagpur. Nikhil is an AI/ML enthusiast who is always researching applications in fields like biomaterials and biomedical science. With a strong background in Material Science, he is exploring new advancements and creating opportunities to contribute.
Credit: Source link
Comments are closed.