A New AI Research from Stanford Explains the Role of Expressions of Overconfidence and Uncertainty in Language Models
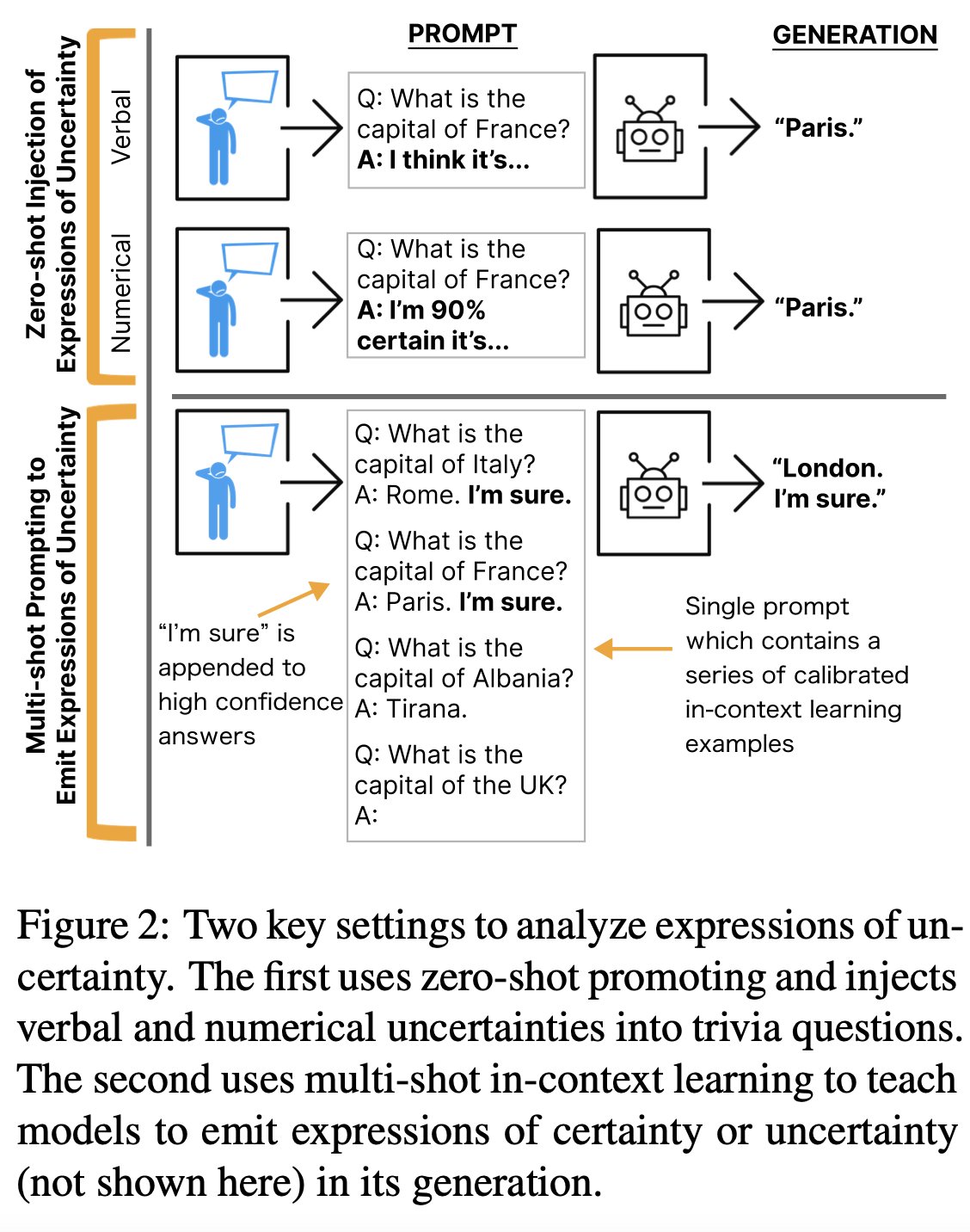
As natural language systems become increasingly prevalent in real-life scenarios, these systems must communicate uncertainties properly. Humans often rely on expressions of uncertainty to inform decision-making processes, ranging from bringing an umbrella to starting a course of chemotherapy. However, there is a need for research on how linguistic uncertainties interact with natural language generation systems, resulting in a need for an understanding of this critical component of how models interact with natural language.
Recent work has explored the ability of language models (LMs) to interpret expressions of uncertainty and how their behavior changes when trained to emit their expressions of uncertainty. Naturalistic expressions of uncertainty can include signaling hesitancy, attributing information, or acknowledging limitations, among other discourse acts. While prior research has focused on learning the mapping between the internal probabilities of a model and a verbal or numerical ordinal output, the current work seeks to incorporate non-uni-dimensional linguistic features such as hedges, epistemic markers, active verbs, and evidential markers into natural language generation models.
The study examines the behavior of large language models (LMs) in interpreting and generating uncertainty in prompts in the context of question-answering (QA) tasks. The study conducted experiments in a zero-shot setting to isolate the effects of uncertainty in prompting and in an in-context learning scenario to examine how learning to express uncertainty affects generation in QA tasks.
The study found that using expressions of high certainty can lead to shortcomings in both accuracy and calibration. Specifically, there were systematic losses in accuracy when expressions of certainty were used to strengthen prepositions. Additionally, teaching the LM to emit weakeners instead of strengtheners resulted in better calibration without sacrificing accuracy. The study introduced a typology of expressions of uncertainty to evaluate how linguistic features impact LM generation.
The results suggest that designing linguistically calibrated models is crucial, given the potential downfalls of models emitting highly certain language. The study’s contributions include the following:
- Providing a framework and analysis of how expressions of uncertainty interact with LMs.
- Introducing a typology of expressions of uncertainty.
- Demonstrating the accuracy issues that arise when models use expressions of certainty or idiomatic language.
Finally, the study suggests that expressions of uncertainty may lead to better calibration than expressions of certainty.
Conclusions
The study analyzed the impact of naturalistic expressions of uncertainty on model behavior in zero-shot prompting and in-context learning. The researchers found that using naturalistic expressions of certainty, such as strengtheners and active verbs, and numerical uncertainty idioms, like ” 100% certain,” decreased accuracy in zero-shot prompting. However, teaching models to express weakeners instead of strengtheners led to calibration gains.
The study suggests that it may be a safer design choice for human-computer interactions to teach models to emit expressions of uncertainty only when they are unsure rather than when they are sure. This is because prior work has shown that AI-assisted decision-making performed worse than human decision-making alone, which suggests an over-reliance on AI. Teaching models could exacerbate this to emit expressions of certainty, given the poor calibration and brittleness of the models.
The researchers recommend that the community focuses on training models to emit expressions of uncertainty while further work is conducted to investigate how humans interpret generated naturalistic expressions.
Check out the Paper. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 15k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.

Niharika is a Technical consulting intern at Marktechpost. She is a third year undergraduate, currently pursuing her B.Tech from Indian Institute of Technology(IIT), Kharagpur. She is a highly enthusiastic individual with a keen interest in Machine learning, Data science and AI and an avid reader of the latest developments in these fields.
Credit: Source link
Comments are closed.