A New AI Research Introduces Directional Stimulus Prompting (DSP): A New Prompting Framework to Better Guide the LLM in Generating the Desired Summary
Natural language processing (NLP) has seen a paradigm shift in recent years, with the advent of Large Language Models (LLMs) that outperform formerly relatively tiny Language Models (LMs) like GPT-2 and T5 Raffel et al. on a variety of NLP tasks. Prompting is the de facto method of using LLMs to perform various tasks by using natural language instructions in the context to steer the LLMs to produce desired outputs without parameter updates, in contrast to the conventional finetuning paradigm where the parameters of LMs can be updated for each downstream task.
While this prompting schema has allowed LLMs to perform quite well on various tasks in a zero-shot or few-shot environment, their performance on some specific downstream tasks still needs improvement and requires additional refinement, especially when training data is available. Nevertheless, because most LLMs only offer black-box inference APIs and are expensive to finetune, most users and academics cannot optimize these LLMs directly. Hence, a difficult topic that must be solved is how to effectively enhance LLMs’ performance on certain downstream tasks, sometimes with limited training instances. A new study from the University of California, Santa Barbara, and Microsoft proposes the Directional Stimulus Prompting (DSP) architecture that enhances the frozen black-box LLM on downstream tasks using a tiny tuneable LM (RL).

To be more precise, for each input text, a tiny LM (called a policy LM) learns to provide a series of discrete tokens as a directed stimulus, which might offer certain information or instruction on the input sample instead of a generic cue for the job. To direct the LLM’s creation towards the desired aim, such as greater performance measure scores, the created stimulus is then blended with the original input and supplied into the LLM. They initially use supervised finetuning (SFT) with a pre-trained LM utilizing a small number of gathered training samples. The training aims to maximize reward, defined as the scores on the downstream performance measures of the LLM generation dependent on the stimulus produced by the policy LM. After additional optimization to explore better stimuli, the refined LM initializes the policy LM in RL.
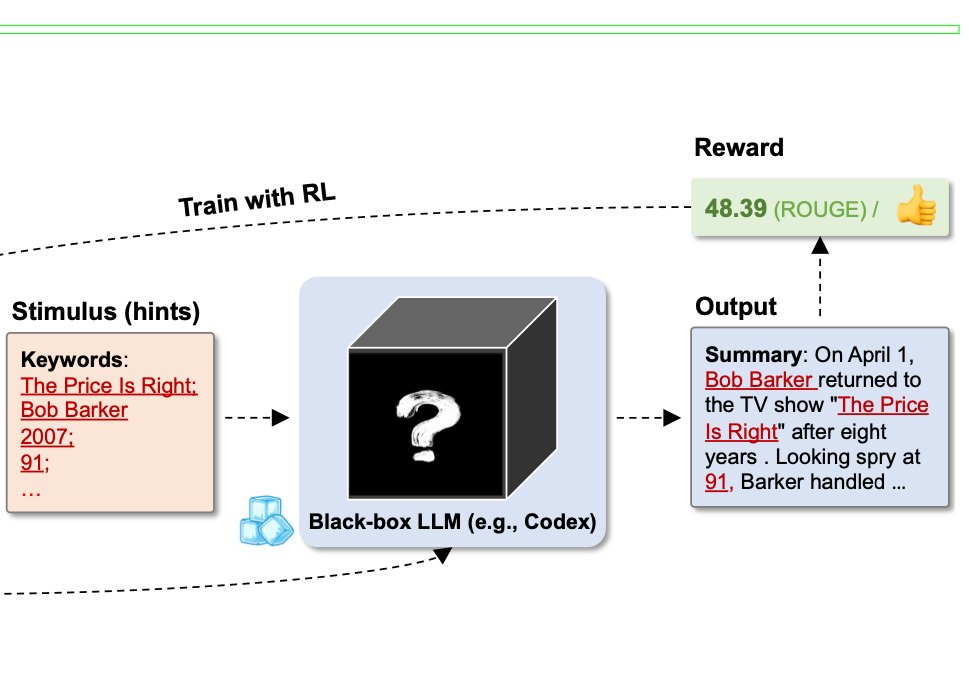
Figure 1 depicts a sample of the summarising job. To help the LLM produce the required summary based on the keywords, keywords act as the stimulus (hints). The policy LM may be optimized by using evaluation metric scores like ROUGE as the incentive, incentivizing it to provide keywords that direct the LLM to produce better summaries. While LLMs have excellent generation skills, they frequently display unwanted behaviors, necessitating fine-grained guidance on the intended generation characteristic and direction for certain downstream tasks. This is the foundation of their proposed approach. The tiny policy LM can produce a series of tokens as a directed stimulus to give the LLM sample-wise fine-grained guidance toward the intended aim but cannot produce texts that resemble human speech.
RL offers a natural solution to bridge the gap between the optimized object (e.g., the small policy LM that generates stimulus) and the optimization objective defined by the LLM generation, unlike prior studies that find optimal prompts via prompt engineering/optimization, which is trying to explain the “question” more clearly. Their approach attempts to provide “hints” or “cues” for each “question.” It also differs from chain-of-though prompting that encourages the LLM to generate intermediate reasoning steps when solving reasoning tasks. Their approach uses a small tuneable model to control and guide the LLM and targets the generation tasks where there is not only one correct “answer.” They evaluate their framework on summarization and dialogue response generation tasks.
The tiny policy LM that creates stimulation, for example, is an optimized object, but the production of the LLM determines the optimization goal. RL provides a simple way to bridge this gap. Unlike earlier investigations, this one tries to clarify the “question” by using prompt engineering or optimization. Their strategy makes an effort to offer “hints” or “cues” for each “question.” Also, it differs from chain-of-thought prompting, which encourages the Mind to produce intermediate steps of reasoning on its own while completing tasks requiring logic. Their method targets the generating jobs with more than one valid “response” and employs a simple tuneable model to regulate and direct the LLM. For assignments requiring the development of discussion responses and summaries, they assess their framework. They do tests using the 750M Flan-T5-large to establish the policy LM and the 175B Codex as the LLM. According to test results, when Codex depends on the indications produced by the tweaked T5, its performance on downstream tasks increases noticeably. Keywords that the summary should contain are employed as directing stimuli for the summarising job. Codex’s performance may already be enhanced by 7.2% using T5, which was trained using 2,000 samples from the CNN/Daily Mail dataset.
To develop conversation acts that specify the intended meaning behind target replies for 500 dialogues from the MultiWOZ dataset, they train the policy LM. Codex’s performance increased by 52.5% in total scores thanks to the dialogue actions produced by the policy LM. It performs as well as or better than earlier systems trained with complete training data (8438 dialogues).
Check out the Paper. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 14k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
Credit: Source link
Comments are closed.