A New AI Approach Using Embedding Recycling (ER) Can Make Language Model Development More Efficient With 2x Faster Training And 1.8x Speedup In Inference
Language models are one of the best advancements in Artificial Intelligence. With capabilities like summarization of articles, writing stories, answering questions, and completing codes, Language models are here to stay. These models are everywhere and are trained on massive amounts of textual data, including books, social media posts, articles, etc. The latest development by OpenAI, GPT-3, already has millions of users and 175 billion parameters. Generative Pre-trained Transformer 3 has human-like conversations and produces text on several themes and subjects. People even use them to create interactive chatbots and virtual assistants.
A language model works with the help of several computational layers, including the input layer, embedding layer, hidden layers, and output layer. Since machines don’t understand the text and only understand numerical data, the role of the first layer is to convert the text fed as input to the model into a numerical representation. Followed by this, different layers operate on the numerical data by performing several computations and estimations. An intermediate text rendition is made at each level, and weights are adjusted to improve the model’s performance.
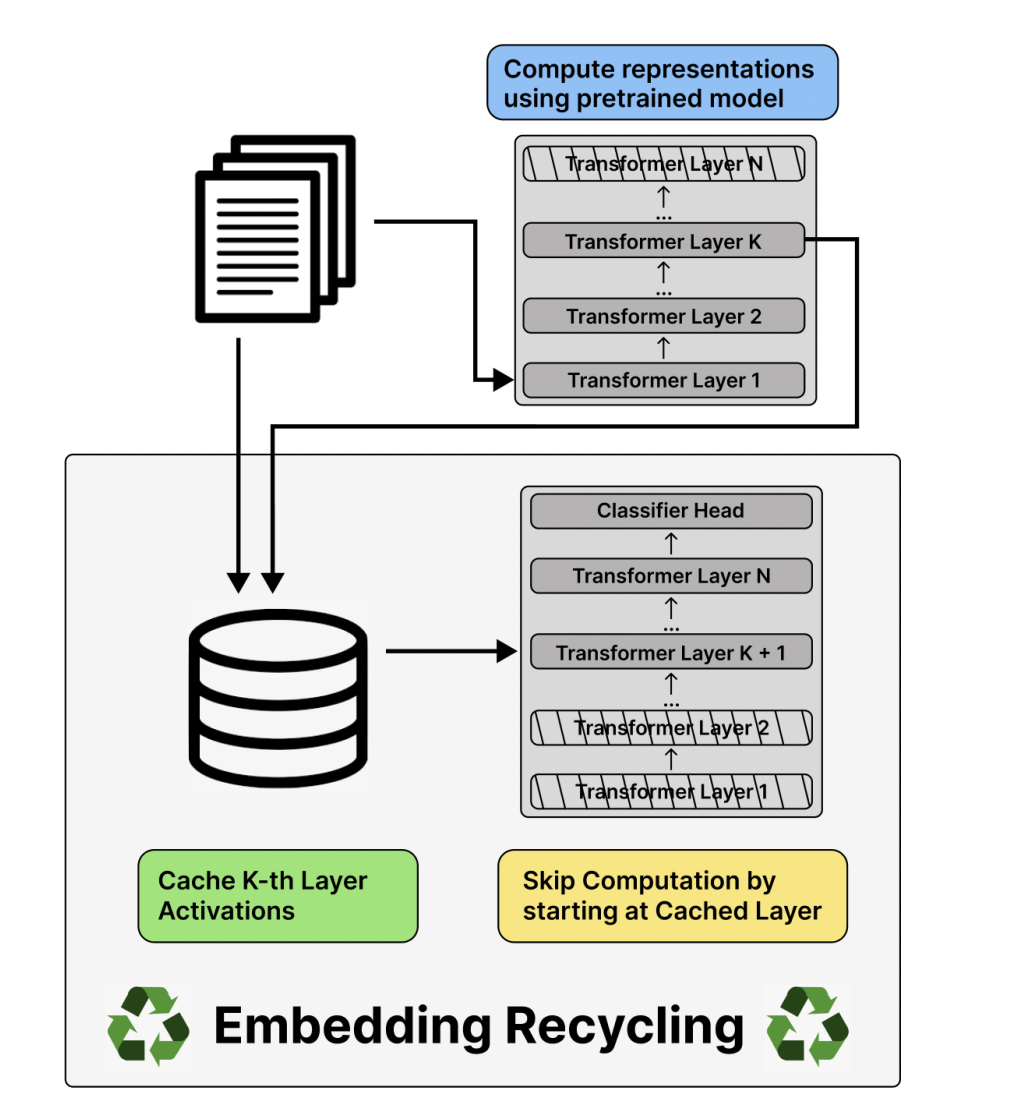
The weights in a model portray the strength of the networks between the neurons, which determines the performance of the model and the correctness of the output. Many weights that are closer to the input of the model continue to remain the same at the time of training leading to redundancy in the training of the model. This causes decreased efficiency and loss of energy, resources, and time. A new approach called Embedding Recycling (ER) has been introduced, which can improve efficiency and reuse the sequence representations from the preceding model runs.
Embedding Recycling retains the sequence representations during training and saves time and resources when several language models run over the same corpus of textual data. Several models run and operate on the same textual corpus. Reusing the contextualized embeddings generated in the previous model run is important to decrease the cost and fasten the training process. The research team consisting of AI2, Yale and Northwestern researchers, have tested this technique for 14 different tasks and eight language models. The number of parameters in these models varied from 17 million to 900 million parameters. It showed an increase in the training speed by 90% and 87 to 91% speedup in the inference. All this has been achieved with only a minimal loss in the F-1 metric.
The team has shared a few examples where Embedding Recycling can be used, i.e., where multiple models run over the same corpus. Those include performing topic classification, text summarization, and keyword extraction on the same Wikipedia document and a commercial AI assistant carrying out emotion recognition, command identification, etc., on the same user query.
Embedding Recycling is unquestionably a great method for reducing the computational costs of training and inference. It introduces layer recycling with the help of fine-tuning and parameter-efficient adapters, which seems favorable for the efficient usage of language models. Consequently, Embedding Reying is an amazing breakthrough in language model development.
Check out the Paper, Github and Reference Article. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 14k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
For advertising or sponsorship, please fill out this form.
![]()
Tanya Malhotra is a final year undergrad from the University of Petroleum & Energy Studies, Dehradun, pursuing BTech in Computer Science Engineering with a specialization in Artificial Intelligence and Machine Learning.
She is a Data Science enthusiast with good analytical and critical thinking, along with an ardent interest in acquiring new skills, leading groups, and managing work in an organized manner.
Credit: Source link
Comments are closed.