A New AI Research Proposes A Novel Approach To Compact And Optimal Deep Learning By Decoupling Model DoF And Model Parameters
In deep learning, large models with millions of parameters have shown remarkable accuracy in various applications such as image recognition, natural language processing, and speech recognition. However, training and deploying these models can be computationally expensive and require significant memory resources. This has led to a growing need for more efficient deep learning models that can be trained and deployed on resource-constrained devices such as smartphones, embedded systems, and Internet of Things (IoT) devices. Additionally, reducing computational and memory requirements can also help reduce the environmental impact of deep learning by lowering energy consumption and carbon footprint. Therefore, there is a need for new techniques and approaches to reduce the computational and memory requirements of deep learning models while maintaining or even improving accuracy.
Various attempts have been made to reduce large models’ computational and memory requirements while maintaining accuracy. One common approach is to use model compression techniques, such as pruning or quantization, to reduce the number of parameters in a model. Another method is to use low-rank approximations to reduce the memory footprint of a model. However, these approaches often require extensive training and optimization procedures, and the resulting models may still be computationally expensive.
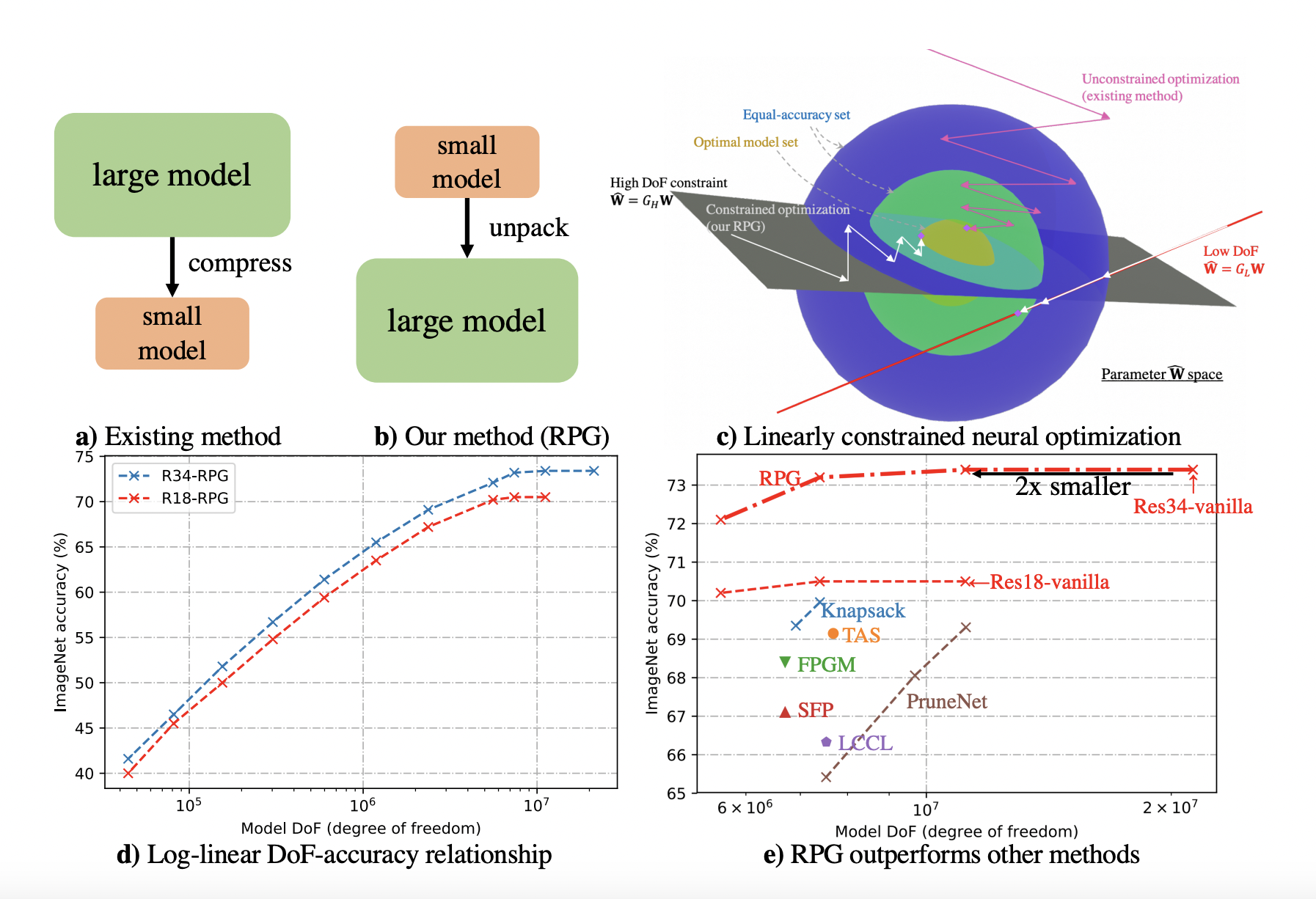
Recently, a research team from the USA proposed a new method that takes a different approach by decoupling the Degrees of Freedom (DoF) and the actual number of parameters in a model. This allows for a more flexible optimization process and can potentially result in accurate and computationally efficient models.
To achieve this, the researchers create a recurrent parameter generator (RPG) that repeatedly fetches parameters from a ring and unpacks them onto a large model with random permutation and sign flipping to promote parameter decorrelation. The RPG operates in a one-stage end-to-end learning process, allowing gradient descent to find the best model under constraints with faster convergence.
The researchers found a log-linear relationship between model DoF and accuracy, which means that reducing the number of DoF required for a deep learning model does not necessarily result in a loss of accuracy. Instead, at a sufficiently large DoF, the RPG eliminates redundancy and often finds a model with little loss in accuracy.
