A New Research On Unsupervised Deep Learning Shows That The Brain Disentangles Faces Into Semantically Meaningful Factors, Like Age At The Single Neuron Level

The ventral visual stream is widely known for supporting the perception of faces and objects. Extracellular single neuron recordings define canonical coding principles at various stages of the processing hierarchy, such as the sensitivity of early visual neurons to orientated outlines and more anterior ventral stream neurons to complex objects and faces, over decades. A sub-network of the inferotemporal cortex dedicated to facial processing has received a lot of attention. Faces appear to be encoded in low-dimensional neural codes inside such patches, with each neuron encoding an orthogonal axis of variation in the face space.
How such representations might emerge from learning from the statistics of visual input is an essential but unresolved subject. The active appearance model (AAM), the most successful computational model of face processing, is a largely handcrafted framework that can’t help answer the question of finding a general learning principle that can match AAM in terms of explanatory power while having the potential to generalize beyond faces.
Deep neural networks have recently become prominent computational models in the ventral monkey stream. These models, unlike AAM, are not limited to the domain of faces, and their tuning distributions are developed by data-driven learning. On multiway object recognition tasks, such modern deep networks are trained with high-density teaching signals, forming high-dimensional representations that, closely match those in biological systems.
Deep classifiers, on the other hand, do not now explain single-neuron responses in the monkey face patch any better than AAM. Furthermore, the representative form of deep classifiers and AAM differs. While deep classifiers create high-dimensional representations that are multiplexed over many simulated neurons, AAM uses a low-dimensional coding that encodes orthogonal information in single dimensions. As a result, the question of whether a learning objective exists that combines the capability of deep neural networks with the “gold standard” representational form and explanatory capacity of the handcrafted AAM remains unanswered.
One long-held theory is that the visual system uses self-supervision to retrieve the semantically interpretable underlying structure of sensory data, such as the shape or size of an item or the gender or age of a face image, based on this intuition. While such an interpretable structure appears deceptively simple to humans, it has proven difficult to recover in practice because it comprises a highly complex non-linear transformation of pixel-level inputs.
With the emergence of deep self-supervised generative models that learn to “disentangle” high-dimensional sensory data into meaningful variables of variation, recent breakthroughs in machine learning have provided an implementational blueprint for this theory. The beta-variational autoencoder (β-VAE) is one such model that learns to faithfully reconstruct sensory data from a low-dimensional embedding while also being regularised in a way that encourages individual network units to code for semantically meaningful variables like object color, face gender, and scene arrangement.
These deep generative models carry on the neuroscience community’s long tradition of developing self-supervised vision models while also moving in a new direction that allows for solid generalization, imagination, abstract reasoning, compositional inference, and other hallmarks of biological visual cognition. The study’s purpose is to determine whether a general learning objective can result in an encoding that is similar to the representative form used by real neurons. The results show that the β-VAE-optimized disentangling objective validates how the ventral visual stream forms the observed low-dimensional facial representations.
