A New AI Research Proposes A Simple Yet Effective Structure-Based Encoder For Protein Representation Learning According To Their 3D Structures
Proteins, the energy of the cell, are involved in various applications, including material and treatments. They are made up of an amino acid chain that folds into a certain shape. A significant number of novel protein sequences have been found recently due to the development of low-cost sequencing technology. Accurate and effective in silico protein function annotation methods are required to close the current sequence-function gap since functional annotation of a novel protein sequence is still expensive and time-consuming.
Many data-driven approaches rely on learning representations of the protein structures because many protein functions are controlled by how they are folded. These representations can then be applied to tasks like protein design, structure classification, model quality assessment, and function prediction.
The number of published protein structures is orders of magnitude less than the number of datasets in other machine-learning application fields due to the difficulty of experimental protein structure identification. For instance, the Protein Data Bank has 182K experimentally confirmed structures, compared to 47M protein sequences in Pfam and 10M annotated pictures in ImageNet. Several studies have used the abundance of unlabeled protein sequence data to develop a proper representation of existing proteins to close this representational gap. Many researchers have used self-supervised learning to pretrain protein encoders on millions of sequences.
Recent developments in accurate deep learning-based protein structure prediction techniques have made it feasible to effectively and confidently predict the structures of many protein sequences. Nevertheless, these techniques do not specifically capture or use the information about protein structure that is known to determine how proteins function. Many structure-based protein encoders have been proposed to use structural information better. Unfortunately, the interactions between edges, which are crucial in simulating protein structure, have yet to be explicitly addressed in these models. Moreover, due to the dearth of experimentally established protein structures, relatively little work has been done up until recently to create pretraining techniques that take advantage of unlabeled 3D structures.
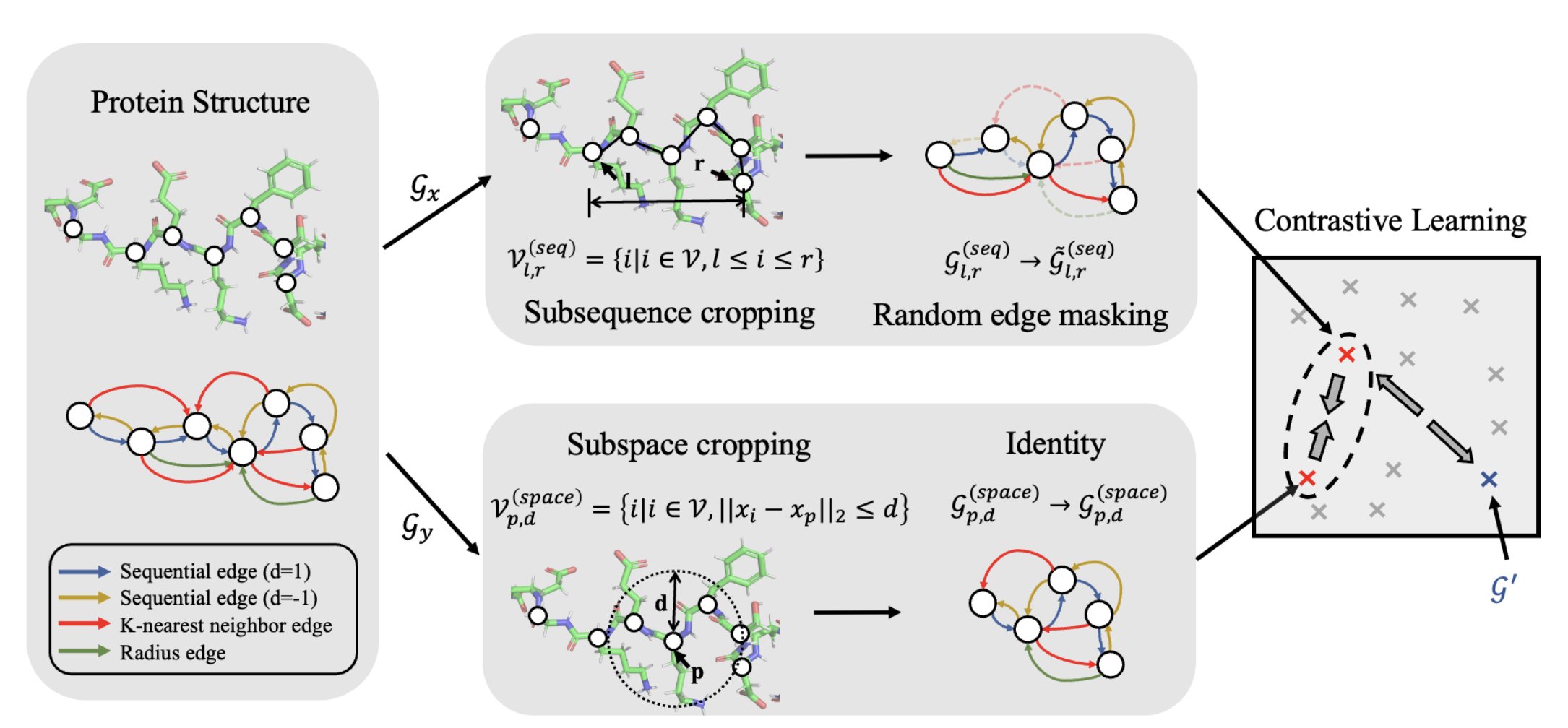
Inspired by this advancement, they create a protein encoder that can be applied to a range of property prediction applications and is pretrained on the most feasible protein structures. They suggest a straightforward yet efficient structure-based encoder termed the GeomEtry-Aware Relational Graph Neural Network, which conducts relational message passing on protein residue graphs after encoding spatial information by including various structural or sequential edges. They suggest a sparse edge message passing technique to improve the protein structure encoder, which is the first effort to implement edge-level message passing on GNNs for protein structure encoding. Their idea was inspired by the design of the triangle attention in Evoformer.
They also provide a geometric pretraining approach based on the well-known contrastive learning framework to learn the protein structure encoder. They suggest innovative augmentation functions that enhance the similarity between acquired representations of substructures from the same protein while decreasing that between those from different proteins to find physiologically linked protein substructures that co-occur in proteins. They simultaneously suggest a set of simple baselines based on self-prediction.
They established a strong foundation for pretraining protein structure representations by comparing their pretraining methods against several downstream property prediction tasks. These pretraining problems include the masked prediction of various geometric or physicochemical properties, such as residue kinds, Euclidean distances, and dihedral angles. Numerous tests using a variety of benchmarks, such as Enzyme Commission number prediction, Gene Ontology term prediction, fold’classification, and reaction classification, show that GearNet enhanced with edge message passing can consistently outperform existing protein encoders on the majority of tasks in a supervised environment.
Moreover, using the suggested pretraining strategy, their model trained on fewer than a million samples obtains results equivalent to or even better than those of the most advanced sequence-based encoders pretrained on datasets of a million or billion. The codebase is publicly available on Github. It is written in PyTorch and Torch Drug.
Check out the Paper and Github Link. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 14k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
Credit: Source link
Comments are closed.