A New AI Research from China Introduces GLM-130B: A Bilingual (English and Chinese) Pre-Trained Language Model with 130B Parameters
In recent times, the zero-shot and few-shot capabilities of Large Language Models (LLMs) have increased significantly, with those with over 100B parameters giving state-of-the-art performance on various benchmarks. Such an advancement also presents a critical challenge with respect to LLMs, i.e., transparency. Very limited knowledge about these large-scale models and their training process is available to the public, and releasing this information would facilitate the training of high-quality LLMs of this scale.
A group of researchers from Tsinghua University and Zhipu.AI have released GLM-130B, which is an open-source bilingual (English and Chinese) pre-trained language model with 130B parameters. The researchers in this paper have demonstrated the training process of the model, including the ways the process could be optimized, in an attempt to open-source a model at par with GPT-3, having parameters in the scale of 100B. Additionally, the researchers have shared both the successful and failed aspects of the training process.
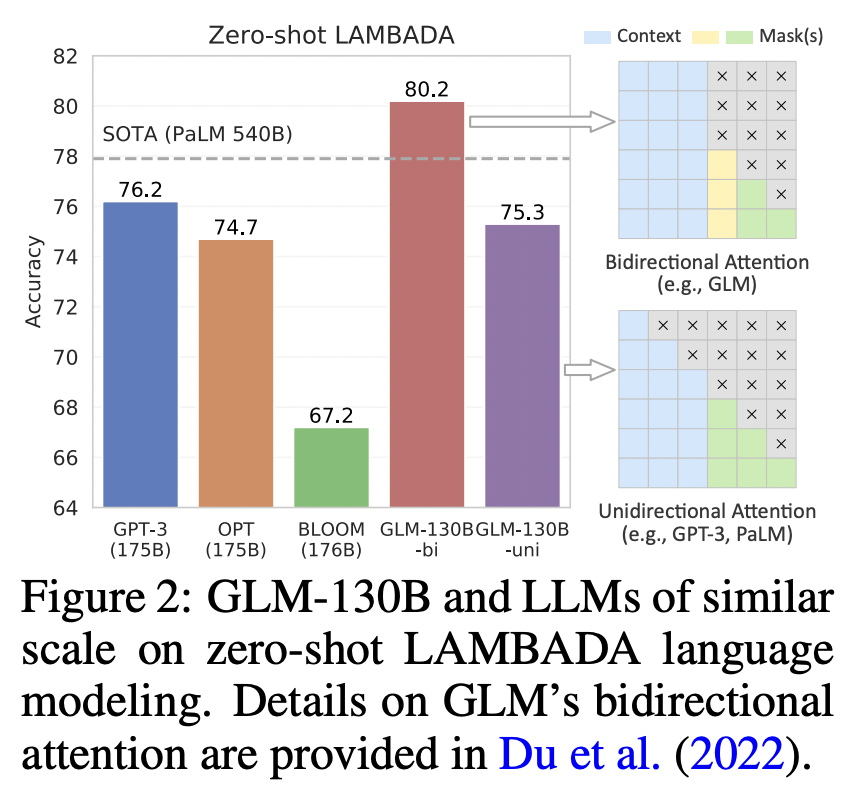
GLM-130B uses a bidirectional General Language Model (GLM) as its base. The architecture uses autoregressive blank infilling as its training objective, which allows for a better understanding of contexts as compared to GPT-style models. GLM-130B is able to outperform both GPT-3 and PaLM 540B on zero-shot LAMBADA by achieving a zero-shot accuracy of 80.2%.
The authors of this paper experimented with different Layer Normalization (LN) techniques in order to stabilize the training process of GLM-130B. Existing practices such as Pre-LN, Post-LN, and Sandwich-LN were ineffective, but Post-LN initialized with DeepNorm showed promising results. The pre-training data of the model consists of more than 2TB of English and Chinese text corpora extracted from online forums, encyclopedias, etc., to form a well-balanced dataset.
As mentioned earlier, GLM-130B achieves a record accuracy on the LAMBADA dataset. On the Pile test set, which consists of a series of benchmarks for language modelling, the GLM model’s performance was at par with GPT-3 and Jurassic-1 models. The model also performs well on the MMLU benchmark, with its few-shot performance as good as GPT-3.
Additionally, on the BIG-bench benchmark, GLM-130B was able to outperform both GPT-3 and PaLM in zero-shot settings. Even though the model gave significant performances, the researchers noticed that its performance growth with respect to few-shot samples is not as great as GPT-3’s. They hypothesize that it is due to multiple reasons, such as the model’s bidirectional nature, the limitation of a dataset that is at par with PaLM in terms of quality and diversity, etc.
The researchers also tested the zero-shot performance of the model on Chinese benchmarks. They concluded that GLM-130B not only outperformed ERNIE Titan 3.0 across more than ten tasks but also performed at least 260% better than the same on two abstractive MRC datasets. This may be due to the fact that the pre-training objective of GLM included autoregressive blank infilling that is similar to abstractive MRC.
In conclusion, the GLM-130B is a powerful, open-source, bilingual pre-trained language model that performs at the level of GPT-3 and PaLM across different benchmarks and even outperforms them in some of the tasks. Apart from its performance, what sets this model apart is the transparency of its development. The researchers have made the training process of the model public, along with their experiences of both success and failure. This approach reflects their commitment to fostering open and inclusive research within the field of LLMs.
Check out the Paper and Github. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 32k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
We are also on Telegram and WhatsApp.
![]()
I am a Civil Engineering Graduate (2022) from Jamia Millia Islamia, New Delhi, and I have a keen interest in Data Science, especially Neural Networks and their application in various areas.
Credit: Source link
Comments are closed.