A New AI Paper Explains The Different Levels of Expertise Large Language Models as General Pattern Machines Can Have
LLMs, or large language models, are taught to incorporate the many patterns woven into a language’s structure. They are used in robotics, where they can act as high-level planners for instruction-following tasks, synthesize programs representing robot policies, design reward functions, and generalize user preferences. They also exhibit a variety of out-of-the-box abilities, such as generating chains of reasoning, solving logic puzzles, and finishing math problems. These settings remain semantic in their inputs and outputs and rely on the few-shot in-context examples in text prompts that establish the domain and input-output format for their jobs.
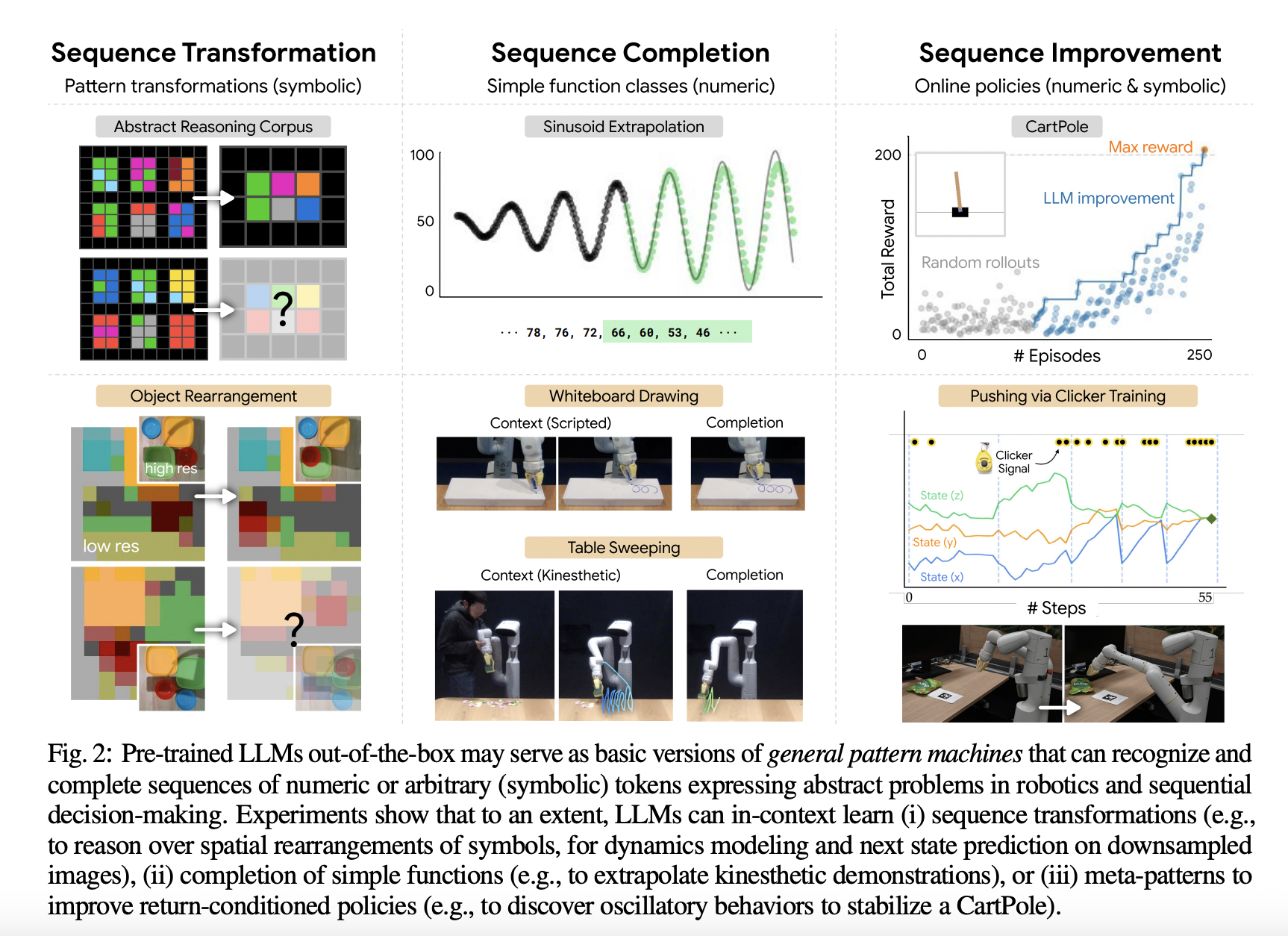
One important finding of their study is that LLMs may function as simpler types of general pattern machines due to their capacity to represent, modify, and extrapolate more abstract, nonlinguistic patterns. This finding may go against conventional wisdom. To illustrate this topic, consider the Abstract Reasoning Corpus. This broad AI benchmark includes collections of 2D grids with patterns that allude to abstract notions (such as infilling, counting, and rotating objects). Each task starts with a few instances of an input-output relationship before moving on to test inputs, the goal of which is to predict the related outcome. Most program synthesis-based approaches are manually constructed using domain-specific languages or assessed against condensed variations or subsets of the benchmark.
