A New AI Research from Italy Introduces a Diffusion-Based Generative Model Capable of Both Music Synthesis and Source Separation
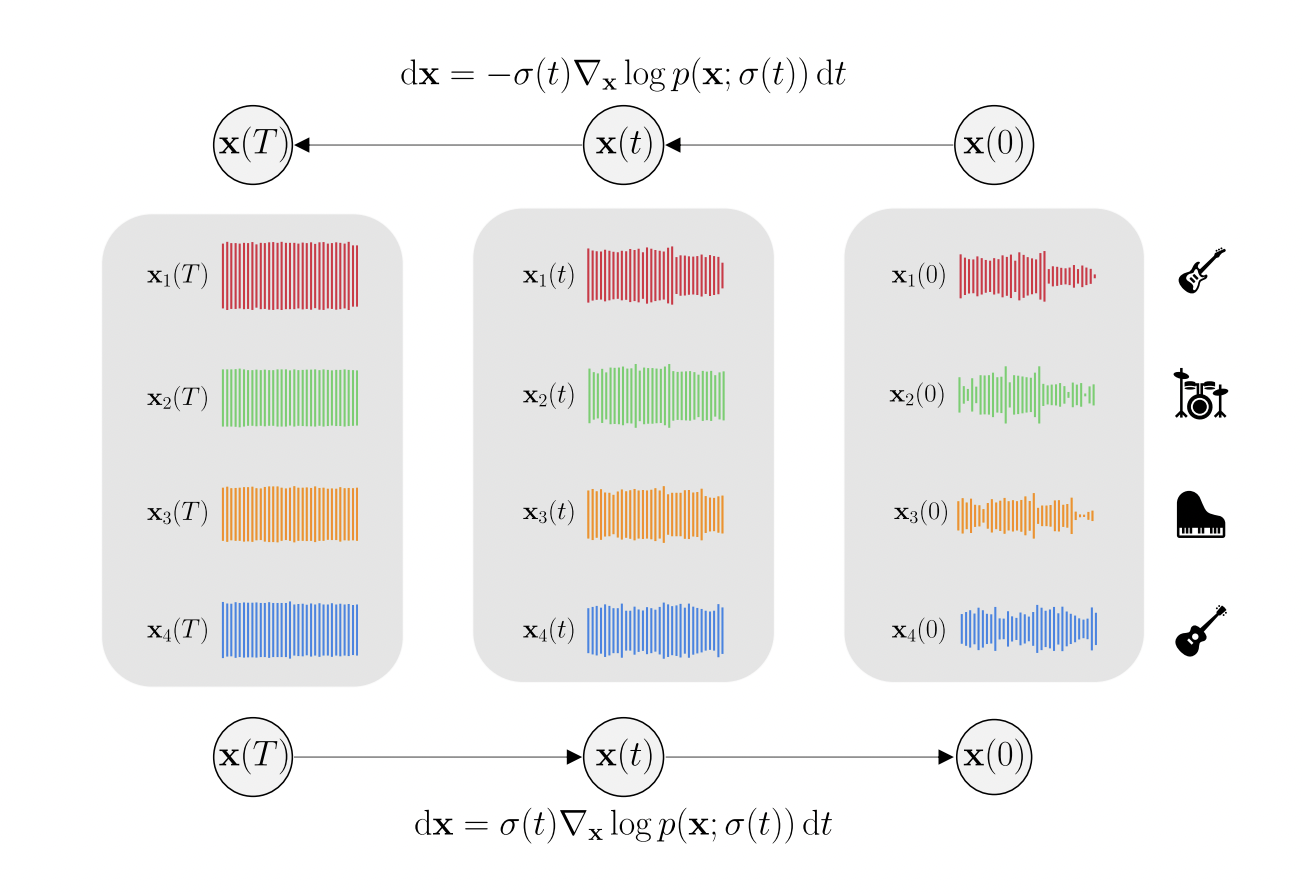
Human beings are capable of processing several sound sources at once, both in terms of musical composition or synthesis and analysis, i.e., source separation. In other words, human brains can separate individual sound sources from a mixture and vice versa, i.e., synthesize several sound sources to form a coherent combination. When it comes to mathematically expressing this knowledge, researchers use the joint probability density of sources. For instance, musical mixtures have a context such that the joint probability density of sources does not factorize into the product of individual sources.
A deep learning model that can synthesize many sources into a coherent mixture and separate the individual sources from a mixture does not exist currently. When it comes to musical composition or generation tasks, models directly learn the distribution over the mixtures, offering accurate modeling of the mixture but losing all knowledge of the individual sources. Models for source separation, in contrast, learn a single model for each source distribution and condition on the mixture at inference time. Thus, all the crucial details regarding the interdependence of the sources are lost. It is difficult to generate mixtures in either scenario.
Taking a step towards building a deep learning model that is capable of performing both source separation and music generation, researchers from the GLADIA Research Lab, University of Rome, have developed Multi-Source Diffusion Model (MSDM). The model is trained using the joint probability density of sources sharing a context, referred to as the prior distribution. The generation task is carried out by sampling using the prior, whereas the separation task is carried out by conditioning the prior distribution on the mixture and then sampling from the resulting posterior distribution. This approach is a significant first step towards universal audio models because it is a first-of-its-kind model that is capable of performing both generation and separation tasks.
The researchers used the Slakh2100 dataset for their experiments. Over 2100 tracks make up the Slakh2100 dataset, making it a standard dataset for source separation. Slakh2100 was chosen as the team’s dataset primarily because it has a substantially higher amount of data than other multi-source datasets, which is crucial for establishing the caliber of a generative model. The model’s foundation lies in estimating the joint distribution of the sources, which is the prior distribution. Then, different tasks are resolved at the inference time using the prior. The partial inference tasks, such as source imputation, where a subset of the sources is generated given the others (using a piano track that complements the drums, for instance), are some additional tasks alongside classical total inference tasks.
The researchers used a diffusion-based generative model trained using score-matching to learn the prior. This technique is often known as “denoising score matching.” The key idea of score-matching is to approximate the “score” function of the target distribution rather than the distribution itself. Another significant addition made by the researchers was introducing a novel sampling method based on Dirac delta functions to attain noticeable results on source separation tasks.
To assess their model on separation, partial and total generation, the researchers ran a number of tests. The model’s performance on separation tasks was on par with that of other state-of-the-art regressor models. The researchers also explained that the amount of contextual data currently accessible limits the performance of their algorithm. The team has considered pre-separating mixtures and using them as a dataset to address the issue. In summary, the Multi-Source Diffusion Model for separation and total and partial generation in the musical domain provided by GLADIA Research Lab is a novel paradigm. The group hopes their work will encourage other academics to conduct more in-depth research in the field of music.
Check out the Paper and Project. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 14k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Khushboo Gupta is a consulting intern at MarktechPost. She is currently pursuing her B.Tech from the Indian Institute of Technology(IIT), Goa. She is passionate about the fields of Machine Learning, Natural Language Processing and Web Development. She enjoys learning more about the technical field by participating in several challenges.
Credit: Source link
Comments are closed.