A New AI Research Introduces A Novel Enhanced Prompting Framework for Text Generation
The natural language creation field is completely transformed by large language models (LLMs). Traditional fine-tuning approaches for responding to downstream tasks require access to the parameters of LLMs, which limits their use on potent black-box LLMs (like ChatGPT) that only give APIs. Because of this, recent research has focused heavily on prompting techniques that direct the generation results by offering many task-specific instructions and demonstrations, demonstrating that the prompt can considerably influence the resultant outcomes and thus necessitating careful design.
Although prompting is, in principle, a flexible method, the way it is typically used today is somewhat strict. But this isn’t the case with language learning; a person can enhance their language skills by receiving and responding to positive and negative feedback.
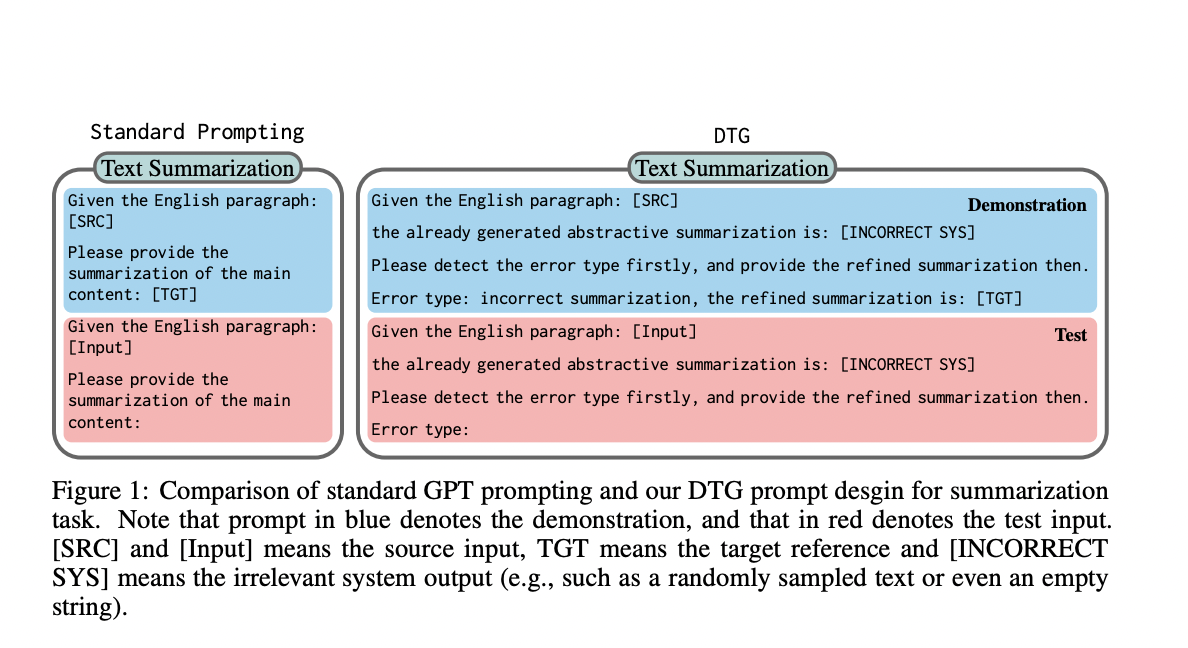
A new study by Northeastern University, China, Microsoft Research Asia, Microsoft Azure Translation, and NiuTrans Research invites the LLMs to reconsider and learn to spot any flaws in their output to determine if and how the deliberation capacity evolves. To facilitate error identification before generation, they design a new prompting template called Deliberate then Generate (DTG) that includes instructions and possible outputs.
Determining the candidate is an important part of the DTG design. Using data from a second baseline system is a simple option because its output is usually good quality and needs only small tweaks to be used effectively. Therefore, it is unable to promote effective deliberation. The researchers suggest using text unrelated to the source material, such as a random text selection or even a null string. DTG can be easily adapted to various text production jobs with only minor alterations in prompts since this method successfully triggers the deliberation ability of LLMs without resorting to other text generation systems to provide correction examples. From a psychological standpoint, this work is inspired by the canonical case for language acquisition, which considers negative evidence in developing linguistic competence.
The team carried out extensive experiments to show that the proposed DTG prompting reliably enhances model performance relative to traditional prompts on GPT3.5 (text-DaVinci-003) and GPT4. This is true across seven text generation tasks and more than 20 datasets. Machine translation, simplification, and commonsense creation are only some text generation tasks where GPT prompted by DTG achieves state-of-the-art performance with numerous datasets. The suggested DTG prompting does allow for deliberate ability and error avoidance before generation, as shown by extensive ablation studies and statistical error analysis.
The researchers plan on leveraging task-specific domain knowledge in future work to further improve the efficacy of DTG prompting.
Check Out The Paper. Don’t forget to join our 23k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more. If you have any questions regarding the above article or if we missed anything, feel free to email us at Asif@marktechpost.com
🚀 Check Out 100’s AI Tools in AI Tools Club
![]()
Tanushree Shenwai is a consulting intern at MarktechPost. She is currently pursuing her B.Tech from the Indian Institute of Technology(IIT), Bhubaneswar. She is a Data Science enthusiast and has a keen interest in the scope of application of artificial intelligence in various fields. She is passionate about exploring the new advancements in technologies and their real-life application.
Credit: Source link
Comments are closed.