Can Continual Learning Strategies Outperform Traditional Re-Training in Large Language Models? This AI Research Unveils Efficient Machine Learning Approaches
Machine learning is witnessing rapid advancements, especially in the domain of large language models (LLMs). These models, which underpin various applications from language translation to content creation, require regular updates with new data to stay relevant and effective. Updating these models meant re-training them from scratch with each new dataset, which is time-consuming and requires significant computational resources. This approach poses a substantial barrier to maintaining cutting-edge models, as the computational costs can quickly become unsustainable.
Researchers from Université de Montréal, Concordia University, Mila, and EleutherAI have been exploring various strategies to streamline the model updating process. Among these, “continual pre-training” stands out as a promising solution. This approach aims to update LLMs by integrating new data without starting the training process from zero, thus preserving the knowledge previously acquired by the model. The key challenge in this domain is introducing new information to a model without erasing its existing knowledge, a problem known as catastrophic forgetting.
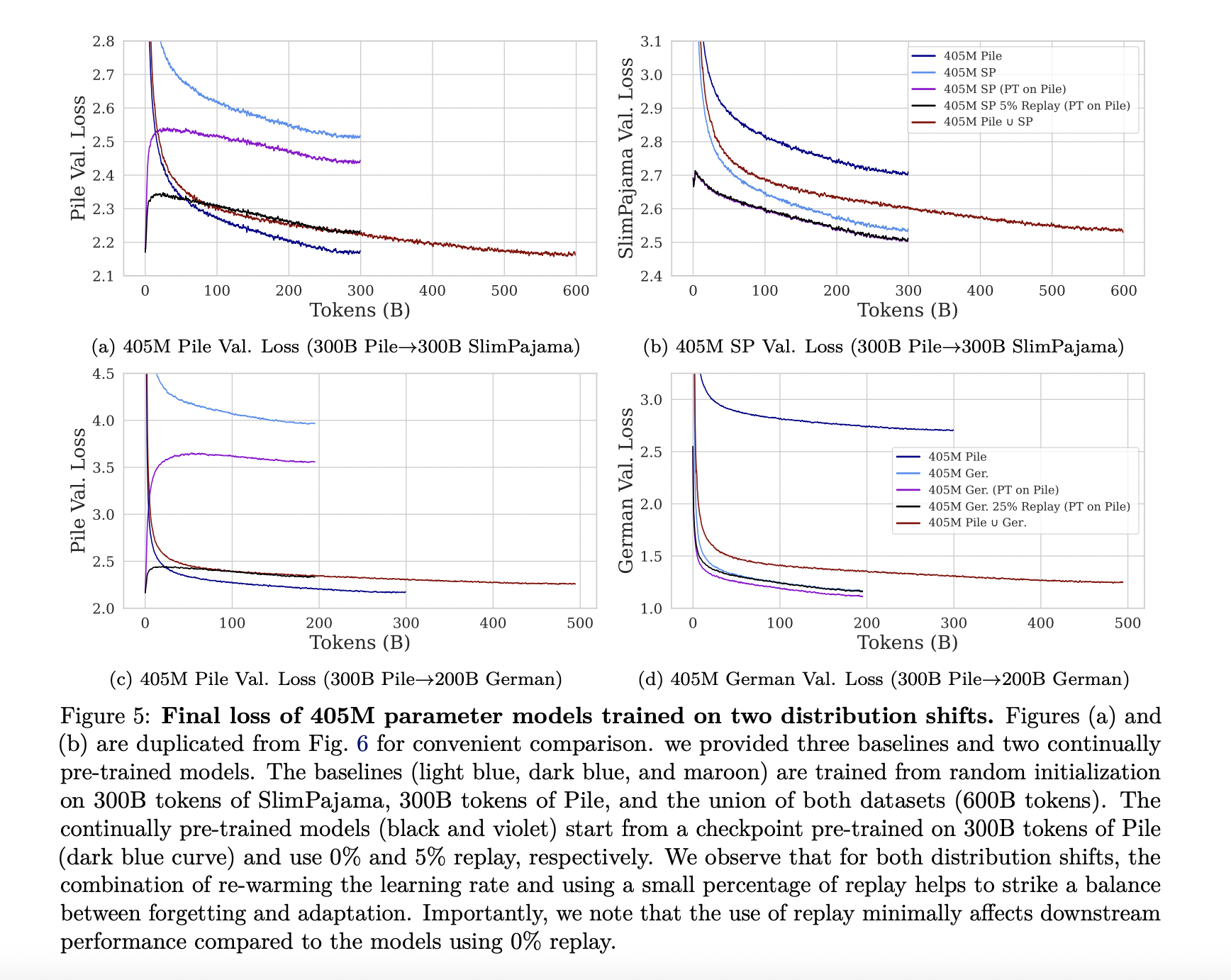
The study focuses on a sophisticated strategy involving learning rate adjustments and replaying a subset of the previously learned data. This strategy’s essence lies in its ability to adapt the model to new datasets while significantly reducing the computational load compared to traditional re-training methods. The research highlights the effectiveness of adjusting the learning rate through a process known as re-warming and re-decaying, coupled with replaying a fraction of old data to help the model retain previously learned information.
