A New AI Research Propose ‘UniFormer’ (Unified transFormer) to Unify Convolution and Self-Attention for Visual Recognition

For visual recognition, representation learning is a crucial research area. Essentially, researchers are confronted with two separate issues in visual data, such as photographs and movies. On the one hand, there is a great deal of local redundancy; for example, visual material in a particular region (space, time, or space-time) is often comparable. Inefficient computation is frequently introduced by such localization. Global reliance, on the other hand, is complex; for example, objectives in various regions have dynamic relationships. Such long-distance communication frequently results in inefficient learning.
To address these issues, academics have proposed many effective visual recognition models. Convolution Neural Networks (CNNs) and Vision Transformers (ViTs) are two popular backbones, with convolution and self-attention as fundamental processes in these two architectures. Regrettably, each of these operations focuses on one of the aforementioned issues while disregarding the other.
By aggregating each pixel with context from a tiny neighborhood (e.g., 3×3 or 3x3x3), the convolution technique, for example, is good at eliminating local redundancy and avoiding wasteful computation. Convolution, on the other hand, struggles to learn global reliance due to its narrow receptive area.
Self-attention, on the other hand, has recently been highlighted in the ViTs. It has a great capacity for learning global dependency in both photos and videos by comparing visual tokens for similarity. Despite this, ViTs are inefficient at encoding local features in shallow layers.
In the superficial layer, both ViTs acquire fine visual details, but spatial and temporal attention is redundant. Given an anchor token, it’s easy to observe how spatial attention focuses on tokens in the immediate vicinity and ignores the remainder of the image’s tokens. Similarly, temporal attention concentrates on the tokens in the adjacent frames, ignoring the tokens in the distant frames.
Such local emphasis, on the other hand, is achieved through a global comparison of all tokens in space and time. Clearly, this duplicated attention method imposes a significant and unnecessary computational strain on ViTs, degrading the computation-accuracy balance.
In a recent paper, researchers from UCAS Shanghai suggest a unique Unified transFormer (UniFormer) based on these talks. It combines convolution and self-attention in a compact transformer configuration that can deal with both local and global redundancy for effective and efficient visual identification.
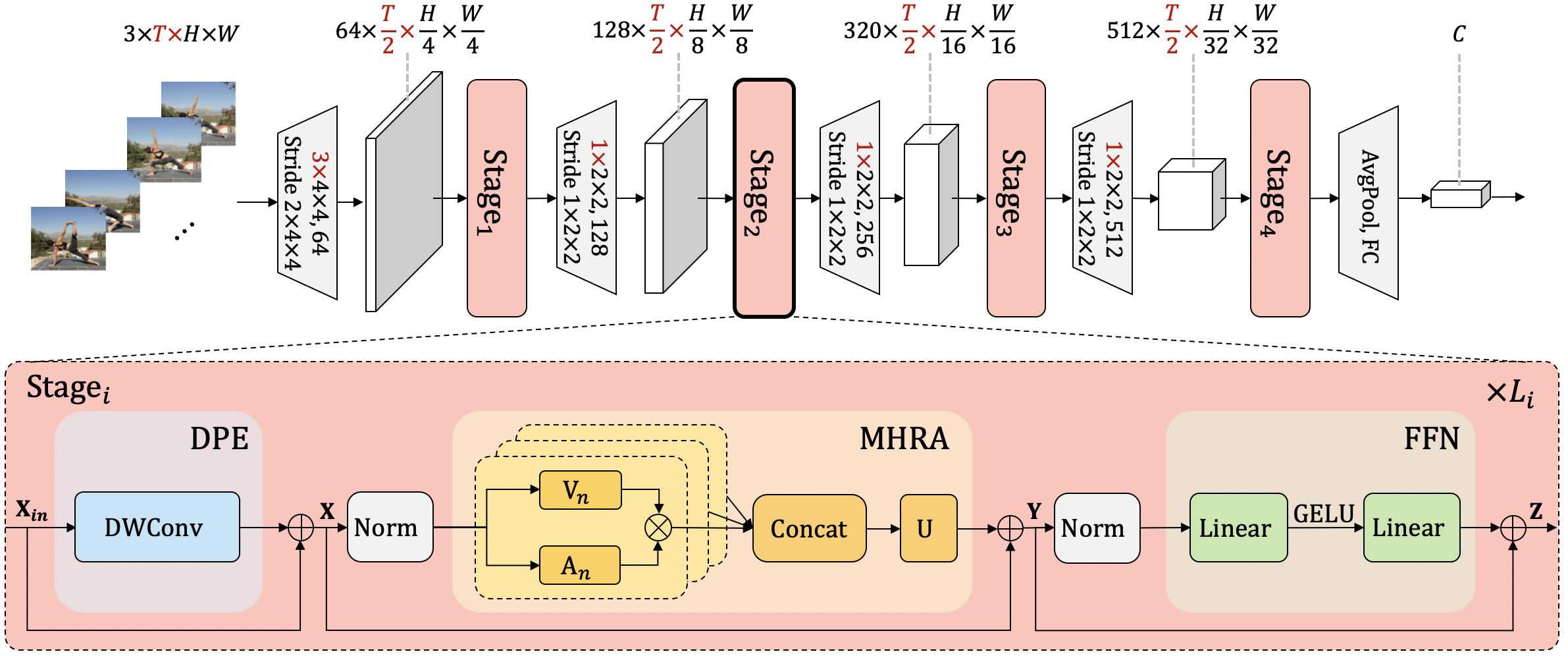
The UniFormer block, in particular, is made up of three main modules: Dynamic Position Embedding (DPE), Multi-Head Relation Aggregator (MHRA), and FeedForward Network (FFN). The fundamental distinction between the UniFormer and prior CNNs and ViTs is the relation aggregator’s unique architecture. The relation aggregator captures local token affinity with a tiny learnable parameter matrix in the shallow layers, inheriting the convolution style that can significantly minimize computation redundancy in the local region through context aggregation.
