A Latest Machine Intelligence Research Built A Stronger and Faster Baselines Based on a Set of Techniques for Boosting Model Efficiencies
Recognizing human actions in videos is an essential task for many applications. From helping coaches with player analysis in their sports teams to improving the security of video surveillance systems, the advancement in action recognition enabled many new applications in the domain.
The critical problem in action recognition is to completely explain the variety of spatial configurations and temporal dynamics in human behaviors by extracting discriminative and rich characteristics.
The majority of existing solutions in the literature focus on representing human actions using a skeleton-based approach because the human skeleton can provide a concise data format to show dynamic changes in
mobility of the human body.

One can think of the skeleton data as the time series of 3D coordinates of multiple skeleton joints. These joints can be captured either by estimating from 2D data, such as video frames, or by multimodal sensors, such as Microsoft Kinect.
Using skeleton-based representation to recognize action has certain advantages that make it appealing for researchers. Skeleton-based representations are more resistant to changes in lighting, camera angles, and other background changes than traditional RGB-based action identification techniques.
Despite all those advantages, the development of skeleton-based action recognition has been severely constrained by the high model complexity, notwithstanding the paucity of literature on the subject. The validation costs of model designs in large-scale datasets have grown due to the low efficiency of model training and inference. Therefore, tackling the complexity of skeleton-based action recognition methods is crucial.
This is where this paper comes into play. The authors propose an efficient framework with a reduced number of training parameters while preserving the performance of the skeleton-based action recogniton model.
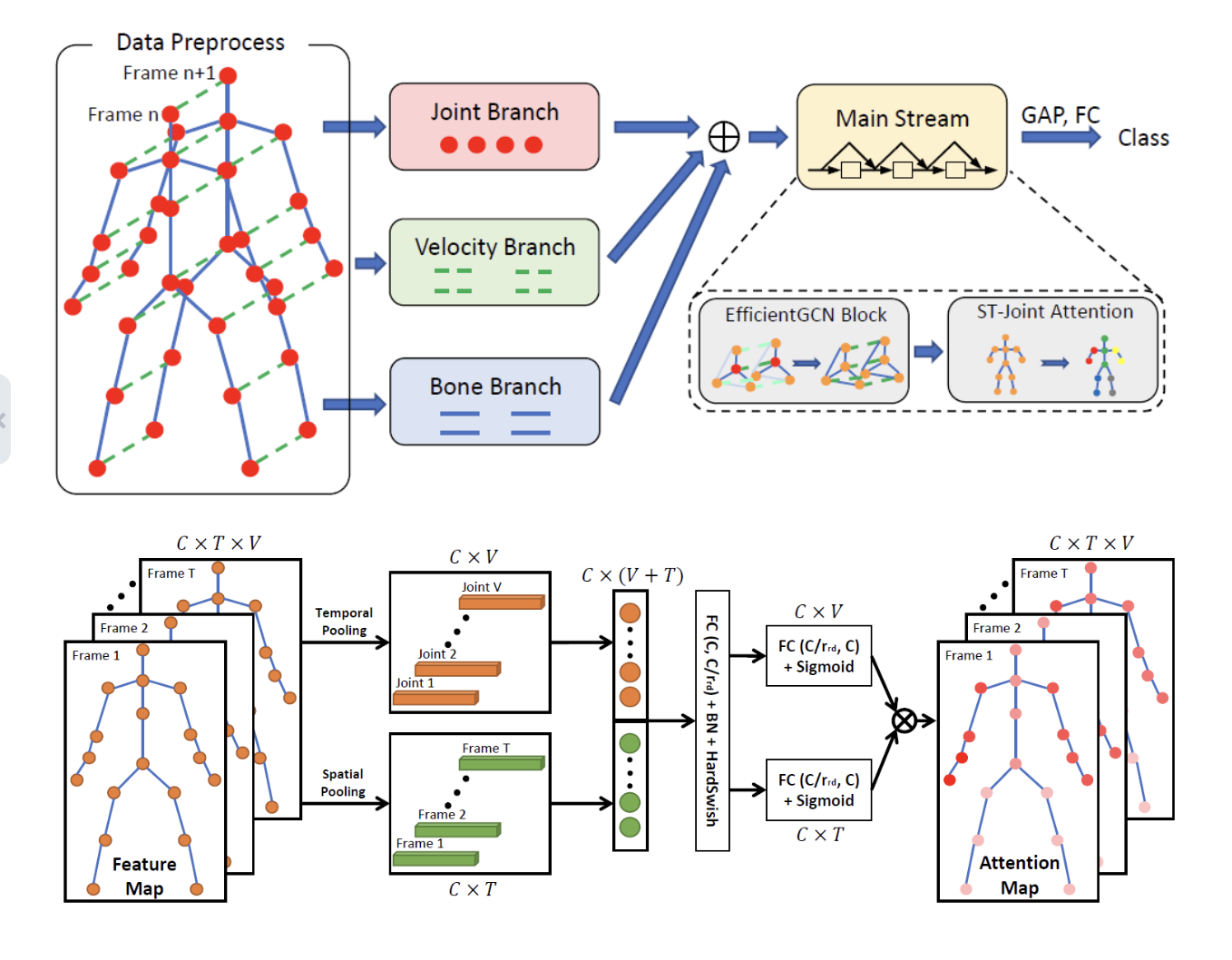
Firstly, to collect rich data from both the spatial configurations and the temporal dynamics of joints in skeleton sequences, an early fused Multiple Input Branches (MIB) architecture is built. In particular, rather than the typical late fusion at the score layer in most multistream graph convolution network (GCN) models, three input branches, including joint positions (relative and absolute), motion velocities (one or two temporal steps), and bone features (lengths and angles) are fused in the early stage of the entire network.
Furthermore, to extract temporal dynamics and condense the model size, GCN layers are expanded with four types of convolutional layers from CNN, namely the Bottleneck Layer, Separable Layer, Expanded Separable Layer, and Sandglass Layer. These introductions enable the model to learn more efficiently during training and reduce the inference time.
Moreover, the compound scaling approach, which evenly scales the network width, depth, and resolution using a set of predetermined scaling coefficients, is used to estimate the structural hyperparameters for each block. The resolution scaling factor is removed to adapt the original resolution scaling to graph networks, and the constraint between the width and depth factors is updated.
Finally, Spatial-Temporal Joint Attention (ST-Joint Attention) is proposed and inserted into each block of the model. This attention module aims to identify the most crucial joints from the whole skeleton sequence, which improves the model’s capacity to extract distinguishing characteristics.
By combining the work mentioned above, the result is a family of efficient graph convolution network baselines known as EfficientGCN, which maintains competitive performance to other SOTA approaches while being much smaller and faster.
This Article is written as a research summary article by Marktechpost Staff based on the research paper 'Constructing Stronger and Faster Baselines for Skeleton-based Action Recognition'. All Credit For This Research Goes To Researchers on This Project. Check out the paper and github. Please Don't Forget To Join Our ML Subreddit
![]()
Ekrem Çetinkaya received his B.Sc. in 2018 and M.Sc. in 2019 from Ozyegin University, Istanbul, Türkiye. He wrote his M.Sc. thesis about image denoising using deep convolutional networks. He is currently pursuing a Ph.D. degree at the University of Klagenfurt, Austria, and working as a researcher on the ATHENA project. His research interests include deep learning, computer vision, and multimedia networking.
Credit: Source link
Comments are closed.