A Cost-Sensitive Adversarial Data Augmentation (CSADA) Framework To Make Over-Parameterized Deep Learning Models Cost-Sensitive
Most machine learning methods assume that each misclassification mistake a model makes is of equal severity. This is frequently not the case for unbalanced classification issues. It is typically worse to exclude a case from a minority or positive class than to incorrectly categorize an example from a negative or majority class. Several real-world instances include recognizing fraud, diagnosing a medical problem, and spotting spam emails. A false negative (missing a case) is worse or more expensive in each scenario than a false positive.
Although Deep Neural Networks (DNNs) models have achieved satisfactory performance, their over-parameterization causes a significant challenge for cost-sensitive classification cases. The problem comes from the ability of DNNS to adapt to training datasets. Critical mistake costs won’t impact training if a model is clairvoyant or always able to expose the underlying truth. This is because there are no misclassifications. This phenomenon motivated a research team from the University of Michigan to rethink cost-sensitive categorization in DNNs and highlight the necessity for cost-sensitive learning beyond training examples.

This research team proposed using targeted adversarial samples to perform a data augmentation to train a model with more conservative decisions on costly pairs. Unlike most works dealing with this task, the method proposed in this article, the cost-sensitive adversarial data augmentation (CSADA) framework, intervenes in the training phase and is adapted to overfitting problems. In addition, it can be adapted to most DNN architectures and models beyond Neural Networks. The suggested adversarial augmentation scheme is not used to replicate natural data. Instead, it aims to create targeted adversaries that push decision boundaries. The generation of the targeted adversarial examples is made using a variant of the multi-step ascent descent technique. By producing data samples close to the decision border between the associated labels, the overreaching purpose is to introduce significant mistakes into training. The authors presented a new penalized cost-aware bi-level optimization formulation composed of two terms. The first term is a common empirical risk objective, while the second term is a penalty term that penalizes misclassifications of augmented samples regarding their corresponding weights. Minimizing this function in the training step makes the model more robust against critical errors.
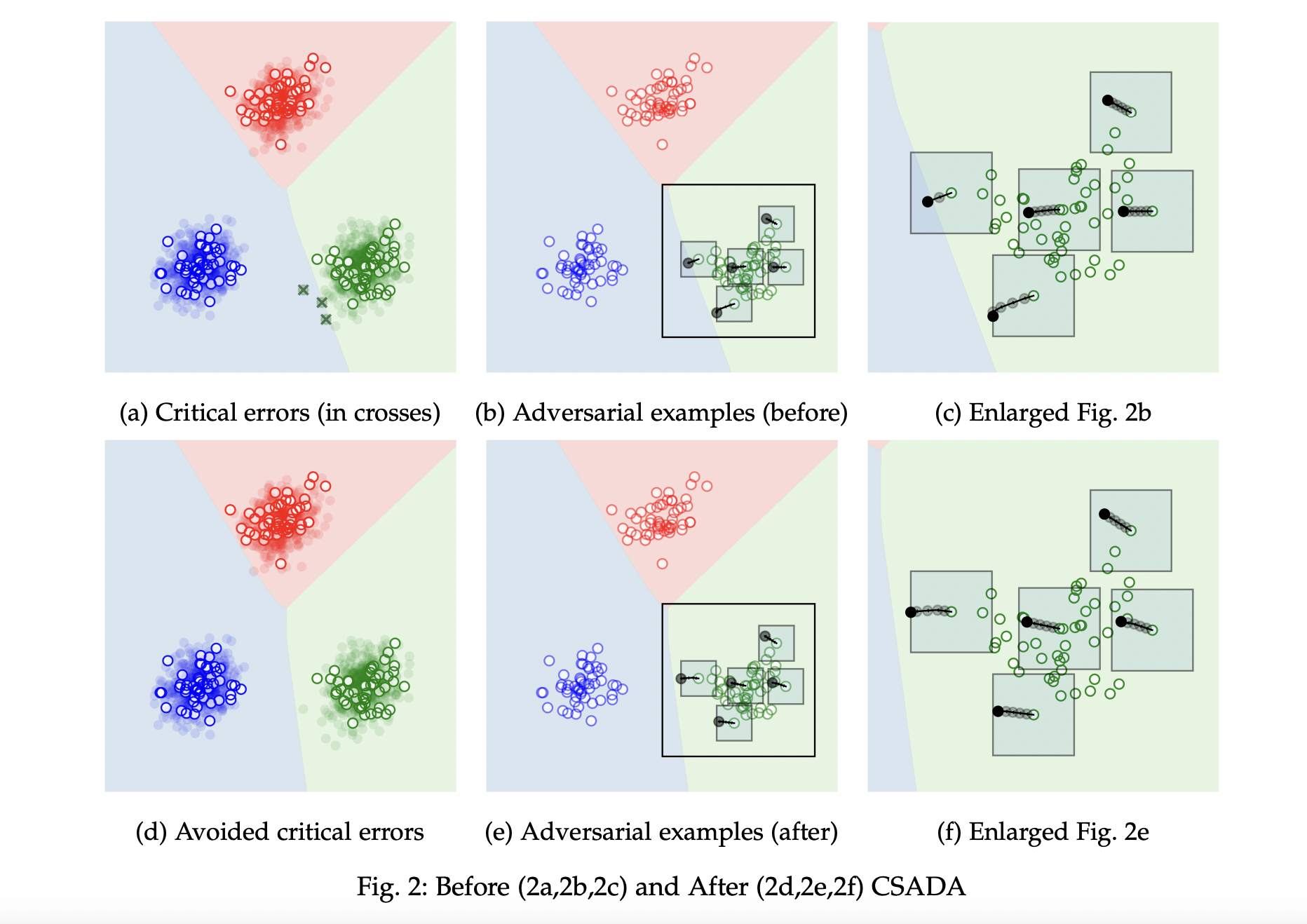
A proof of concept was presented to show the relevance of the idea introduced in this article. Three classes are generated from independent two-dimensional Gaussian distributions where only one misclassifying incurs a cost. Although the borders found in the training phase without data augmentation allowed an optimal separation of the three classes on the training samples, several critical errors were recorded during the inference. The use of targeted adversarial data augmentation was able to correct this problem by setting more robust borders against these errors.
An experimental study was carried out on three datasets, MNIST, CIFAR-10, and Pharmacy Medication Image (PMI), to evaluate CSADA. The proposed approach achieved equivalent results in terms of overall accuracy while successfully minimizing the overall cost and reducing critical errors in all tests over the three datasets.
In this research, we investigate the cost-sensitive classification issue in applications where the costs of various misclassification mistakes vary. To solve this issue, the authors provide a cost-sensitive data augmentation technique that creates a range of targeted adversarial instances employed in training to push decision-making limits toward minimizing critical errors. In addition, they suggest a mathematical framework for penalized cost-aware bi-level optimization, which penalizes the loss experienced by the produced adversarial cases. Finally, a multi-ascent descent gradient-based approach was also provided to solve the optimization problem.
This Article is written as a research summary article by Marktechpost Staff based on the research paper 'Rethinking Cost-sensitive Classification in Deep Learning via Adversarial Data Augmentation'. All Credit For This Research Goes To Researchers on This Project. Check out the paper. Please Don't Forget To Join Our ML Subreddit
![]()
Mahmoud is a PhD researcher in machine learning. He also holds a
bachelor’s degree in physical science and a master’s degree in
telecommunications and networking systems. His current areas of
research concern computer vision, stock market prediction and deep
learning. He produced several scientific articles about person re-
identification and the study of the robustness and stability of deep
networks.
Credit: Source link
Comments are closed.