LLMs in-context prompted in the style of ASCII art (see Fig. 1) can correctly predict solutions for up to 85 (out of 800) problems, outperforming some of the best-performing methods to date, without the need for additional model training or fine-tuning, according to their experiments. On the other hand, end-to-end machine learning methods only solve a small number of test problems. Surprisingly, they discover that this holds for more than just ASCII numbers and that LLMs may still produce good answers when their replacement is a mapping to tokens randomly selected from the lexicon. These findings raise the fascinating possibility that LLMs may have broader representational and extrapolation capacities independent of the particular tokens under consideration.

This is consistent with – and supports – previous findings that ground-truth labels perform better than random or abstract label mappings when used for in-context categorization. In robotics and sequential decision-making, where a wide range of problems involve patterns that may be challenging to reason precisely in words, they hypothesize that the capabilities underpinning pattern reasoning on the ARC may allow general pattern manipulation at different levels of abstraction. For instance, a method for spatially rearranging things on a tabletop may be expressed using random tokens (see Fig. 2). Another illustration is extending a sequence of status and action tokens with increasing returns to optimize a trajectory about a reward function.
Researchers from Stanford University, Google DeepMind, and TU Berlin have 2 major objectives for this study (i) assess the zero-shot capabilities that LLMs may already contain to perform some level of general pattern manipulation and (ii) investigate how these abilities can be used in robotics. These efforts are orthogonal and complementary to developing multi-task policies by pre-training on large amounts of robot data or robotics foundation models that can be fine-tuned for downstream tasks. These skills are undoubtedly insufficient to replace specialized algorithms completely, but characterizing them can assist in determining the most important areas to focus on when training generalist robot models. According to their evaluation, LLMs fall into three categories: sequence transformation, sequence completeness, or sequence enhancement (see Fig. 2).
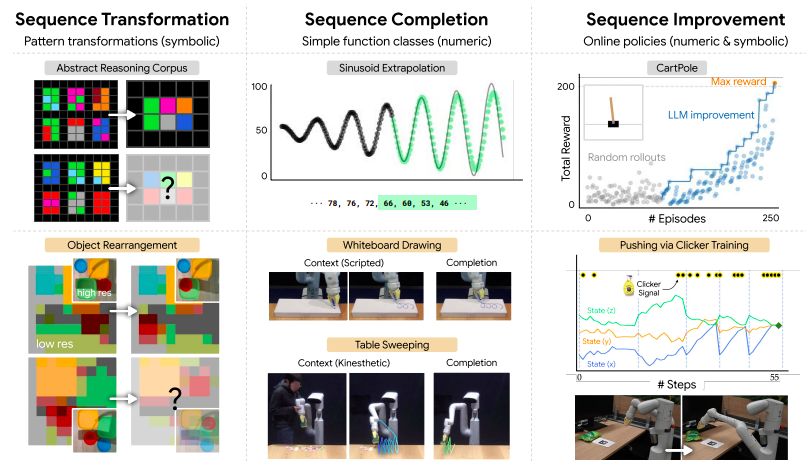
First, they demonstrate that LLMs can generalize some sequence transformations of increasing complexity with some token invariance, and they suggest that this may be used in robotic applications requiring spatial thinking. They next evaluate LLMs’ capacity for completing patterns from straightforward functions (like sinusoids), demonstrating how this might be used for robotic activities like extending a wiping motion from tactile demonstrations or creating patterns on a whiteboard. LLMs may perform fundamental types of sequence improvement thanks to the combination of extrapolation and in-context sequence transformation. They demonstrate how using reward-labeled trajectory context, and online interaction may help an LLM-based agent learn to navigate around a tiny grid, find a stabilizing CartPole controller, and optimize basic trajectory using human-in-the-loop “clicker” incentive training. They have made public their code, benchmarks, and videos.
Check out the Paper and Project. Don’t forget to join our 26k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more. If you have any questions regarding the above article or if we missed anything, feel free to email us at Asif@marktechpost.com
🚀 Check Out 100’s AI Tools in AI Tools Club
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
Credit: Source link
Comments are closed.