Meta AI Introduces Branch-Train-MiX (BTX): A Simple Continued Pretraining Method to Improve an LLM’s Capabilities
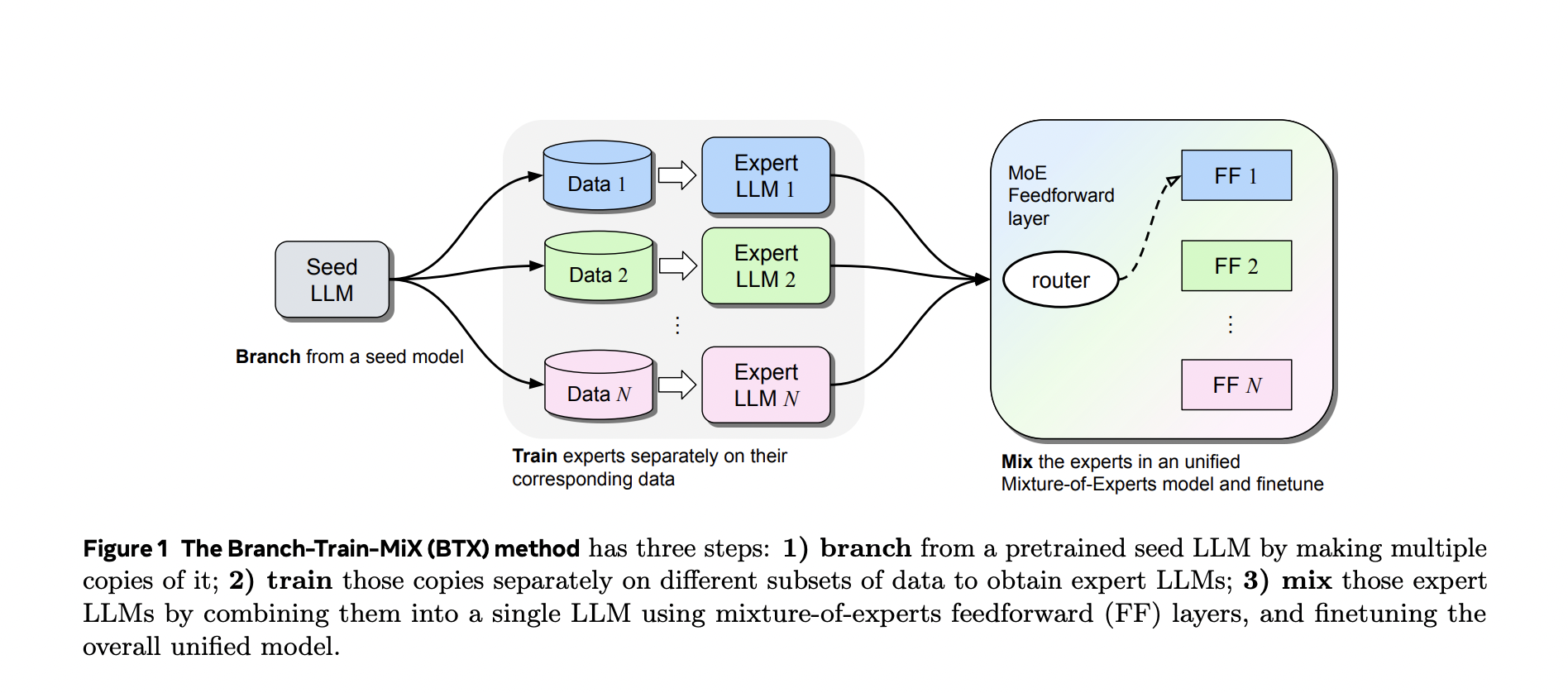
In the landscape of artificial intelligence, developing Large Language Models (LLMs) has been a cornerstone for various applications that can range from natural language processing to code generation. The relentless pursuit of advancing these models has introduced new methodologies aimed at refining their capabilities and efficiency.
Training LLMs traditionally entail a considerable allocation of computational resources and data, often resulting in a steep trade-off between breadth and depth of knowledge. The challenge of efficiently scaling their abilities becomes increasingly pronounced. Previous training paradigms have usually led to a bottleneck, where the addition of specialized expertise is met with diminishing returns on investment in terms of computational resources and training time.
Recent methodologies have addressed this issue by segmenting the training process, focusing on developing domain-specific expertise within the models. However, These segmented training processes have faced their own challenges, particularly in balancing specialized training with the maintenance of a model’s general capabilities. Integrating specialized knowledge often comes at the expense of a model’s adaptability and efficiency, creating a gap in the quest for a versatile and scalable LLM.
