A New AI Research Introduces EXPHORMER: A Framework For Scaling Graph Transformers While Slashing Costs
Graph transformers are a type of machine learning algorithm that operates on graph-structured data. Graphs are mathematical structures composed of nodes and edges, where nodes represent entities and edges represent relationships between those entities.
Graph transformers are used in various applications, including natural language processing, social network analysis, and computer vision. They are typically used for node classification, link prediction, and graph clustering tasks.
One popular type of graph transformer is the Graph Convolutional Network (GCN), which applies convolutional filters to a graph to extract features from nodes and edges. Other types of graph transformers include Graph Attention Networks (GATs), Graph Isomorphism Networks (GINs), and Graph Neural Networks (GNNs).
Graph transformers have shown great promise in machine learning, particularly for graph-structured data tasks.
Graph transformers have shown promise in various graph learning and representation tasks. However, scaling them to larger graphs while maintaining competitive accuracy with message-passing networks remains challenging. To address this issue, a new framework called EXPHORMER has been introduced by a group of researchers from the University of British Columbia, Google Research and the Alberta Machine Intelligence Institute. This framework utilizes a sparse attention mechanism based on virtual global nodes and expander graphs, which possess desirable mathematical characteristics such as spectral expansion, sparsity, and pseudorandomness. As a result, EXPHORMER enables the building of powerful and scalable graph transformers with complexity linear to the size of the graph while also providing theoretical properties of the resulting models. Incorporating EXPHORMER into GraphGPS yields models with competitive empirical results on various graph datasets, including three state-of-the-art datasets. Moreover, EXPHORMER can handle larger graphs than previous graph transformer architectures.
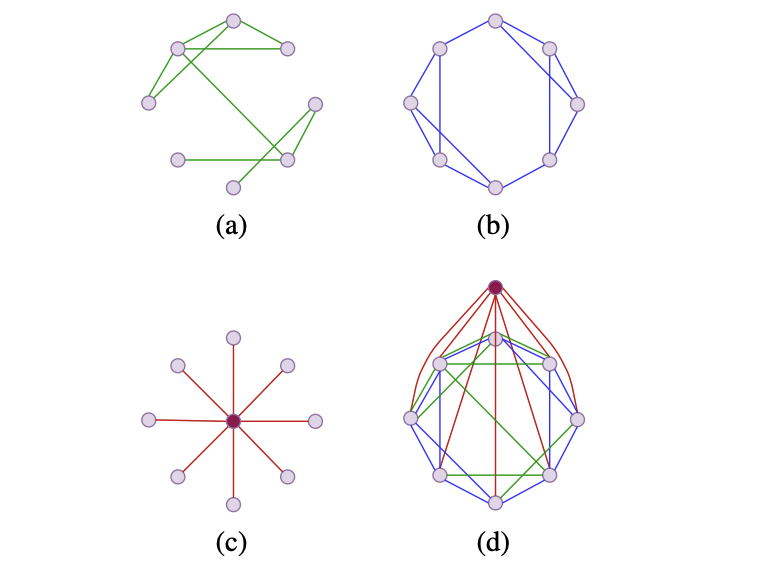
Exphormer is a method that applies an expander-based sparse attention mechanism to Graph Transformers (GTs). It constructs an interaction graph using three main components: Expander graph attention, Global attention, and Local neighborhood attention. The Expander graph attention allows information propagation between nodes without connecting all pairs of nodes. Global attention adds virtual nodes to create a global “storage sink” and provides universal approximator functions for full transformers. Local neighborhood attention models local interactions to obtain information about connectivity.
Their empirical study evaluated the Exphormer method on graph and node prediction tasks. The team found that Exphormer combined with message-passing neural networks (MPNN) in the GraphGPS framework achieved state-of-the-art results on several benchmark datasets. Despite having fewer parameters, it surpassed all sparse attention mechanisms and remained competitive with dense transformers.
The team’s main contributions involve proposing sparse attention mechanisms with linear computational costs in the number of nodes and edges, introducing Exphormer, which combines two techniques for creating sparse overlay graphs and introducing expander graphs as a powerful primitive in designing scalable graph transformer architectures. They were able to demonstrate that Exphormer, which combines expander graphs with global nodes and local neighborhoods, spectrally approximates the full attention mechanism with only a small number of layers and has universal approximation properties. The proposed Exphormer is based on and inherits the desirable properties of the GraphGPS modular framework, a recently introduced framework for building general, consequential, and scalable graph transformers with linear complexity. GraphGPS combines traditional local message passing and a global attention mechanism, allowing sparse attention mechanisms to improve performance and reduce computation costs.
Check out the Paper and Github. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 16k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.

Niharika is a Technical consulting intern at Marktechpost. She is a third year undergraduate, currently pursuing her B.Tech from Indian Institute of Technology(IIT), Kharagpur. She is a highly enthusiastic individual with a keen interest in Machine learning, Data science and AI and an avid reader of the latest developments in these fields.
Credit: Source link
Comments are closed.