A New AI Research Introduces Multitask Prompt Tuning (MPT) For Transfer Learning
Pretrained language models (PLMs) have significantly improved on many downstream NLP tasks due to finetuning. While current PLMs can include hundreds of millions of parameters, the traditional paradigm of full task-specific finetuning (FT) is challenging to expand to numerous tasks. The need to learn fewer parameters per task than necessary for comprehensive finetuning has led to a surge in research on “parameter-efficient” methods for model tuning.
For parameter-efficient transfer learning with PLMs, prompt tuning (PT) has recently emerged as a potential option. PT works by appending tunable continuous prompt vectors to the input before training. The PLM settings are locked in place, and PT learns only a limited number of prompt vectors for each task. Yet, there is still a significant gap between instantaneous tuning and complete finetuning despite their remarkable performance. This method is also highly sensitive to the initiation, necessitating longer training times than finetuning procedures typically.
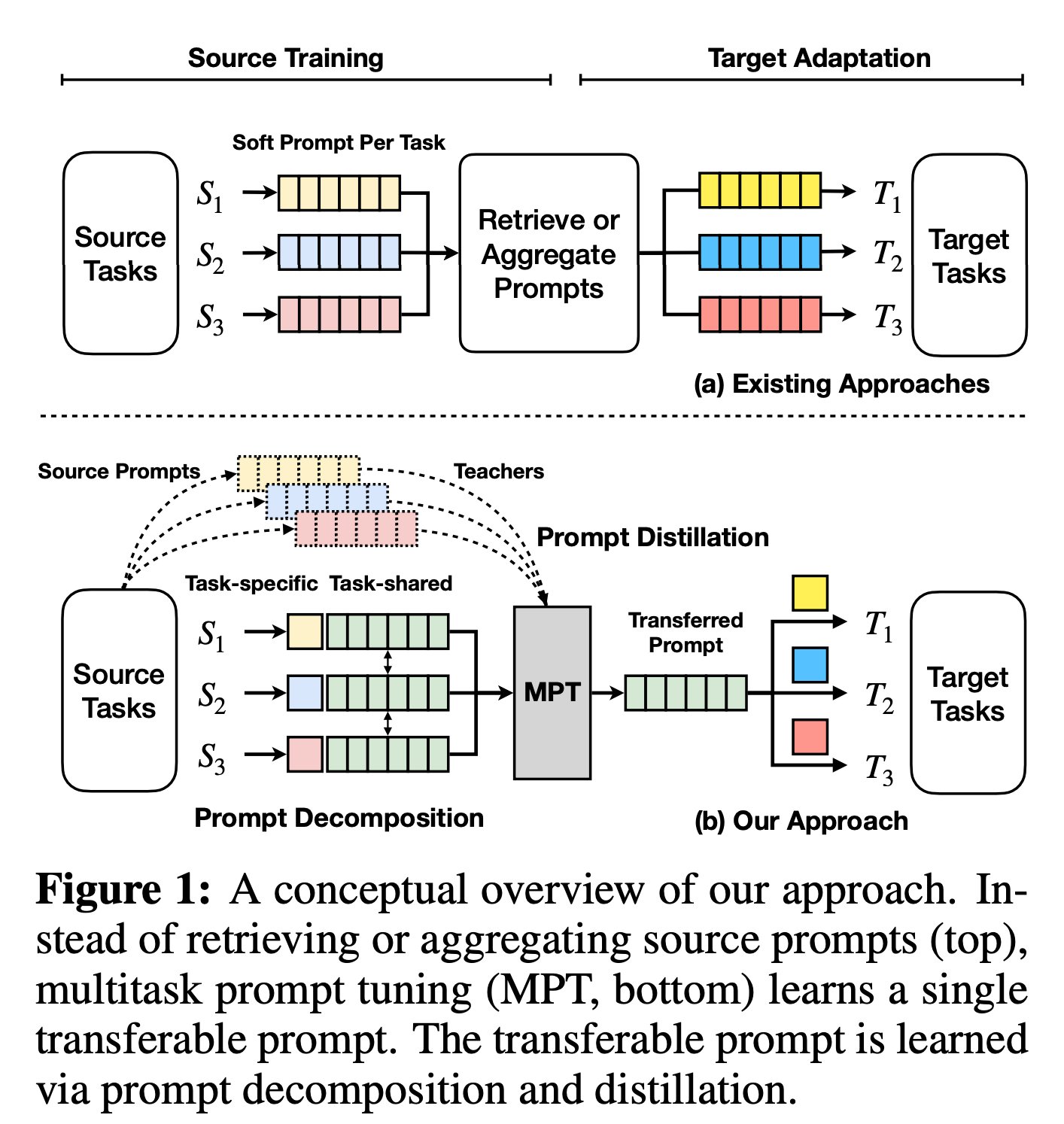
Recent studies have proposed to fix these problems by reusing prompt vectors from other jobs. These strategies begin by training soft prompts on various source tasks. They then use these pretrained prompts as a starting point for finetuning the prompt on a target task using a (possibly learned) similarity measure.
Researchers from the Ohio State University, MIT-IBM Watson AI Lab, and Massachusetts Institute of Technology further develop this line of research by introducing multitask prompt tuning (MPT), which utilizes multitask data to learn a single prompt that may be efficiently transmitted to target activities.
While the idea behind learning a shared prompt space is straightforward, in practice, it can be quite difficult to master. This is because it needs to acquire knowledge of the similarities between various source tasks while simultaneously reducing their interference. Instead of merely sharing the prompt matrix across all tasks, the researchers find that decomposing the soft prompt of each source task into a multiplication of a shared matrix and a low-rank task-specific matrix is more successful. Decomposition is taught by distilling information from gentle prompts acquired through consistent prompt tuning. They execute low-rank multiplicative modifications to the common prompt matrix to switch between jobs.
Comprehensive tests on 23 NLP datasets for various tasks show that the suggested methodology outperforms state-of-the-art prompt transfer techniques. By tuning much fewer task-specific prompt parameters than the most competitive multitask prompt transfer baseline, MPT with T5-Base achieves a 16.3% improvement over the vanilla prompt tuning baseline on the SuperGLUE benchmark. Certain performance metrics show that MPT outperforms full finetuning, despite using only 0.035 percent configurable parameters per job. With 4-32 labels per target task, the team also find that MPT is quite successful for few-shot learning.
Check out the Paper. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 15k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Tanushree Shenwai is a consulting intern at MarktechPost. She is currently pursuing her B.Tech from the Indian Institute of Technology(IIT), Bhubaneswar. She is a Data Science enthusiast and has a keen interest in the scope of application of artificial intelligence in various fields. She is passionate about exploring the new advancements in technologies and their real-life application.
Credit: Source link
Comments are closed.