Google AI Introduces Cappy: A Small Pre-Trained Scorer Machine Learning Model that Enhances and Surpasses the Performance of Large Multi-Task Language Models
In a new AI research paper, Google researchers introduced a pre-trained scorer model, Cappy, to enhance and surpass the performance of large multi-task language models. The paper aims to resolve challenges faced in the large language models (LLMs). While the LLMs demonstrate remarkable performance and generalization across various natural language processing tasks, their immense size demands substantial computational resources, making training and inference expensive and inefficient, especially when adapting them to downstream applications.
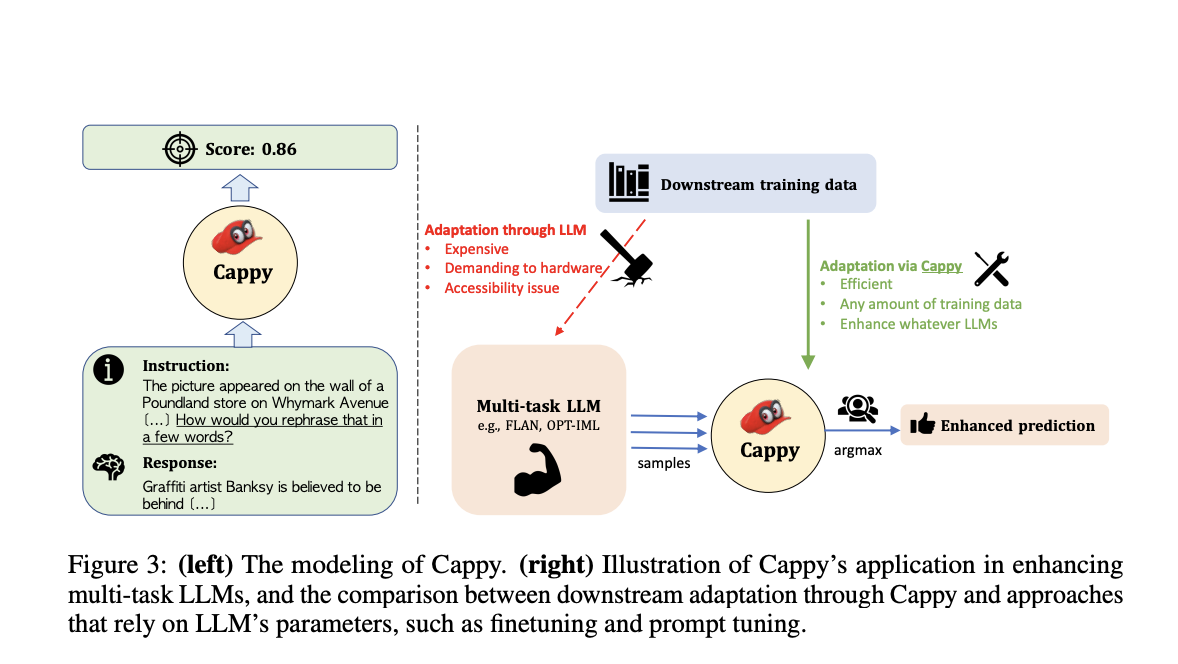
Currently, multi-task LLMs like T0, FLAN, and OPT-IML are utilized for various natural language processing tasks, trained under a unified instruction-following framework. Moreover, adapting these models to downstream applications, particularly complex tasks, poses further challenges due to extensive hardware requirements and limited accessibility to the most powerful LLMs. To address these challenges, the paper introduces Cappy—a lightweight pre-trained scorer designed to enhance the performance and efficiency of multi-task LLMs. Cappy functions independently on classification tasks or as an auxiliary component for LLMs, boosting their performance without requiring extensive finetuning or access to LLM parameters.
Cappy’s architecture is based on RoBERTa with a linear layer on top for regression. Its pretraining utilizes a diverse dataset collection from PromptSource, ensuring a wide range of task types are covered. To address the need for label diversity in the pretraining data, the researchers propose a data construction approach involving ground truth pairs, incorrect responses, and data augmentation through the use of existing multi-task LLMs. This results in a large and effective regression pretraining dataset. Cappy’s application involves a candidate selection mechanism that produces a score for each candidate response given an instruction. It can work independently on classification tasks or as an auxiliary component for generation tasks, enhancing the decoding of existing multi-task LLMs. Additionally, Cappy enables efficient adaptation of multi-task LLMs on downstream tasks without requiring finetuning or access to LLM parameters.
In conclusion, the paper addresses the challenge of efficiently utilizing large language models for multitasking scenarios by introducing Cappy, a lightweight pre-trained scorer. It demonstrates superiority in parameter efficiency and performance across various tasks and highlights its potential to streamline the adoption of large language models in practical applications.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 38k+ ML SubReddit
![]()
Pragati Jhunjhunwala is a consulting intern at MarktechPost. She is currently pursuing her B.Tech from the Indian Institute of Technology(IIT), Kharagpur. She is a tech enthusiast and has a keen interest in the scope of software and data science applications. She is always reading about the developments in different field of AI and ML.
Credit: Source link
Comments are closed.