A New AI Research Proposes an Effective Optimization Method of Adaptive Column-Wise Clipping (CowClip) that Reduces CTR Prediction Model Training Time from 12 Hours to 10 Minutes on 1 GPU
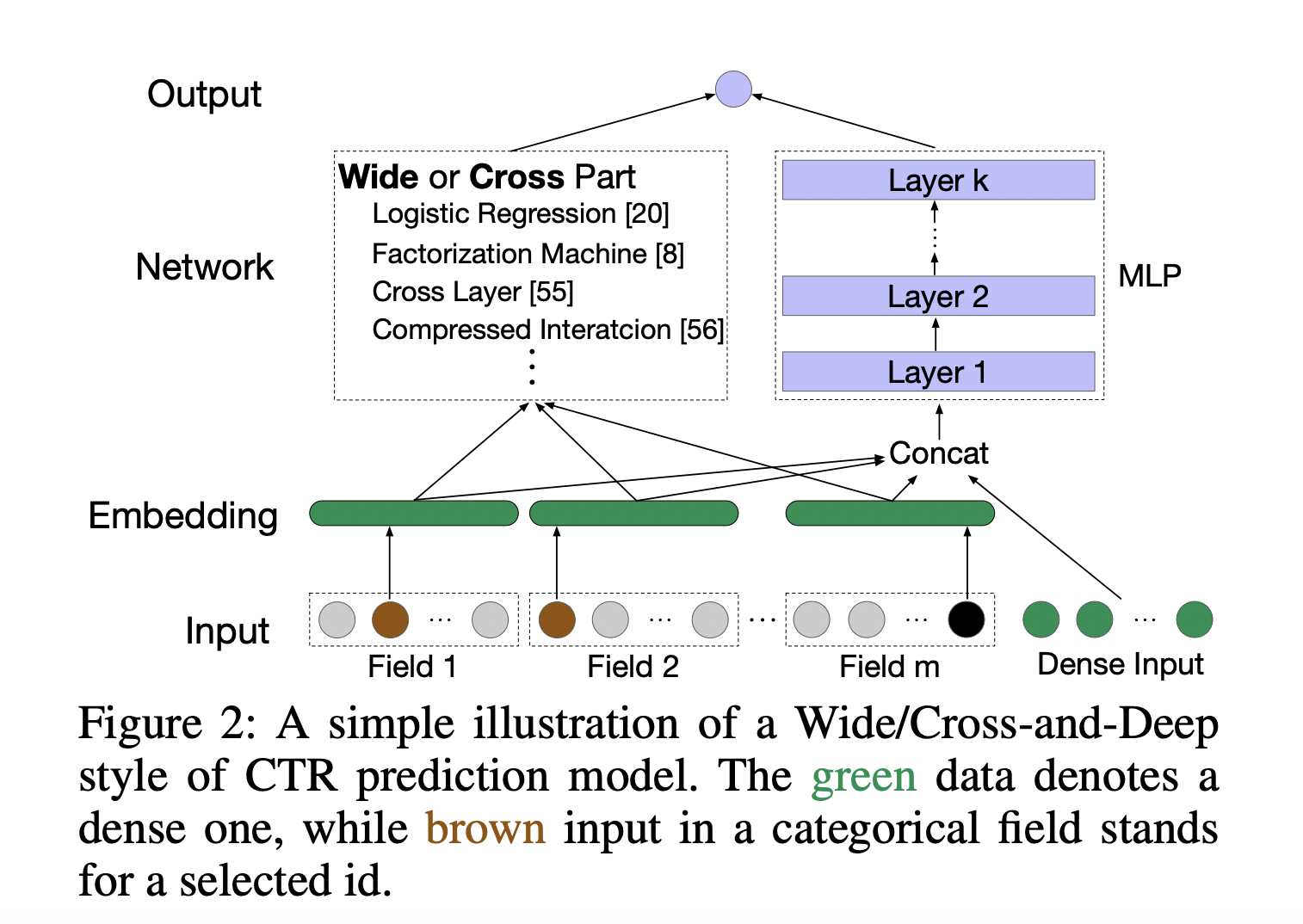
Online commerce, video applications, and web adverts see much clicking as the Internet, and the e-economy grow. The amount of click samples in a typical industrial dataset has reached hundreds of billions and is still growing daily. To determine whether a user would click on the suggested item, one can utilize clickthrough rate (CTR) prediction. It is an important job in the recommendation and advertising systems. The user experience and ad revenue may both be directly improved by an accurate CTR prediction. The goal of the clickthrough rate (CTR) prediction challenge is to foretell a user’s decision to click on the suggested item. It is an important job in the recommendation and advertising systems.
