Meta/Facebook AI Releases XLS-R: A Self-Supervised Multilingual Model Trained On 128 Languages For A Variety Of Speech Tasks

Talking to one another is a natural way for people to engage. With advancing speech technology, people are now interacting with devices in day to day lives.
Despite this, speech technology is only available for a small percentage of the world’s languages. Few-shot learning and even unsupervised speech recognition can be helpful, but the effectiveness of these methods is dependent on the quality of the self-supervised model.
A recent Facebook study presents XLS-R, a new self-supervised model for a range of speech tasks. By training on approximately ten times more public data in more than twice as many languages, XLS-R significantly outperforms previous multilingual models.
The model is fine-tuned to perform speech recognition, speech translation, and language identification, setting a new state of the art on a diverse set of benchmarks. This includes BABEL, CommonVoice, and VoxPopuli for speech recognition; CoVoST-2 for foreign-to-English translation; and VoxLingua107 for language identification.
XLS-R is based on wav2vec 2.0. The researchers trained the model on over 436,000 hours of publically available speech recordings. They used speech data from various sources ranging from legislative hearings to audiobooks, extending to 128 languages, encompassing nearly two and a half times as many languages as its predecessor.
Comparatively, more parameters are required to represent the different languages in the created data set. According to researchers, their largest model, which contains over 2 billion parameters, outperforms smaller models. In addition, they note that pretraining on many languages enhanced performance significantly more than pretraining on a single language.
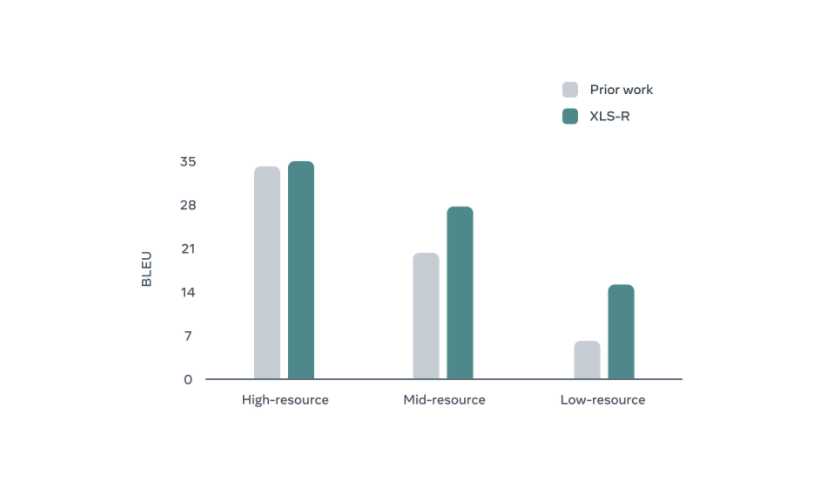
The team tested XLS-R’s performance on five languages of BABEL, ten languages of CommonVoice, eight languages of MLS, and fourteen languages of VoxPopuli. The proposed model outperforms previous work on the majority of the 37 languages examined.
They also tested their model for speech translation, in which they immediately translated audio recordings into another language. XLS-R was fine-tuned on several alternative translation directions of the CoVoST-2 benchmark at the same time so as to make a model that can execute numerous tasks. As a result, a single model that can translate between English and up to 21 other languages has been developed.
XLS-R is a huge step toward creating a single model that can interpret speech in various languages. The researcher believes that their work will enable machine learning systems to interpret all human speech better and spur more research into making speech technology more accessible worldwide, mainly to marginalized groups. They plan to improve the algorithms by creating new ways to learn with less supervision.
Paper: https://arxiv.org/abs/2111.09296?fbclid=IwAR3Sopc7rglv7mfdJx4ZtcVdxjTnoh7sTtHcgvtRVczCRoX_eTlJ-Nc08Cs
GitHub: https://github.com/pytorch/fairseq/tree/main/examples/wav2vec/xlsr
Reference: https://ai.facebook.com/blog/xls-r-self-supervised-speech-processing-for-128-languages
Suggested

Credit: Source link
Comments are closed.