The relation aggregator learns global token affinity via token similarity comparison in the deep layers, inheriting the self-attention technique of learning long-range dependency from distant regions or frames. The team can flexibly integrate their cooperative power to increase representation learning by gradually stacking local and global UniFormer blocks in a hierarchical manner. Finally, they provide a broad and robust backbone for visual recognition, addressing a variety of downstream vision tasks with both simple and complex adaptation.
Extensive testing has shown that the UniFormer performs well in a variety of vision tasks, including image classification, video classification, object detection, semantic segmentation, and posture estimation.
To dynamically integrate position information into all tokens, the team initially introduces DPE. It accepts input resolutions of any size and makes effective use of token orders for enhanced visual identification. Then, using MHRA, they employ relation learning to enrich each token by utilizing its contextual tokens. The MHRA can cleverly merge convolution and self-attention to eliminate local redundancy and learn global dependency by flexibly creating token affinity in the shallow and deep layers.
The researchers present the Relation Aggregator (RA), which neatly unites convolution and self-attention as token relation learning. It may build local and global token affinity in the shallow and deep layers, respectively, to accomplish efficient and effective representation learning. MHRA, in particular, has a multi-head strategy to exploit token linkages.
The local UniFormer block, unlike the MobileNet block, is designed as a generic transformer format, containing, in addition to MHRA, dynamical position encoding (DPE), and feedforward network (FFN). This one-of-a-kind integration can significantly improve token representation, something that hasn’t been addressed in earlier convolution blocks.
The entire model can attain a preferred computation-accuracy balance because the local UniFormer block considerably saves computation of token comparison in the shallow levels. Second, instead of using absolute position embedding in the UniFormer, the team uses dynamic position embedding (DPE). It uses a convolutional algorithm to overcome permutation invariance and adapt to diverse visual token input lengths.
The team first creates a set of visual backbones for image classification by stacking the local and global UniFormer blocks hierarchically while keeping the computation-accuracy balance in mind. The backbones, as mentioned earlier, are then extended to handle other common vision tasks, such as video categorization and dense prediction (i.e., object detection, semantic segmentation, and human pose estimation). The UniFormer’s generality and flexibility indicate its usefulness in computer vision research and beyond.
The team conducts extensive experiments on ImageNet-1K image classification, Kinetics-400 and SomethingSomething V1&V2 video classification, COCO object detection, instance segmentation and pose estimation, and ADE20K semantic segmentation to verify the efficiency and effectiveness of our UniFormer for visual recognition. They also conduct detailed ablation research to examine each UniFormer design.
UniFormer-L obtains 86.3 top-1 accuracies on ImageNet-1K without any additional training data. UniFormer-B also achieves 82.9/84.8 top-1 accuracy on Kinetics400/Kinetics-600 with only ImageNet-1K pre-training, 60.9 and 71.2 top-1 accuracies on SomethingSomething V1&V2, 53.8 box AP and 46.4 mask AP on the COCO detection task, 50.8 mIoU on the ADE20K semantic segmentation task, and 77.4 AP on the COCO pose estimation task with only ImageNet-1K pre-training.
Conclusion
The authors suggest a revolutionary UniFormer for fast visual recognition in this paper, which efficiently unifies convolution and self-attention in a concise transformer format to eliminate redundancy and dependency. Local MHRA is used in shallow layers to reduce computing load, whereas global MHRA is used in deeper levels to learn global token relations. Extensive testing has demonstrated the UniFormer’s remarkable modeling capabilities. The UniFormer achieves state-of-the-art outcomes on a broad range of vision tasks with less training expense thanks to easy yet effective adaptation.
Paper: https://arxiv.org/pdf/2201.09450v1.pdf
Github: https://github.com/sense-x/uniformer
Suggested
Credit: Source link
Comments are closed.