Decoding the DNA of Large Language Models: A Comprehensive Survey on Datasets, Challenges, and Future Directions
Developing and refining Large Language Models (LLMs) has become a focal point of cutting-edge research in the rapidly evolving field of artificial intelligence, particularly in natural language processing. These sophisticated models, designed to comprehend, generate, and interpret human language, rely on the breadth and depth of their training datasets. The essence and efficacy of LLMs are deeply intertwined with the quality, diversity, and scope of these datasets, making them a cornerstone for advancements in the field. As the complexity of human language and the demands on LLMs to mirror this complexity grow, the quest for comprehensive and varied datasets has led researchers to pioneer innovative methods for dataset creation and optimization, aiming to capture the multifaceted nature of language across various contexts and domains.
Existing methodologies for assembling datasets for LLM training have traditionally hinged on amassing large text corpora from the web, literature, and other public text sources to encapsulate a wide spectrum of language usage and styles. While effective in creating a base for model training, this foundational approach confronts substantial challenges, notably in ensuring data quality, mitigating biases, and adequately representing lesser-known languages and dialects. A recent survey by researchers from South China University of Technology, INTSIG Information Co., Ltd, and INTSIG-SCUT Joint Lab on Document Analysis and Recognition has introduced novel dataset compilation and enhancement strategies to address these challenges. By leveraging both conventional data sources and cutting-edge techniques, researchers aim to bolster the performance of LLMs across a swath of language processing tasks, underscoring the pivotal role of datasets in the development lifecycle of LLMs.
A significant innovation in this domain is creating a specialized tool to refine the dataset compilation process. Utilizing machine learning algorithms, this tool efficiently sifts through text data, identifying and categorizing content that meets high-quality standards. It integrates mechanisms to minimize dataset biases, promoting a more equitable and representative foundation for language model training. The effectiveness of these advanced methodologies is corroborated through rigorous testing and evaluation, demonstrating notable enhancements in LLM performance, especially in tasks demanding nuanced language understanding and contextual analysis.
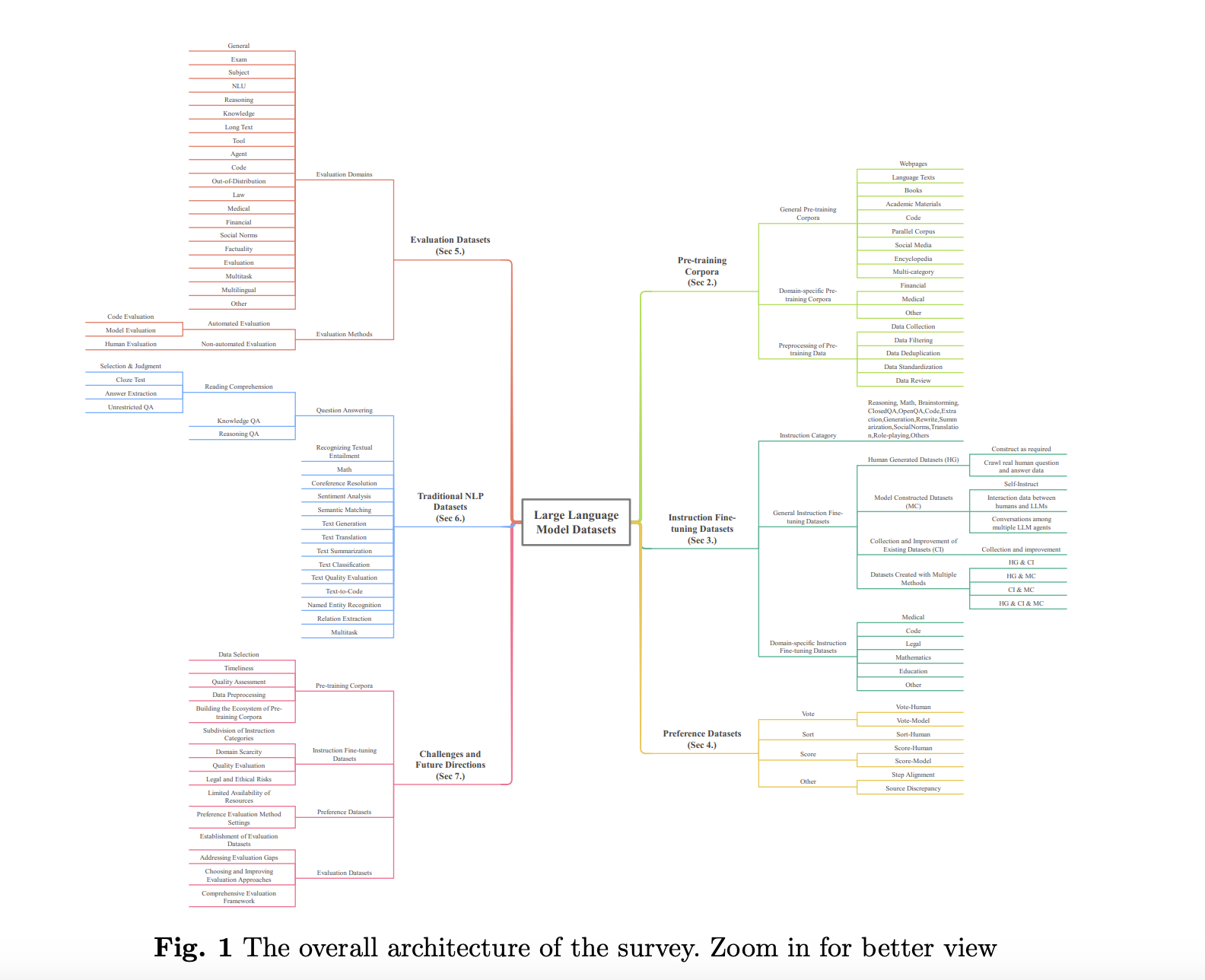
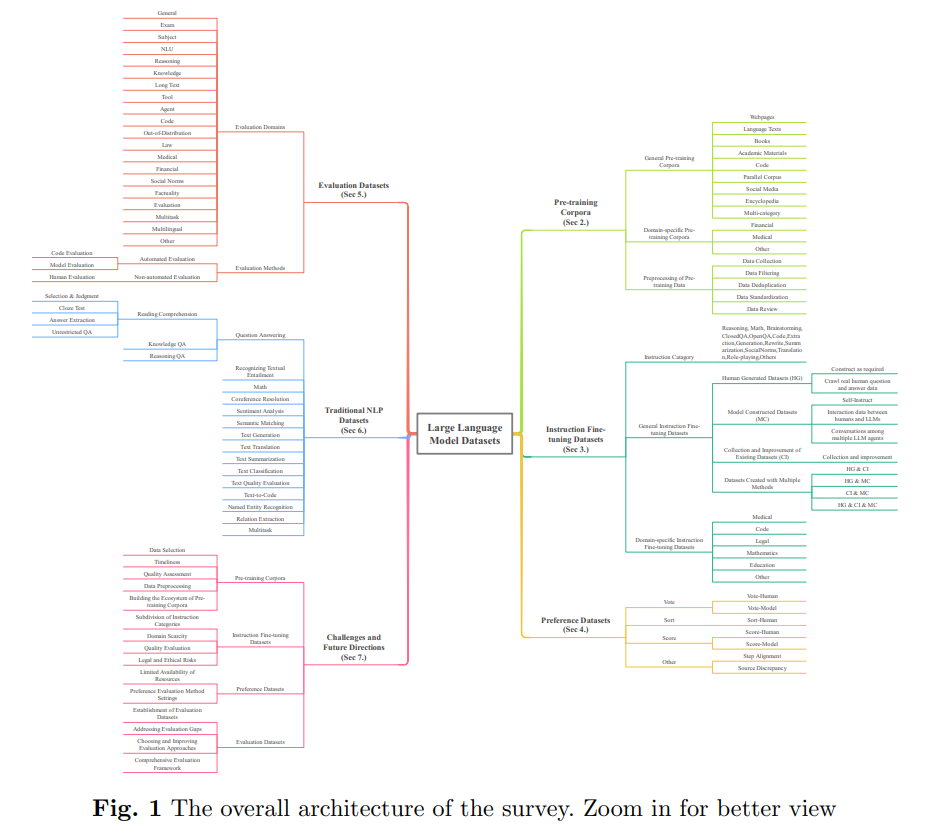
The exploration of Large Language Model datasets unveils their fundamental role in propelling the field forward, acting as the essential roots of LLMs’ growth. By meticulously analyzing the landscape of datasets across five critical dimensions – pre-training corpora, instruction fine-tuning datasets, preference datasets, evaluation datasets, and traditional NLP datasets – this survey sheds light on the existing challenges and charts potential pathways for future endeavors in dataset development. The survey delineates the extensive scale of data involved, with pre-training corpora alone exceeding 774.5 TB and other datasets amassing over 700 million instances, marking a significant milestone in our understanding and optimization of dataset usage in LLM advancement.
