A New AI Research from John Hopkins Explains How AI Can Perform Better at Theory of Mind Tests than Actual Humans
One might think as to what kind of daily circumstances can large language models (LLMs) reason about. Although large language models (LLMs) have achieved great success in many tasks, they continue to need help with tasks that call for reasoning. So-called “theory of mind” (ToM) reasoning, which entails keeping track of an agent’s mental state, including their objectives and knowledge, is one area of particular interest. Language models’ ability to correctly answer common questions has substantially increased. However, their performance in the theory of mind is somewhat subpar.
In this study, researchers from Johns Hopkins University test the idea that proper prompting can improve LLMs’ ToM performance.
For several reasons, LLMS must be capable of doing ToM reasoning with reliability:
- ToM is a crucial component of social knowledge, enabling individuals to take part in complex social interactions and foresee the actions or reactions of others.
- ToM is a complicated cognitive ability most highly developed in humans and a few other species. This can be because Tom uses structured relational information. The ability to infer the thoughts and beliefs of agents will be useful for models that interact with social data and with people.
- Inferential reasoning is frequently used in ToM tasks.
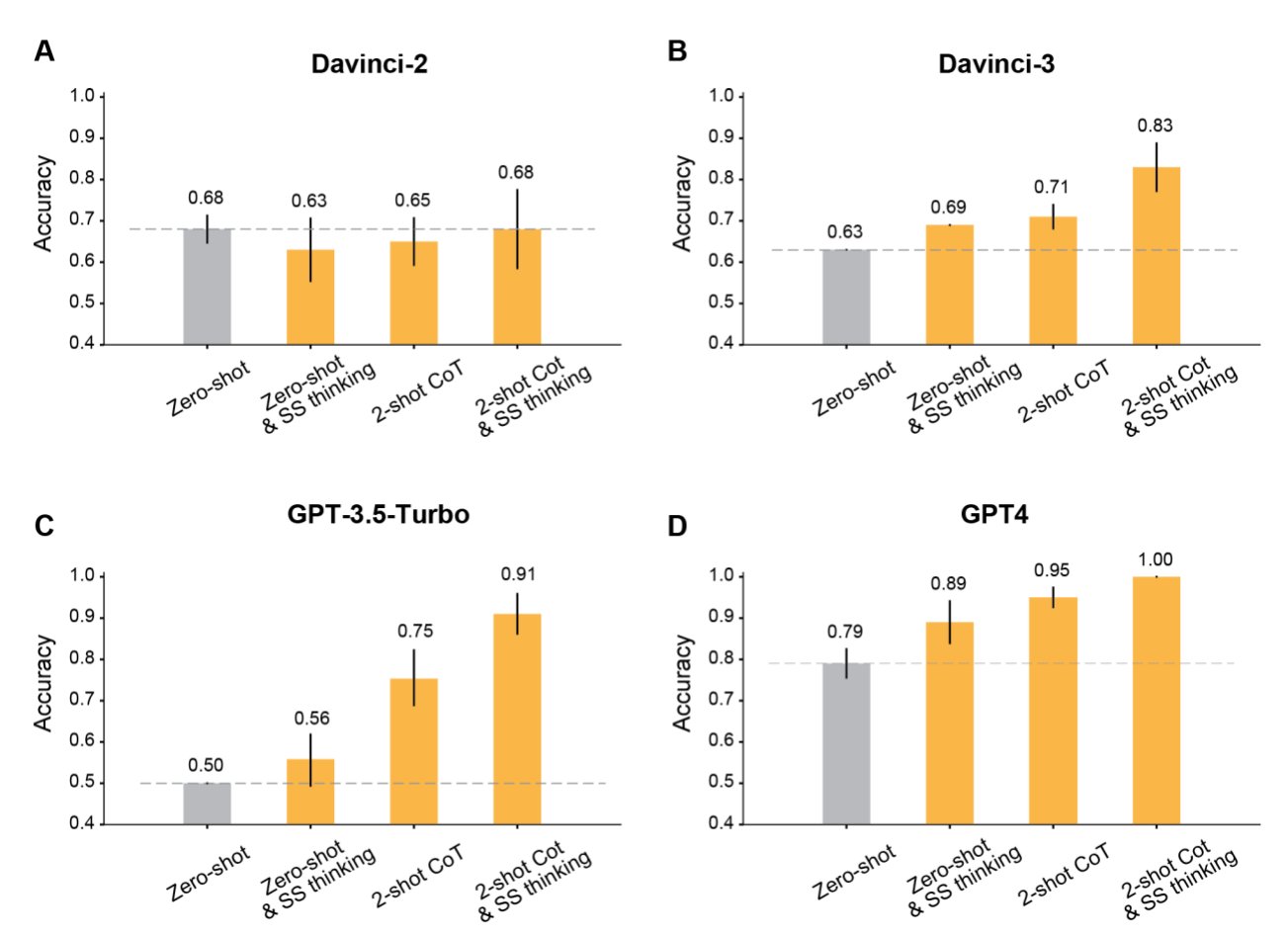
Approaches to in-context learning can improve LLMs’ ability for a reason. For instance, to function successfully under ToM, LLMs must reason using unobservable information (such as actors’ concealed mental states), which must be inferred from context rather than parsed from the surface text (such as an explicit statement of a situation’s attributes). Therefore, evaluating and enhancing these models’ performance on ToM tasks may provide insight into their potential for inferential reasoning tasks. Researchers have shown that for sufficiently large language models (+100B parameters), model performance may be enhanced by employing just a small number of task demonstrations described exclusively through the model’s input (i.e., at inference time, without weight updates).
The term “few-shot learning” is commonly used to describe this kind of performance improvement. Later studies demonstrated that LLMs’ capacity for complex reasoning was enhanced when the few-shot examples in the prompt included the steps taken to conclude (“chain-of-thought reasoning”). Furthermore, it has been demonstrated that teaching language models to think “step-by-step” improves their reasoning abilities even without exemplar demonstrations. The benefits of various prompting strategies have yet to be understood theoretically. Still, several recent research has investigated the implications of compositional structure and local dependencies in training data on the efficacy of these methods.
Some research supports the capacity of LLMs to use ToM reasoning, while others cast doubt on it. Although this prior literature offers many insights into ToM in LLMs, there are two main limitations to the quantitative evaluations of ToM performance. ToM performance on single-word or multiple-option completion is the first thing they look at for LLMs. Instead of being graded on a single-word completion, LLMs may gain by freely creating solutions with various pieces and speculating over multiple options. Second, most of the work criticizing LLMs’ ToM skills focused on either zero-shot testing or gave instances without providing a step-by-step justification for the solution.
However, the output that LLMs produce can sometimes be very context-sensitive. Therefore, they questioned whether recent LLMs might perform better on the ToM when given the right prompts. Here, they assess how well LLMs do when asked ToM comprehension tasks and investigate whether prompting techniques like chain-of-thought reasoning, step-by-step thinking, and few-shot learning may improve performance. It is crucial to boost inferential reasoning performance through prompting since it is a flexible method that only calls for fresh training data or new datasets of significant size. Additionally, if efficient driving strategies direct LLMs to produce higher-quality ToM responses, this enhances the general dependability of their reasoning in various everyday contexts. The raw LLM outputs are publicly available on GitHub.
Check out the Paper. Don’t forget to join our 20k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more. If you have any questions regarding the above article or if we missed anything, feel free to email us at Asif@marktechpost.com
🚀 Check Out 100’s AI Tools in AI Tools Club
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
Credit: Source link
Comments are closed.