The approach proposed by the researchers offers several compelling advantages:
- It demonstrates that LLMs can be efficiently updated with new data through a simple and scalable method.
- The model can adapt to new datasets without losing significant knowledge from the previous datasets by employing a combination of learning rate re-adjustments and selective data replay.
- The method proves effective across various scenarios, including the transition between datasets of different languages, showcasing its versatility.
- This approach matches the performance of fully re-trained models, achieving this with only a fraction of the computational resources.
In detail, the technique involves precisely manipulating the learning rate to facilitate the model’s adaptation to new datasets. This is achieved by increasing the learning rate (re-warming) at the onset of training on new data and gradually decreasing it after that (re-decaying). A carefully selected portion of the previous dataset is replayed during training. This dual strategy enables the model to integrate new information efficiently while mitigating the risk of catastrophic forgetting.
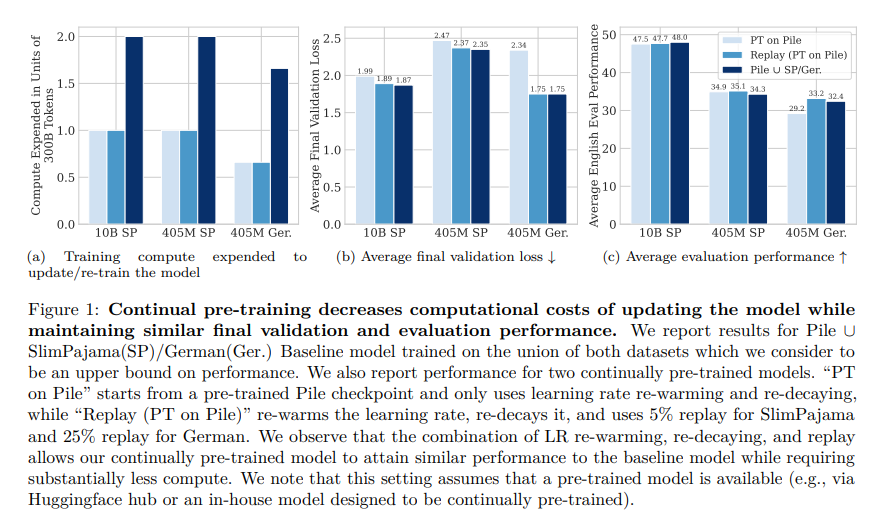
The study’s findings show that their method achieves comparable results to the traditional, computationally intensive re-training approach and does so more efficiently. This research advances in continual learning, presenting a viable and cost-effective method for updating LLMs. By reducing the computational demands of the updating process, this approach makes it more feasible for organizations to maintain current and high-performing models.
In conclusion, this research provides a novel solution to the computational challenges of updating LLMs. Through a combination of learning rate adjustments and data replay, the study demonstrates a method that maintains the relevancy and effectiveness of LLMs in the face of evolving datasets. This approach not only signifies a leap in machine learning efficiency but also opens up new possibilities for developing and maintaining cutting-edge language models.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 38k+ ML SubReddit
![]()
Hello, My name is Adnan Hassan. I am a consulting intern at Marktechpost and soon to be a management trainee at American Express. I am currently pursuing a dual degree at the Indian Institute of Technology, Kharagpur. I am passionate about technology and want to create new products that make a difference.
Credit: Source link
Comments are closed.