The survey elaborates on the intricate data handling processes crucial for LLM development, spanning from data crawling to the creation of instruction fine-tuning datasets. It outlines a comprehensive data collection, filtering, deduplication, and standardization methodology to ensure the relevance and quality of data destined for LLM training. This meticulous approach, encompassing encoding detection, language detection, privacy compliance, and regular updates, underscores the complexity and importance of preparing data for effective LLM training.

The survey navigates through instruction fine-tuning datasets, essential for honing LLMs’ ability to follow human instructions accurately. It presents various methodologies for constructing these datasets, from manual efforts to model-generated content, categorizing them into general and domain-specific types to bolster model performance across multiple tasks and domains. This detailed analysis extends to evaluating LLMs across diverse domains, showcasing a multitude of datasets designed to test models on functions such as natural language understanding, reasoning, knowledge retention, and more.
In addition to domain-specific evaluations, the survey ventures into question-answering tasks, distinguishing between unrestricted QA, knowledge QA, and reasoning QA, and highlights the importance of datasets like SQuAD, Adversarial QA, and others that present LLMs with complex, authentic comprehension challenges. It also examines datasets focused on mathematical assignments, coreference resolution, sentiment analysis, semantic matching, and text generation, reflecting the breadth and complexity of datasets to evaluate and enhance LLMs across various aspects of natural language processing.
The culmination of the survey brings forth discussions on the current challenges and future directions in LLM-related dataset development. It emphasizes the critical need for diversity in pre-training corpora, the creation of high-quality instruction fine-tuning datasets, the significance of preference datasets for model output decisions, and the crucial role of evaluation datasets in ensuring LLMs’ reliability, practicality, and safety. The call for a unified framework for dataset development and management accentuates the foundational significance of datasets in fostering the growth and sophistication of LLMs, likening them to the vital root system that sustains the towering trees in the dense forest of artificial intelligence advancements.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 38k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
You may also like our FREE AI Courses….
![]()
Hello, My name is Adnan Hassan. I am a consulting intern at Marktechpost and soon to be a management trainee at American Express. I am currently pursuing a dual degree at the Indian Institute of Technology, Kharagpur. I am passionate about technology and want to create new products that make a difference.
Credit: Source link
Comments are closed.