A New AI Paper from UC Berkeley Introduces Anim-400K: A Large-Scale Dataset for Automated End-To-End Dubbing of Video in Japanese and English
There has been a notable discrepancy between the global distribution of language speakers and the predominant language of online material, which is English. Even while English is used in up to 60% of internet information, only 18.8% of people worldwide speak it, and just 5.1% of people use it as their first language. For non-English speakers, in particular, this language barrier limits their access to important information, especially when it comes to videos.
Researchers have been putting in efforts to address this issue by going over subtitling and dubbing, which are the two popular techniques for making video content viewable by a variety of linguistic audiences. Dubbing is the process of substituting native language audio tracks for the original audio while subtitles are translated into the target language. Studies have shown that dubbed videos, which target individuals who could be illiterate or beginning readers, might improve user interest and retention.
Even with the advances in automated subtitling facilitated by Machine Translation (MT) and Automatic Speech Recognition (ASR), automated dubbing is still a laborious and expensive procedure that frequently requires human involvement. Text-to-speech (TTS), ASR, and MT technologies are often combined in intricate pipelines for automated dubbing systems. However, these systems have trouble with subtleties like timing, prosody, and facial gestures, which are crucial for good dubbing.
The idea of end-to-end dubbing overcomes these difficulties, as it enables translated audio to be produced straight from unprocessed source audio. The benefits of this method include the model’s capacity to record minute differences in speaker performance, which is essential for creating high-caliber dubbing.
In recent research, a team of researchers from the University of California, Berkeley, presented the Anim-400K dataset, which consists of more than 425,000 aligned dubbed clips. Anim-400K has been optimized for synchronized multilingual operations such as automated dubbing, and its size greatly outpaces that of current aligned dubbed video collections. It also offers strong metadata support for a range of difficult video operations.
The study has covered the following topics: a description of the data collection procedure, a comparison between Anim-400K and other datasets, an outline of possible tasks that Anim-400K can enable, and a discussion of the dataset’s limits and ethical implications.
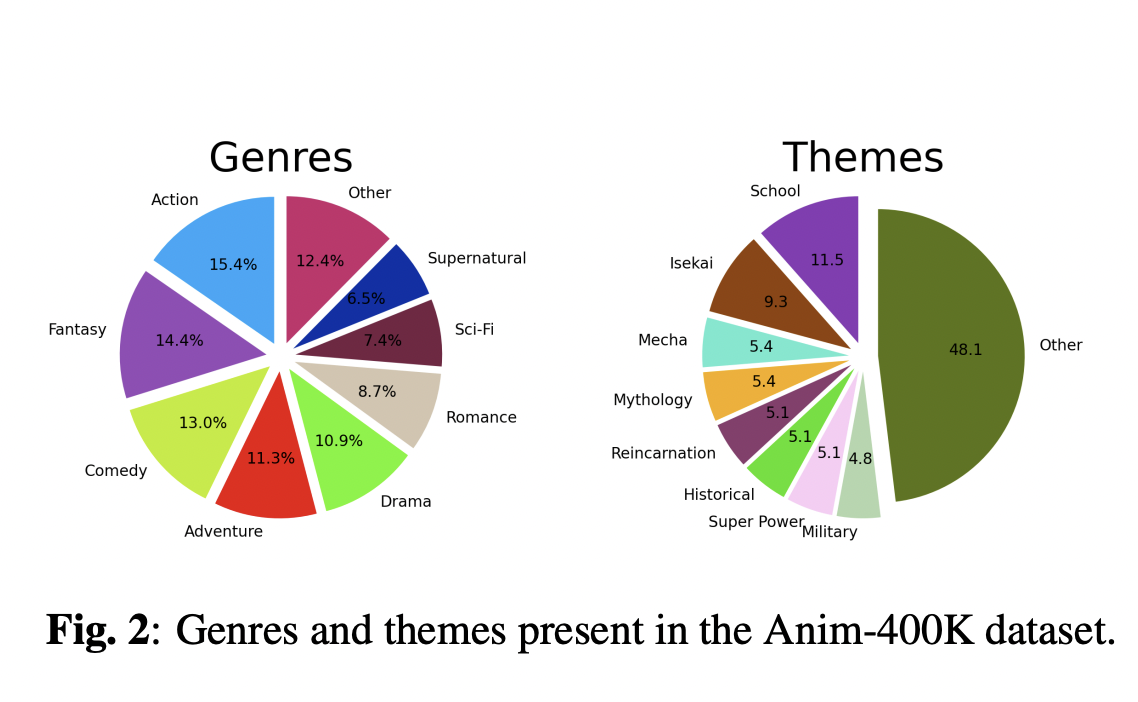
Anim-400K consists of an extensive collection of more than 425,000 aligned animated video segments in both Japanese and English. It makes 763 hours of music and video from more than 190 properties that span hundreds of themes and genres. It is intended to facilitate a range of video-related tasks, such as guided video summarization, simultaneous translation, automatic dubbing, and genre, topic, and style classification.
To facilitate in-depth research into various audio-visual tasks, Anim400K has been further enhanced with metadata such as genres, themes, show-ratings, character profiles, and animation styles at the property level; episode synopses, ratings, and subtitles at the episode level; and pre-computed ASR at an aligned clip level.
In conclusion, this study shows the linguistic divide in online media and the difficulties associated with automating the dubbing process. The Anim-400K is definitely a great solution that tackles the scarcity problem and has the ability to improve a range of video-related jobs by facilitating experimentation and study.
Check out the Paper and Github. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our 36k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
![]()
Tanya Malhotra is a final year undergrad from the University of Petroleum & Energy Studies, Dehradun, pursuing BTech in Computer Science Engineering with a specialization in Artificial Intelligence and Machine Learning.
She is a Data Science enthusiast with good analytical and critical thinking, along with an ardent interest in acquiring new skills, leading groups, and managing work in an organized manner.
Credit: Source link
Comments are closed.