A New AI Research Introduces Cluster-Branch-Train-Merge (CBTM): A Simple But Effective Method For Scaling Expert Language Models With Unsupervised Domain Discovery
Up to a trillion text tokens are used n the training of language models (LMs). This increases performance on several jobs but comes at a high cost because thousands of GPUs must be active once to update all parameters at each step. By splitting the total computation across several smaller expert language models (ELMs), each independently trained on a different subset (or domain) of the training corpus and then ensembled during inference, Branch-Train-Merge reduces this cost. BTM depends on document metadata to pinpoint domains, and this kind of oversight isn’t always accessible.
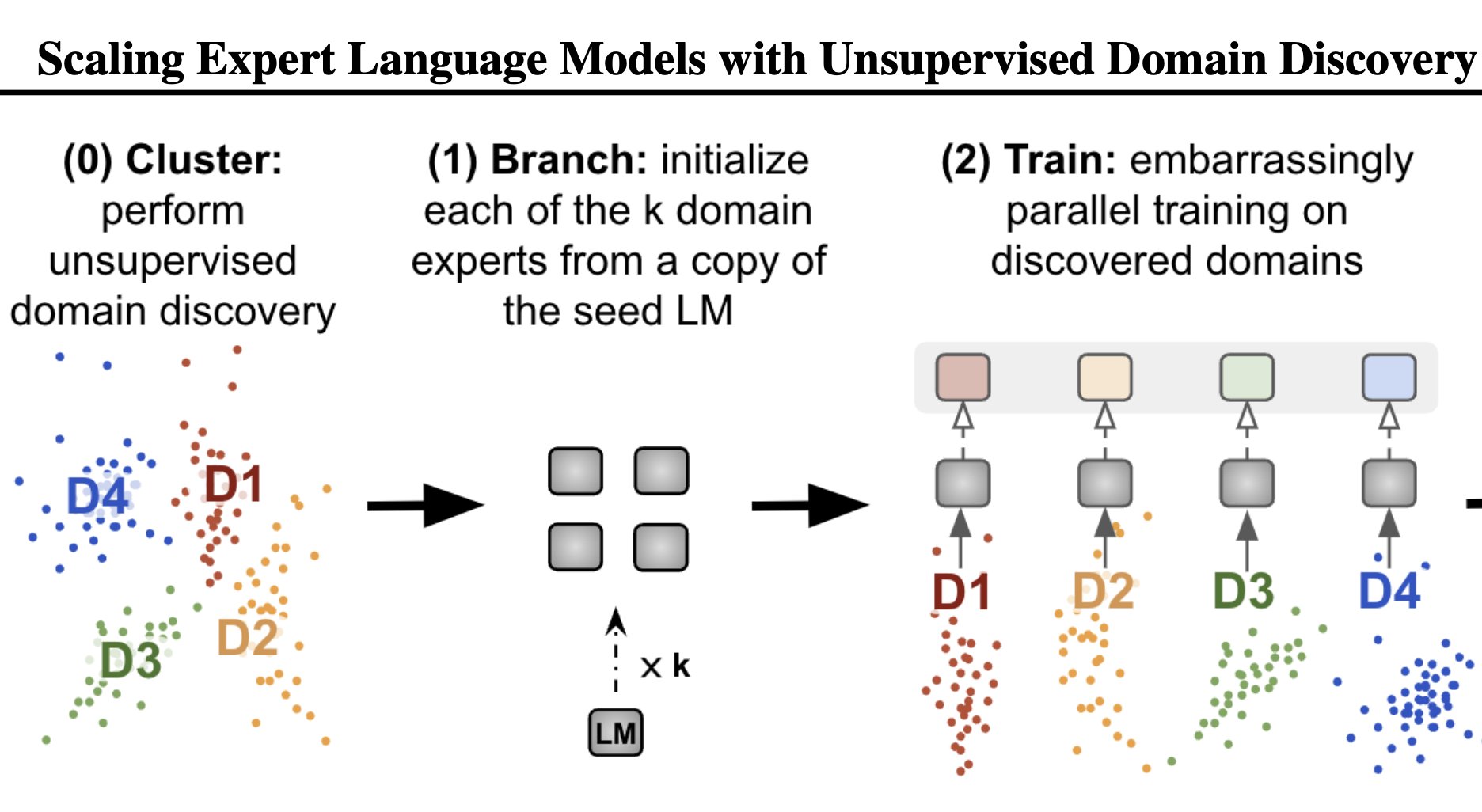
Moreover, as metadata cannot be readily combined or divided, the ideal number of metadata-based domains for a certain budget must be clarified. In this study, researchers from University of Washington, MetaAI and Allen institute for AI provide Cluster-Branch-Train-Merge (CBTM; see Figure 1), a metadata-free approach to scale LMs without extensive multi-node synchronization. They identify the domains in a corpus using unsupervised clustering and train an ELM on each cluster separately. At inference time, they sparsely activate a subset of the trained ELMs. They combine ELMs by giving their outputs a weight based on how far each expert’s cluster center is from an embedding of the present context.
