Apple Announces MM1: A Family of Multimodal LLMs Up To 30B Parameters that are SoTA in Pre-Training Metrics and Perform Competitively after Fine-Tuning

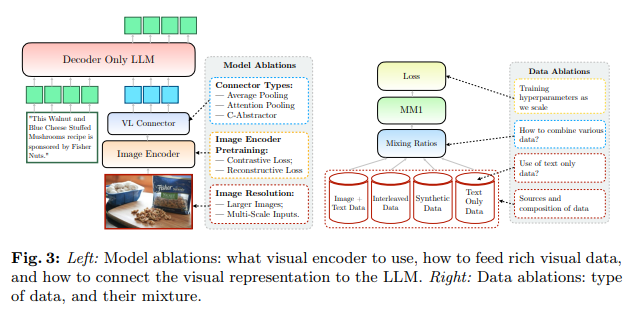
Recent research has focused on crafting advanced Multimodal Large Language Models (MLLMs) that seamlessly integrate visual and textual data complexities. By delving into the minutiae of architectural design, data selection, and methodological transparency, research has pushed the boundaries of what MLLMs can achieve and support future explorations. Their work is particularly notable for its comprehensive approach to dissecting the various components that contribute to the success of these models, shedding light on the pivotal roles played by image encoders, vision-language connectors, and the strategic amalgamation of diverse data types.
The researchers at Apple build MM1, a family of cutting-edge multimodal models with up to 30 billion parameters. They have taken a different path of openness and detailed documentation, providing valuable insights into constructing MLLMs. Their meticulous documentation covers everything from the choice of image encoders to the intricacies of connecting visual data with linguistic elements, offering a clear roadmap for building more effective and transparent models.
One of the study’s key revelations is the significant impact of carefully chosen pre-training data on the model’s performance. The researchers discovered that a judicious mix of image-caption pairs, interleaved image-text documents, and text-only data is essential for achieving superior results, particularly in few-shot learning scenarios. It highlights the importance of diversity in training data, which enables models to better generalize across different tasks and settings.

The suite of MM1 models represents a significant leap forward, capable of achieving competitive performance across a wide array of benchmarks. What sets MM1 apart is its sheer scale and its architectural innovations, including dense models and mixture-of-experts variants. These models demonstrate the effectiveness of the researchers’ approach, combining large-scale pre-training with strategic data selection to enhance the model’s learning capabilities.
Key Takeaways from the research include:
- Researchers from Apple led a comprehensive study on MLLMs, focusing on architectural and data selection strategies.
- Transparency and detailed documentation were prioritized to facilitate future research.
- A balanced mix of diverse pre-training data was crucial for model performance.
- MM1, a new family of models with up to 30 billion parameters, was introduced, showcasing superior performance across benchmarks.
- The study’s findings emphasize the significance of methodological choices in advancing MLLM development.
In conclusion, this research represents a significant advancement in the field of MLLMs, offering new insights into the optimal construction of these complex models. By highlighting the importance of transparency, detailed documentation, and strategic data selection, the study paves the way for future innovations. The introduction of MM1 underscores the potential of well-designed MLLMs to set new standards in multimodal understanding. The principles and findings outlined in this study will unlock the full potential of multimodal language models.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 38k+ ML SubReddit
![]()
Hello, My name is Adnan Hassan. I am a consulting intern at Marktechpost and soon to be a management trainee at American Express. I am currently pursuing a dual degree at the Indian Institute of Technology, Kharagpur. I am passionate about technology and want to create new products that make a difference.
Credit: Source link
Comments are closed.