Researchers from Stanford and Google AI Introduce MELON: An AI Technique that can Determine Object-Centric Camera Poses Entirely from Scratch while Reconstructing the Object in 3D
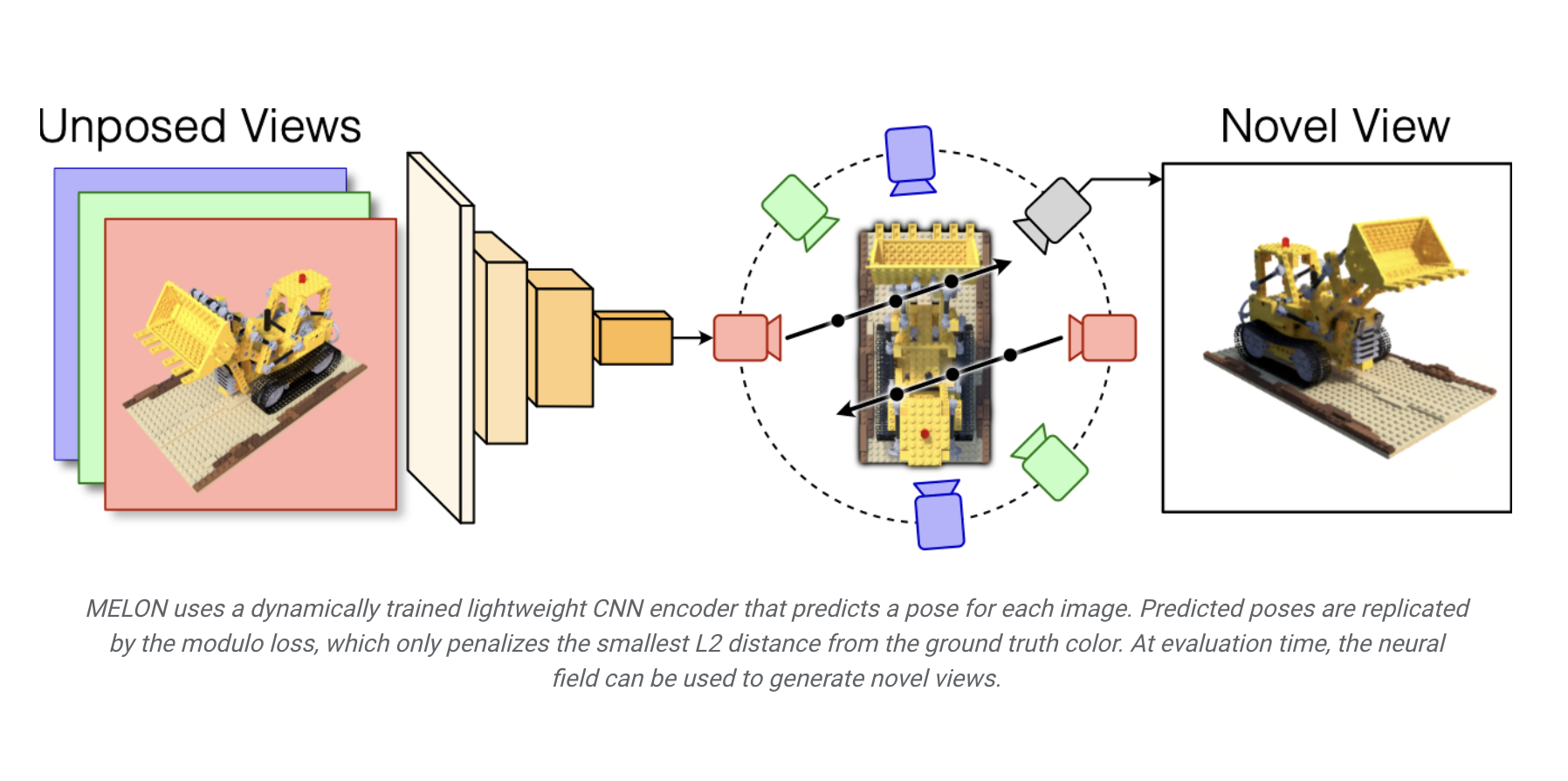
While humans can easily infer the shape of an object from 2D images, computers struggle to reconstruct accurate 3D models without knowledge of the camera poses. This problem, known as pose inference, is crucial for various applications, like creating 3D models for e-commerce and aiding autonomous vehicle navigation. Existing techniques relying on either gathering the camera poses beforehand or using generative adversarial networks (GANs) which were unable to solve the problem with accuracy and efficiency. Researchers from Google and Stanford University have introduced MELON to address the challenge in reconstructing 3D objects from 2D images due to unknown pose selection.
Traditionally, methods such as Neural Radiance Fields (NeRF) or 3D Gaussian Splatting have shown success in reconstructing 3D objects when camera poses are known. However, the challenge arises when these poses are unknown, leading to an ill-posed problem. Previous techniques, like BARF or SAMURAI, relied on initial pose estimates or complex training schemes involving GANs. In contrast, MELON offers a simpler yet effective approach. By leveraging a lightweight CNN encoder for pose regression and introducing a modulo loss that considers pseudo symmetries of an object, MELON can reconstruct 3D objects from unposed images with state-of-the-art accuracy. This method eliminates the need for approximate pose initializations, complex training schemes, or pre-training on labelled data, making it a promising solution for pose inference in 3D reconstruction tasks.
MELON’s approach involves two key techniques. Firstly, it utilises a dynamically trained CNN encoder to regress camera poses from training images. This CNN, initialised from noise and requiring no pre-training, effectively regularises the optimization process by forcing similar-looking images to similar poses. Secondly, MELON introduces a modulo loss that simultaneously considers pseudo symmetries of an object. By rendering the object from a fixed set of viewpoints for each training image and backpropagating the loss only through the view that best fits the training image, MELON effectively addresses the ill-posed nature of the problem. Additionally, by integrating these techniques into standard NeRF training, MELON simplifies the process while achieving competitive results. Evaluation on the NeRF Synthetic dataset demonstrates MELON’s ability to quickly converge to accurate poses and generate novel views with high fidelity, even from extremely noisy, unposed images.
In conclusion, MELON proves to be a promising solution to the challenging problem of reconstructing 3D objects from images with unknown poses. Its lightweight CNN encoders and introduction of a modulo loss considering pseudo symmetries enabled MELON to achieve state-of-the-art accuracy without the need for approximate pose initializations or complex training schemes.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 38k+ ML SubReddit
![]()
Pragati Jhunjhunwala is a consulting intern at MarktechPost. She is currently pursuing her B.Tech from the Indian Institute of Technology(IIT), Kharagpur. She is a tech enthusiast and has a keen interest in the scope of software and data science applications. She is always reading about the developments in different field of AI and ML.
Credit: Source link
Comments are closed.