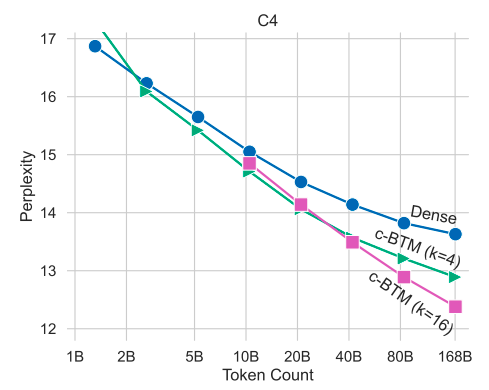
Figure 1: A corpus is divided into k clusters using C-BTM, which then trains an expert LM on each cluster before producing a sparse ensemble for inference. In the example above, C-BTM-trained LMs (with 4 or 16 clusters) achieve lower validation perplexity than dense LMs that were compute-matched. These LMs are initially trained on OPT-1.3B and then C4. With more training data, the ideal cluster count for C-BTM and its performance benefits rise (shown in log-scale)
This makes sparse computing easy and effective by getting just the top-k experts when forecasting each new token. As C-data BTM’s clusters are automatically learned without being limited by the metadata that is currently accessible, it generalizes BTM by enabling fine-grained control over the number and size of data clusters. They explore the scaling characteristics of C-BTM as a function of the number of trained experts using this new capacity while controlling for several variables. Many studies have demonstrated that introducing more clusters yields better validation perplexity than training single cluster (i.e., dense) models and that the ideal cluster count rises as compute is more powerful.
These outcomes hold for parameter experts with 1.3B and 6.7B estimates. They may aggressively parallelize expert training with additional clusters; for instance, they train 128 ELMs (168B parameters total) on 168B text tokens at once using just 8 GPUs. This allows us to avoid many practical issues with simultaneously training several big LMs over multiple nodes. Moreover, even as the number of experts increases, the number of parameters at inference time may remain constant: utilizing only the top-2 or top-4 experts is equivalent to employing all experts while using just the top-1 expert still beats the dense model.
The C-BTM technique for sparse modeling drastically reduces communication overhead compared to previous light LM systems. More clusters are trained more quickly than bigger dense models are. For example it is shown that training numerous 1.3B expert LMs and sparsifying them to a 5.2B parameter LM achieves the same perplexity as a 6.7B dense model with just 29% as many training FLOPs. Similar improvements are shown in few-shot text classification studies, demonstrating that C-BTM models perform better than thick baselines even when inference is substantially sparsified.
Different tokens are often routed to specialized parameters by existing sparse LMs. The communication costs of routing each token in each sparse tier, the difficulties in learning to specialize experts to tokens, and the need for different procedures to balance expert use may be why they have yet to gain widespread adoption. By employing offline balanced clustering rather than live load balancing to route sequences rather than tokens and with no common parameters between experts, C-BTM outperforms sparse LMs. They directly compare to an expert mixture model with top-2 routing.
According to their final study, balanced clustering is essential for C-BTM performance; it performs just as well as expert assignment with gold metadata and significantly beats random and unbalanced clustering baselines. Their research indicates that C-BTM is a practical and effective way to integrate big language models into enormous datasets. They publicly release their models and code on Github.
Check out the Paper and Github. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 16k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
Credit: Source link
Comments are closed.