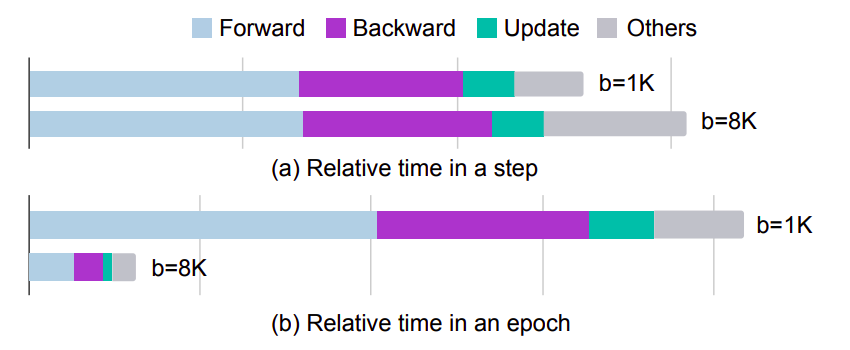
To keep an up-to-date CTR prediction model, reducing the time required for re-training on a large dataset is vital. This is because CTR prediction is a time-sensitive activity (e.g., recent subjects and new users’ hobbies). Additionally, cutting training time also lowers training costs, leading to a good return on investment, given a stable computing budget. In recent years, GPU processing power has grown quickly. Larger batch sizes can benefit more from the parallel processing capacity of GPUs as GPU memory and FLOPS increase. Figure 1(a) demonstrates that a single forward and backward pass takes virtually the same time when scaling eight times the batch size, indicating that GPUs with tiny batch sizes are extremely underutilized.
They concentrate on constructing an accuracy-preserving approach for increasing batch size on a single GPU, which can be readily expanded for multi-node training, to avoid deviating from system optimization in decreasing communication costs. Large batch training decreases the number of steps and, as a result, greatly reduces the overall training time because the number of training epochs stays constant (Figure 1(b)). In a multi-GPU environment, where gradients of the big embedding layer must be sent across several GPUs and computers, a large batch also benefits more due to the high communication costs involved.
Since CTR prediction is a very sensitive task and cannot tolerate accuracy loss, the issue of applying big batch training is an accuracy loss while naively increasing the batch size. In CV and NLP tasks, hyperparameter scaling rules and properly crafted optimization techniques are not ideally suited for CTR prediction. This is because the embedding layers dominate the parameters of the whole network in CTR prediction (e.g., 99.9%, see Table 1), and the inputs are more sparse and frequency-unbalanced. In this study, they explained why the CTR prediction scaling rules that had previously been used had failed and provided a successful algorithm and scaling control for large batch training.
Conclusion: To the best of their knowledge, they are the first to look at the stability of the training CTR prediction model in very large batch sizes. • With careful mathematical analysis, they demonstrate that the learning rate for uncommon features should not be scaled while increasing the batch size.
• They ascribe the difficulty in scaling the batch size to the disparity in id frequencies. With CowClip, they may increase the batch size with a simple and effective scaling technique.
• To stabilize the training process of the CTR prediction task, they provide an efficient optimization strategy called adaptable Column-wise Clipping (CowClip). They successfully scale up four models 128 times the batch size on two open datasets. On the Criteo dataset, they specifically train the DeepFM model with a 72-fold speedup and 0.1% AUC increase.
The whole project codebase is open sourced on GitHub.
Check out the Paper and Github. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 13k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
Credit: Source link
Comments are closed.