Researchers from FAIR at Meta introduce Branch-Train-Mix (BTX), a pioneering strategy at the confluence of parallel training, and the Mixture-of-Experts (MoE) model. BTX distinguishes itself by initiating parallel training for domain-specific experts. This is followed by a strategic amalgamation of these experts into a unified MoE framework to enhance the model’s overall efficacy and versatility.
The BTX methodology is characterized by its innovative approach to integrating domain expertise into a cohesive model. By first branching out into parallel training pathways, the method allows for focused expertise development in individual domains. These parallel paths increase efficiency and prevent the dilution of specialized knowledge. The subsequent phase of the process involves meticulously integrating these domain-specific models into a singular MoE model through parameter merging and fine-tuning. This integrated model can then leverage specialized knowledge across various domains while maintaining its foundational capabilities.
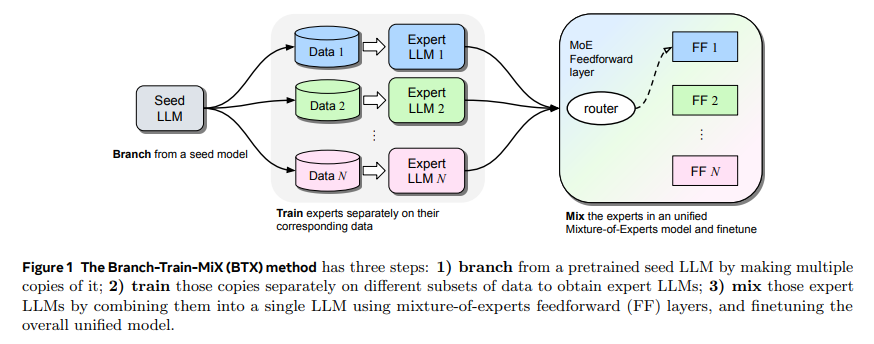
The efficacy of the BTX model was tested across a broad spectrum of benchmarks, showcasing its ability to retain and enhance performance in specialized domains. This was achieved with impressive efficiency, minimizing the additional computational demands typically associated with such enhancements. The BTX method’s performance underscores its potential as a scalable and adaptable approach to LLM training, presenting a significant advancement in the field.
This research encapsulates a significant stride towards optimizing the training of LLMs, offering a glimpse into the future of artificial intelligence development. The BTX method represents a nuanced approach to enhancing the depth and breadth of LLM capabilities, marking a pivotal shift towards more efficient, scalable, and adaptable training paradigms.
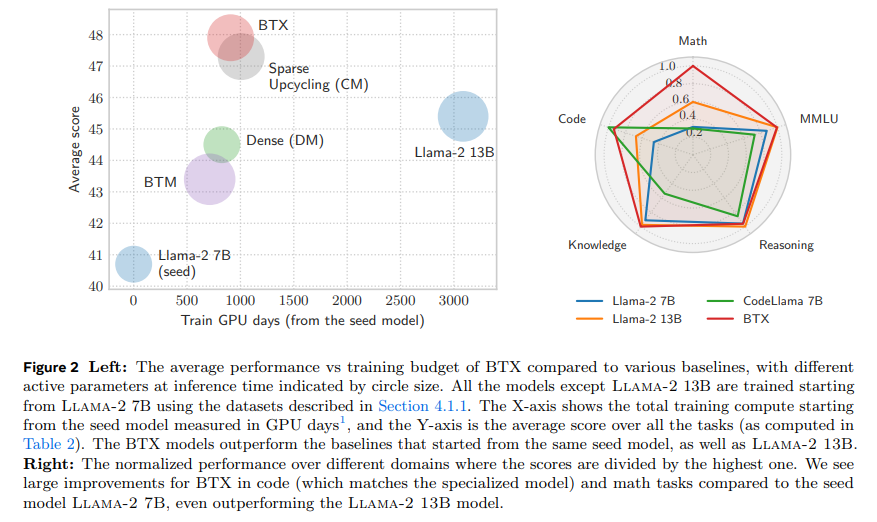
In conclusion, some key takeaways from the research include:
- Innovative Training Approach: The BTX strategy introduces a novel LLM enhancement method through parallel training and integration into a Mixture-of-Experts model, emphasizing efficiency and domain-specific enhancement.
- Enhanced Model Performance: Demonstrated superior performance in domain-specific benchmarks while maintaining general capabilities, showcasing an optimal balance between specialization and adaptability.
- Optimal Efficiency: Achieved significant enhancements without the proportional increase in computational demand, illustrating the method’s efficiency and scalability.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 38k+ ML SubReddit
![]()
Sana Hassan, a consulting intern at Marktechpost and dual-degree student at IIT Madras, is passionate about applying technology and AI to address real-world challenges. With a keen interest in solving practical problems, he brings a fresh perspective to the intersection of AI and real-life solutions.
Credit: Source link
Comments are closed.