Furthermore, the RPG achieves the same ImageNet accuracy with half of the ResNet-vanilla DoF and outperforms other state-of-the-art compression approaches. The RPG can be further pruned and quantized for additional run-time performance gain.
Overall, the proposed method presents a significant potential for efficient and practical deployment of deep learning models by reducing the number of DoF required without sacrificing accuracy.
To gauge how well the suggested strategy works, a series of experiments were conducted to measure its effectiveness in improving the system’s overall performance. The results show that the ResNet-RPG optimizes in a parameter subspace with fewer degrees of freedom than the vanilla model, leading to a faster convergence rate. ResNet-RPG outperforms state-of-the-art compression methods on ImageNet while achieving lower gaps between training and validation sets, indicating less overfitting. Additionally, ResNet-RPG has higher out-of-distribution performance even with smaller model degrees of freedom. The storage space of the ResNet-RPG model file is significantly reduced, with a save file size of only 23MB (49% reduction) with no accuracy loss and 9.5MB (79% reduction) with only a two percentage point accuracy loss. Moreover, ResNet-RPG models can be quantized for further size reduction without a significant accuracy drop. The proposed method also provides a security advantage by using permutation matrices generated by the random seed as security keys.
In summary, the proposed approach of decoupling Degrees of Freedom and the actual number of parameters in a model through a recurrent parameter generator (RPG) presents a significant potential for efficient and practical deployment of deep learning models. The experiments show that the RPG outperforms state-of-the-art compression methods, achieving lower gaps between training and validation sets, less overfitting, higher out-of-distribution performance, and a significantly reduced model file size. Overall, the RPG provides a more flexible optimization process and faster convergence rate, allowing for accurate and computationally efficient models that can be trained and deployed on resource-constrained devices.
Check out the Paper. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 15k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Mahmoud is a PhD researcher in machine learning. He also holds a
bachelor’s degree in physical science and a master’s degree in
telecommunications and networking systems. His current areas of
research concern computer vision, stock market prediction and deep
learning. He produced several scientific articles about person re-
identification and the study of the robustness and stability of deep
networks.
Credit: Source link
Comments are closed.