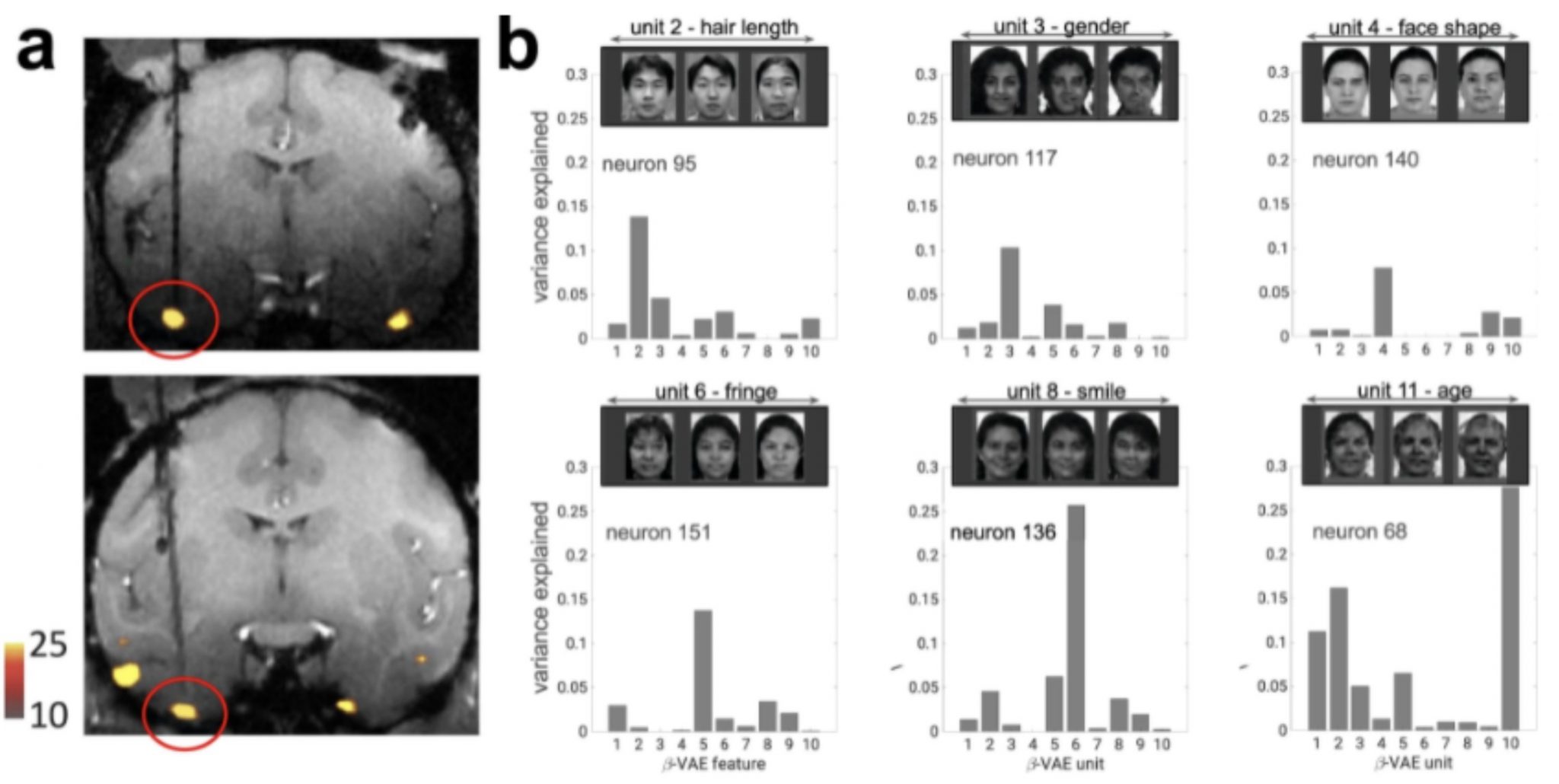
Single disentangled units explain the activity of single neurons, according to the findings. Suppose the calculations used in biological sensory systems are similar to those used by this deep generative model to deconstruct the visual world. In that case, single neuron tuning features should map easily onto the relevant latent units revealed by the β-VAE. The idea was evaluated using a previously published dataset of brain recordings from 159 neurons in the macaque face region, collected while the animals were viewing 2100 natural face photos.
The findings support previous evidence that the monkey IT’s face identification code is low-dimensional, with single neurons encoding independent axes of variance. Unlike earlier research, however, our findings show that such a code can be meaningfully interpreted at the level of a single neuron. The study shows that single IT neurons’ axes of variation align with single “disentangled” latent units that appear to be semantically meaningful and are discovered by the β-VAE, a class of deep neural networks proposed in the ML/AI community that does not rely on extensive teaching signals for learning. Assuming the strong alignment of single IT neurons with the single units discovered through disentangled representation learning and that disentangling can be done without an external teaching signal through self-supervision, the ventral visual stream may also be optimizing the disentangling learning goal.
Paper: https://www.nature.com/articles/s41467-021-26751-5.pdf
Suggested

Credit: Source link
Comments are closed.